'분류 전체보기'에 해당되는 글 192건
- 2010.06.04 Service Broker::장점 1
- 2010.06.04 Service Broker::아키텍처
- 2010.06.04 Service Broker::소개
- 2010.06.04 복제::LOB DataType 제한
- 2010.06.04 복제::#5 구현&삭제 스크립트
- 2010.06.04 복제::머지복제에러
- 2010.06.04 복제::스냅숏 DB를 사용한 게시 초기화
- 2010.06.03 에러::SSIS 연결끊기는 현상 1
- 2010.06.03 에러::Agent 1
- 2010.06.03 에러::64bit 버퍼 풀 페이징
- 2010.06.03 에러::msdb 복원시 버전차이 1
- 2010.06.03 성능::ReadTrace 사용법
- 2010.06.03 SQL서버 성능카운터
- 2010.06.03 성능::엑셀이용분석하기
- 2010.06.03 T-SQL::Removing Duplication Data 1
장점
-
데이터베이스 통합
- 데이터, 메시지 및 응용 프로그램 논리가 모두 데이터베이스에 있으면 응용 프로그램의 관리(재해 복구, 보안, 백업 등)가 일상적인 데이터베이스 관리의 일부가 되고 관리자는 3-4개에 이르는 별도의 구성 요소를 관리할 필요가 없으므로 관리가 더욱 쉬워진다.
- Service Broker에서는 같은 데이터베이스에 메시지와 데이터를 저장하므로 불일치는 문제가 되지 않는다.
- Service Broker 서비스를 구현하는 저장 프로시저는 Transact-SQL 또는 CLR(공용 언어 런타임) 언어 중 하나로 작성할 수 있습니다. 데이터베이스 외부의 프로그램에서는 Transact-SQL 및 ADO.NET 같이 익숙한 데이터베이스 프로그래밍 인터페이스를 사용합니다.
-
메세지 순서 지정 및 조정
- 기존은 응용프로그램이 잘못된 순서로 도착하는 메세지의 순서를 지정하고 조정하는 작업 담당
- 기존 MSMQ 시스템에서는 메세지가 중복 배달되는 문제 발생
- Severice Broker는 메세지의 순서, 고유한 배달 및 대화 식별을 자동으로 처리함으로 이런 문제 해결, 끝점 사이에 대화가 설저되고 나면 응용 프로그램은 각 메세지를 보낸 순서대로 한 번씩만 메세지를 받는다.
-
느슨한 연결 및 작업 유연성
- 응용 프로그램에서는 큐에 메시지를 보낸 다음 계속하여 응용 프로그램 처리를 진행하되 Service Broker를 통해 메시지가 대상에 도착했는지 확인할 수 있다. 이처럼 연결이 느슨하면 유연한 일정 예약이 가능합니다.
-
관련 메세지 잠금
- 대화의 그룹 잠금을 통해 여러 스레드가 같은 큐에서 읽는 경우 메세지를 잘 못된 순서로 처리되지 않게 한다.
- 연관된 메세지의 경우 대화 그룹에서 관련된 대화를 연결하는 밥업을 사용하여 대화 그룹의 모든 메세지를 자동으로 잠그기 때문에 하나의 응용 프로그램 인스턴스에서만 수신하고 처리할 수 있다.
-
자동 활성화
- 활성화를 사용하면 응용 프로그램이 큐에 도착하는 메시지 볼륨에 맞게 크기를 동적으로 조정할 수 있다.
- Service Broker는 데이터베이스 내부에서 실행되는 프로그램과 데이터베이스 외부에서 실행되는 프로그램 모두에서 활성화를 활용하는 기능을 제공한다. 그러나 응용 프로그램이 활성화를 사용할 필요가 없다.
- Service Broker는 큐의 작업을 모니터링하여 사용 가능한 메시지가 있는 모든 대화에 대해 응용 프로그램이 메시지를 받는지 여부를 확인. Service Broker 활성화는 큐 판독기가 수행할 작업이 있을 때 새 큐 판독기를 시작합니다. 큐 판독기가 수행할 작업이 있는 시기를 확인하기 위해 Service Broker에서는 큐의 작업을 모니터링합니다.
- 큐 판독기의 수가 들어오는 트래픽에 일치할 경우 큐는 정기적으로 큐가 비어 있는 상태 또는 큐의 모든 메시지가 다른 큐 판독기에서 처리 중인 대화에 속하는 상태에 이르게 됩니다. 큐가 일정 기간 동안 이러한 상태에 이르지 않으면 Service Broker는 다른 응용 프로그램 인스턴스를 활성화합니다.
- Service Broker는 활성화를 통해 시작된 프로그램을 중지하지 않습니다. 대신 활성화된 응용 프로그램은 메시지가 도착하지 않은 일정 기간 이후 자동으로 종료되도록 작성됩니다. 이러한 방법으로 설계된 응용 프로그램을 사용함으로써 서비스에 대한 트래픽 변경으로 인해 여러 응용 프로그램 인스턴스가 동적으로 증가하고 감소할 수 있습니다. 또한 시스템이 종료되거나 다시 부팅되면 시스템을 다시 시작할 때 응용 프로그램에서 자동으로 큐의 메시지를 읽기 시작합니다.
사용용도
-
비동기 트리거
- OLTP 시스템과 같이 트리거를 대신해서 메세지를 보내면 메세지를 받는 쪽에서는 해당 작업을 수행하며 된다.
-
안정적인 쿼리 처리
- 정전, 오류등을 대비에서 서비스 브로커로 쿼리르 메세지로 보내서 처리할 수 있다. 컴퓨터가 복구되면 응용 프로그램이 다시 시작되고 메세지가 다시 처리된다.
- 클라이언트 응용 프로그램에 대한 서버쯕 분산 처리
- 클라이언트 응용 프로그램에 대한 데이터 통합
-
대량 일괄 처리
- 대량 일괄 처리를 수행해야 하는 응용 프로그램은 Service Broker에 제공되는 큐 및 병렬 처리 기능을 통해 많은 작업을 신속하고 효율적으로 처리할 수 있다.
이 글은 스프링노트에서 작성되었습니다.
'Service Broker' 카테고리의 다른 글
| Sesrvice Broker::보안 (0) | 2010.06.04 |
|---|---|
| Service Broker::아키텍처 (0) | 2010.06.04 |
| Service Broker::소개 (0) | 2010.06.04 |
Service Broker 응용 프로그램은 Service Broker 데이터베이스 개체와 이 개체를 사용하는 하나 이상의 응용 프로그램으로 이루어집니다
대화 구성 요소 - 대화의 런타임 구조입니다. 응용 프로그램은 메시지를 대화의 일부로 교환합니다.
서비스 정의 개체 - 응용 프로그램의 기본 디자인을 지정하는 디자인 타임 구성 요소입니다. 이 구성 요소는 응용 프로그램의 메시지 유형, 응응 프로그램의 대화 흐름 및 응용 프로그램의 데이터베이스 저장소를 정의합니다.
라우팅 및 보안 구성 요소 - 이 구성 요소는 SQL Server 인스턴스 외부의 메시지를 교환하기 위한 인프라를 정의합니다.
대화(conversaction) 아키텍처#
| 개체 | 정의 |
|---|---|
|
메시지 |
메시지는 서비스 간에 교환되는 데이터입니다. 각 메시지는 하나의 대화에 속하며 각각 특정한 메시지 유형을 갖고 있습니다. |
|
대화 기능 |
대화(Dialog)는 두 Service Broker 서비스 간의 양방향 대화(Conversation)입니다. Service Broker는 대화(Dialog)를 통해 EOIO(Exactly-Once-In-Order) 방식으로 메시지를 배달합니다. 각 대화(Dialog)는 하나의 대화(Conversation) 그룹에 속하며 특정 계약을 따릅니다. |
|
대화 그룹 |
대화 그룹은 서로 연동하여 같은 작업을 완료하는 대화를 식별합니다. Service Broker는 대화 그룹을 사용하여 메시지 잠금을 관리하므로 소프트웨어 개발자가 동시성을 관리하는 데 도움이 됩니다. 응용 프로그램 개발자는 상태 관리에 대한 도움을 얻을 때도 대화 그룹을 사용합니다. |
메세지#
메시지에는 메시지를 보내는 응용 프로그램에 따라 결정되는 특정 유형이 있습니다. 각 메시지에는 고유한 대화 ID와 함께 대화 내의 시퀀스 번호가 있습니다. 메시지를 받을 때 Service Broker는 메시지의 대화 ID와 시퀀스 번호를 사용하여 메시지를 순서대로 정렬합니다.
대화#
Service Broker가 보낸 모든 메시지는 대화의 일부입니다. 대화는 두 서비스 간의 통신입니다. 대화는 두 서비스 간의 안정적이고 지속적인 양방향 메시지 스트림입니다.
대화는 EOIO(Exactly-Once-In-Order) 방식으로 메시지 배달을 제공합니다. 대화는 각 메시지에 포함된 대화 식별자와 시퀀스 번호를 사용하여 관련된 메시지를 식별하고 올바른 순서로 메시지를 배달합니다. 대화는 두 서비스 간의 안정적이고 지속적인 메시지 스트림입니다.
대화에는 두 참가자가 있습니다. 시작자는 대화를 시작하고 대상은 시작자가 시작한 대화를 수락합니다. 대화에 대한 계약에 지정된 바와 같이 참가자가 대화를 시작하는지 여부에 따라 참가자가 보낼 수 있는 메시지가 결정됩니다.
.gif)
응용 프로그램은 메시지를 대화의 일부로 주고받습니다. SQL Server가 대화에 대한 메시지를 받으면 SQL Server는 대화에 대한 큐에 메시지를 넣습니다. 응용 프로그램은 큐에서 메시지를 받고 필요에 따라 메시지를 처리합니다. 처리 과정 중에 응용 프로그램이 메시지를 대화의 다른 참가자에게 보낼 수도 있습니다.
- 대화수명
- 대화 타이머
대화그룹#
대화 그룹이란 관련 대화의 그룹을 나타냅니다. 대화 그룹을 사용하면 응용 프로그램에서 특정 비즈니스 작업에 관련된 대화를 쉽게 조정할 수 있습니다.
모든 대화는 하나의 대화 그룹에 속합니다. 모든 대화 그룹은 특정 서비스와 관련되어 있으며 그룹의 모든 대화는 해당 서비스 간의 대화입니다. 대화 그룹에 포함할 수 있는 대화 수에는 제한이 없습니다.
SQL Server에서는 대화 그룹을 사용하여 특정 비즈니스 작업에 관련된 메시지에 대해 EOIO(Exactly-Once-In-Order) 방식으로 액세스를 제공합니다
응용 프로그램이 메시지를 보내거나 받을 때 SQL Server에서 메시지가 속한 대화 그룹을 잠급니다. 그러면 한 번에 한 세션만 대화 그룹의 메시지를 받을 수 있습니다. 대화 그룹을 잠그면 응용 프로그램이 각 대화 그룹의 메시지가 EOIO 방식으로 처리됩니다. 대화 그룹에 둘 이상의 대화를 포함할 수 있으므로 응용 프로그램에서는 대화 그룹을 사용하여 같은 비즈니스 작업에 관련된 메시지를 식별하고 해당 메시지를 함께 처리할 수 있습니다.
응용프로그램 상태구성#
대화 그룹의 한 가지 이점은 대화 그룹 식별자가 응용 프로그램 상태를 식별하고 검색할 수 있는 편리한 키라는 사실입니다.
대화 그룹 식별자를 사용하면 데이터베이스에서 응용 프로그램 상태를 쉽게 유지 관리할 수 있습니다. 계속해서 메시지 교환과 관련된 작업 수행이 증가할 경우 응용 프로그램 상태를 유지 관리하기 위해 응용 프로그램을 계속 실행하는 것은 비효율적입니다.
SQL Server에서 응용 프로그램이 메시지를 보내거나 받을 때마다 대화 그룹을 잠그므로 응용 프로그램은 다른 프로그램이 동시에 같은 상태 데이터를 업데이트하지 않도록 명시적으로 방지할 필요가 없습니다. 응용 프로그램은 간단하게 대화 그룹을 잠그고 상태를 복원하고 메시지를 처리하며 상태를 업데이트한 다음 트랜잭션을 커밋합니다.
대화 그룹 수명#
- 응용 프로그램이 기존 대화 그룹과 관련되지 않은 새 대화를 시작합니다. Service Broker는 새 대화 그룹을 만들어 대화 그룹에 새로운 식별자를 할당합니다.
- 응용 프로그램이 현재 존재하지 않는 대화 그룹 식별자와 관련된 대화를 시작합니다. 이 경우 Service Broker는 지정된 식별자를 가진 새 대화 그룹을 만듭니다. 그러면 대화 그룹 식별자에 원하는 값을 직접 할당할 수 있습니다
-
Service Broker가 다른 서비스에서 시작한 새 대화의 첫 번째 메시지를 받습니다. 이 경우 Service Broker는 서비스 이름과 Broker 인스턴스 식별자(있을 경우)를 사용하여 다음을 수행합니다.
- 알맞은 큐를 찾습니다.
- 새 대화 그룹을 만들고 대화 그룹을 큐에 연결합니다.
- 새 대화 핸들을 만들어 새 대화 그룹에 추가합니다.
- 들어오는 메시지를 큐에 넣습니다
서비스 아키텍처#
메시지 유형 - 응용 프로그램 간에 교환된 메시지의 이름을 정의합니다. 필요에 따라 메시지에 대한 유효성 검사를 제공합니다.
- 계약 - 특정 대화의 메시지 방향 및 유형을 지정합니다.
- 큐 - 메시지를 저장합니다. 이 저장 메커니즘은 서비스 간 비동기 통신을 허용합니다. Service Broker 큐는 같은 대화 그룹에 있는 메시지의 자동 잠금과 같은 추가 이점을 제공합니다.
- 서비스 - 대화에 대해 주소를 지정할 수 있는 끝점입니다. Service Broker 메시지는 한 서비스에서 다른 서비스로 전송됩니다. 서비스는 메시지를 보관할 큐를 지정하고 대상이 될 수 있는 서비스에 계약을 지정합니다. 계약은 서비스에 잘 정의된 메시지 유형 집합을 제공합니다.
.gif)
그림에서와 같이 ProcessExpenses 계약은 세 가지 메시지 유형 SubmitExpense, AcceptDenyExpense 및 ReimbursementIssued를 지정합니다. 계약은 비용 보상 작업을 수행하는 대화에 필요한 메시지 유형을 나열합니다. ProcessExpenses 계약은 ProcessExpense 서비스 간의 대화와 ProcessExpense 서비스로 대화를 시작하는 모든 대화를 제어합니다. ProcessExpense 서비스는 들어오는 메시지와 나가는 메시지를 ExpenseQueue 큐에 저장합니다. ExpenseProcessing 저장 프로시저는 이 큐에서 메시지를 받아서 처리한 다음 회신이 필요한 경우 해당 Broker로 라우팅하는 데 사용하는 큐로 메시지를 다시 보냅니다.
메세지 유형
- Servive Broker를 사용하는 응용프로그램은 서로 메세지를 대화의 일부로 보내 통신한다.
- 대화 참가자는 각 메시지의 이름과 내용에 동의해야한다. 메세지 유형개체 는 메세지의 유형의 이름을 정의하고 메세지의 포함된 데이터 유형을 정의한다.
- 메세지 유형은 생성된 데이터 베이스에서 유지되며, 대화에 참가한 각 데이터 베이스의 동일한 메세지 유형을 만든다.
- 빈 메세지의 경우 메세지 본문에 데이터가 없어야 한다.
- DEFAULT 라는 기본 제공 메세지 유형을 제공하고 Service Broker SEND 명령에 메세지 유형을 지정하지 않으면 DEFAULT메세지 유형을 사용한다.
계약
- 응용프로그램에서 특정 작업을 수행하는데 사용하는 메세지 유형을 정의한다.
- 각 서비스가 특정 작업을 수행하기 위해 보내는 메세지의 대한 두 서비스 간의 게약이다., 생성된 데이터베이스에서 유지된다.
- 대화에 참여한 각 데이터베이스는 동일한 게약을 만든다.
- DEFAULT 라는 기본 계약도 포함되어 있다. DEFALT 계약에는 SENT BY ANY 메세지 유형만 포함된다.
큐
- 메세지를 저장한다. 메세지를 받으면 서비스는 큐에 메세지가 삽임된다. 서비스에 메세지를 가져오기 위해 응용 프로그램은 쿠에서 메세지를 받는다.
- 각 서비스는 하나의 큐에 연결된다. 큐에서 메세지는 하나의 행이 된다.
서비스
- 서비스는 특정 비즈니스 작업 또는 비즈니스 작업 집하의 이름입니다
- 서비스 간에 대화가 발생합니다.
- 서비스 브로거는 서비스 이름을 사용하여 데이터베이스 내의 올바른 큐로 메세지를 배달하고 베세지를 라우팅하고 대화를 위한 계약을 강제 적용하고 새 대화를 위한 원격 보안을 결정합니다.
네트워킹 및 원격 보안
| 설명 | |
|---|---|
|
원격 서비스 바인딩 |
Broker가 대화 보안에 사용하는 인증서를 설정하는 방법에 대해 설명합니다. 대화 보안은 특정 서비스에 대한 대화에 종단 간 암호화와 원격 권한 부여를 제공합니다. |
|
경로 |
서비스 위치와 서비스가 포함된 데이터베이스를 지정하는 방법에 대해 설명합니다. Service Broker가 메시지를 배달하려면 경로가 필요합니다. 기본적으로 각 데이터베이스에는 다른 어떤 경로도 정의되지 않은 서비스가 현재 인스턴스 내에서 배달되도록 지정하는 경로가 포함됩니다. |
|
Service Broker 끝점 |
TCP/IP 연결을 통해 메시지를 보내고 받을 수 있도록 SQL Server를 구성하는 방법에 대해 설명합니다. 끝점은 끝점에 대한 무단 연결을 방지하는 전송 보안을 제공할 수 있습니다. |
이 글은 스프링노트에서 작성되었습니다.
'Service Broker' 카테고리의 다른 글
| Sesrvice Broker::보안 (0) | 2010.06.04 |
|---|---|
| Service Broker::장점 (1) | 2010.06.04 |
| Service Broker::소개 (0) | 2010.06.04 |
소개
Service Broker는 SQL Server에 큐 기능과 안정적인 메시징 기능을 제공합니다. Service Broker는 단일 SQL Server 인스턴스를 사용하는 응용 프로그램과 여러 인스턴스에 작업을 분산하는 응용 프로그램에서 모두 사용됩니다.
Service Broker는 단일 SQL Server 인스턴스 내에서 강력한 비동기 프로그래밍 모델을 제공합니다. 데이터베이스 응용 프로그램은 일반적으로 비동기 프로그래밍을 사용하여 대화형 응답 시간을 줄이고 전반적인 응용 프로그램 처리량을 늘립니다.
또한 Service Broker는 SQL Server 인스턴스 간에 안정적인 메시징을 제공합니다. Service Broker는 개발자가 서비스라고 하는, 독립적인 자체 포함 구성 요소에서 응용 프로그램을 작성하는 데 도움을 제공합니다. 이러한 서비스에서 제공하는 기능을 필요로 하는 응용 프로그램은 메시지를 사용하여 해당 서비스와 상호 작용합니다. Service Broker는 TCP/IP를 사용하여 인스턴스 간에 메시지를 교환합니다. Service Broker에는 네트워크에서의 무단 액세스를 차단하고 네트워크를 통해 전송되는 메시지를 암호화하는 기능이 있습니다.
역활
-
대화
- Service Broker는 메시지를 보내고 받는 기본적인 기능을 기반으로 설계되었습니다. 각 메시지는 안정적이고 지속적인 통신 채널인 대화의 일부분을 구성합니다. 각 메시지와 대화에는 개발자의 안정적인 응용 프로그램 작성을 돕기 위해 Service Broker가 강제 적용하는 특정 유형이 있습니다.
- 새 Transact-SQL 문을 통해 응용 프로그램에서 안정적으로 메시지를 보내고 받을 수 있습니다. 응용 프로그램에서는 관련된 작업 집합에 대한 이름인 서비스에 메시지를 보내고 내부 테이블 보기인 큐로부터 메시지를 받습니다.
- 같은 작업에 대한 메시지는 같은 대화에 속합니다. 각 대화 내에서 Service Broker는 응용 프로그램이 모든 메시지를 전송된 순서대로 각각 한 번씩만 받도록 합니다.
- 같은 대화를 대화그룹으로 연결할 수도 있습니다.
-
메세지 순서 지정 및 조정
- 큐가 통합되어 데이터베이스 유지 관리 운영에 Service Broker도 포함된다. 관리자가 일상적으로 수행해야 할 유지 관리 작업이 없습니다.
-
트랜잭션 비동기 프로그래밍
- 메세징은 트랜잭션 방식이므로 트랜잭션이 롤백 될 경우 트랜잭션의 모든 Service Broker 작업이 롤백된다.
- 비동기 프로그래밍을 통해 개발자는 큐를 사용하는 응용 프로그램을 쉽게 작성할 수 있습니다. 많은 데이터베이스 응용 프로그램에는 리소스가 허용될 때 수행할 작업에 대한 큐 역할을 하는 테이블이 포함되어 있습니다. 큐를 사용하면 데이터베이스가 사용 가능한 리소스를 효율적으로 사용하면서 대화형 사용자에 대한 응답성을 유지할 수 있습니다. Service Broker는 큐를 데이터베이스 엔진의 중요한 부분으로 제공합니다.
-
느슨하게 연결된 응용 프로그램에 대한 지원
- 느슨하게 연결된 응용 프로그램은 서로 독립적으로 메시지를 주고받는 여러 프로그램으로부터 구성됩니다.
- 이러한 응용 프로그램은 교환되는 메시지에 대해 동일한 정의를 포함하고 서비스 간의 상호 작용에 대해 전체적으로 동일한 구조를 정의해야 합니다.
- 응용 프로그램은 동시에 실행되거나 같은 SQL Server 인스턴스 내에서 실행되거나 구현 정보를 공유해야 할 필요는 없습니다.
- 응용프로그램은 대화내 다른 참가자의 물리적 위치 또는 구현을 알 필요가 없습니다.
Service Broker 구성요소
-
대화 구성요소
- 대화그룹, 대화 메세지, 런타임 구조를 구성한다.
- 대화 아키텍처 참조
-
서비스 정의 구성요소
- 응용프로그램에서 사용하는 대화의 기본 구조를 지정하는 디자인 타임 구성요소
- 메세지 유형, 대화 흐름, 데이터베이스 저장소 등 정의
- 서비스 아키텍처 참조
-
네트워크 및 구성 요소
- SQL Server 인스턴스 외부의 메세지 교화을 위한 인프라 정의
이 글은 스프링노트에서 작성되었습니다.
'Service Broker' 카테고리의 다른 글
| Sesrvice Broker::보안 (0) | 2010.06.04 |
|---|---|
| Service Broker::장점 (1) | 2010.06.04 |
| Service Broker::아키텍처 (0) | 2010.06.04 |
- --CREATE TABLE [dbo].[odd_repl_data_snapshot](
-- [gd_no] [varchar](10) NOT NULL,
-- [org_data] [text] NULL,
--) --ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] - /*
update a
set a.org_data = b.org_data
from repl_source.dbo.odd_repl_data_snapshot a with(nolock)
inner join repl_source.dbo.dup_data b with(nolock) on a.gd_no = b.gd_no
*/ - declare @ptr varbinary(16)
declare @str varchar(max)
select @str = org_data
from repl_check.dbo.dup_data with(nolock) where gd_no = '117368652' - select @ptr= textptr(org_data)
from repl_check.dbo.odd_repl_data_snapshot with(nolock)
where gd_no = '117368652'
writetext repl_check.dbo.odd_repl_data_snapshot.org_data @ptr with log @str - --
--
update a
set a.org_data = b.org_data
from repl_source.dbo.test_varcharmax a with(nolock)
inner join repl_check.dbo.dup_data b with(nolock) on a.gd_no = b.gd_no
--truncate table repl_target.dbo.odd_repl_data_snapshot
--truncate table repl_target.dbo.test_varcharmax- select --a.gd_no , substring (b.org_data , b.break_idx , 20) , substring(b.org_data , b.break_idx , 20)
a.gd_no , datalength(b.org_data) , datalength(a.org_data)
from repl_target.dbo.odd_repl_data_snapshot a with(nolock)
inner join repl_source.dbo.dup_data b with(nolock) on a.gd_no = b.gd_no
where b.seqno <= 3
select --a.gd_no , substring (b.org_data , b.break_idx , 20) , substring(b.org_data , b.break_idx , 20)
a.gd_no , datalength(b.org_data) , datalength(a.org_data) , datalength(c.org_data)
from repl_target.dbo.test_varcharmax a with(nolock)
inner join repl_source.dbo.test_varcharmax c with(nolock) on a.gd_no = c.gd_no
inner join repl_source.dbo.dup_data b with(nolock) on a.gd_no = b.gd_no
where b.seqno <= 3
update repl_target.dbo.odd_repl_data_snapshot set org_data= '' where gd_no = '117368652'- --
--CREATE TABLE [dbo].[test_varcharmax](
-- [gd_no] [varchar](10) NOT NULL,
-- [org_data] [varchar](max) NULL,
--
--) - backup database repl_check to disk='e:\repl_source_full.BAK' with stats
go
backup database repl_target to disk='e:\repl_target_full.BAK' with stats
이 글은 스프링노트에서 작성되었습니다.
'Replication' 카테고리의 다른 글
| 복제::스키마 옵션 (0) | 2012.01.30 |
|---|---|
| 복제::숨겨진 저장프로시저 확인 (0) | 2011.01.16 |
| 복제::#5 구현&삭제 스크립트 (0) | 2010.06.04 |
| 복제::머지복제에러 (0) | 2010.06.04 |
복제 삭제
- 방법 1: http://msdn.microsoft.com/ko-kr/library/ms152757.aspx
- 방법 2: http://support.microsoft.com/kb/324401
-
이상하게 잘 못 삭제했을 경우
-
select replinfo,* from sysobjects where replinfo = 0 을 찾아서 입력합니다.
-
sp_removedbreplication [ [ @dbname = ] 'dbname' ] [ , [ @type = ] type ] -
-
-
- [ @dbname=] 'dbname'
-
-
- 데이터베이스의 이름입니다. dbname은 sysname이며 기본값은 NULL입니다. NULL인 경우 현재 데이터베이스를 사용합니다.
-
-
- [ @type = ] type
-
-
- 데이터베이스 개체를 제거 중인 복제의 유형입니다. type은 nvarchar(5)이며 다음 값 중 하나일 수 있습니다.
- tran
- 트랜잭션 복제 게시 개체를 제거합니다.
- merge
- 병합 복제 게시 개체를 제거합니다.
- both(기본값)
- 모든 복제 게시 개체를 제거합니다.
-
ERROR CASE
게시& 배포자가 먼저 삭제되고 구독이 남아 있을 경우
이 글은 스프링노트에서 작성되었습니다.
'Replication' 카테고리의 다른 글
| 복제::숨겨진 저장프로시저 확인 (0) | 2011.01.16 |
|---|---|
| 복제::LOB DataType 제한 (0) | 2010.06.04 |
| 복제::머지복제에러 (0) | 2010.06.04 |
| 복제::스냅숏 DB를 사용한 게시 초기화 (0) | 2010.06.04 |
FIX: Error message when you try to insert data on a subscriber of a merge replication in SQL Server 2005: "Msg 548, Level 16, State 2, Line 1. The insert failed"
On This Page
SYMPTOMS
The insert failed. It conflicted with an identity range check constraint in database 'DatabaseName', replicated table 'Schema.TableName', column 'ColumnName'. If the identity column is automatically managed by replication, update the range as follows: for the Publisher, execute sp_adjustpublisheridentityrange; for the Subscriber, run the Distribution Agent or the Merge Agent.
This problem occurs when multiple Merge Agents synchronize data at the same time for the same merge publication. This problem can be exacerbated if you have many subscribers to the merge publication.

CAUSE
RESOLUTION
WORKAROUND
sp_changemergepublication '<PublicationName>', 'max_concurrent_merge', 1
Note After you use this workaround, performance may decrease if you have many subscribers for the publication. This behavior occurs because only one subscriber can synchronize data at a time.
STATUS
MORE INFORMATION
How to determine whether you are experiencing this problem
To determine whether you are experiencing this problem, follow these steps:| 1. | Verify that the current identity value is smaller than the lower bound of the first identity range of the identity range check constraint. To obtain the current identity value, run the following statement:
To obtain the identity ranges of the identity range check constraint, run either of the following statements:
Statement 1
Statement 2
|
| 2. | Use a SQL Server Profiler trace to determine whether interleaved executions of the sp_MSsetup_publisher_idrange stored procedure are started by separate Merge Agent sessions for the same publication. However, interleaved executions of the sp_MSsetup_publisher_idrange stored procedure do not always indicate that you are experiencing this problem. This is because SQL Server Profiler was not running when the original occurance of the merge synchronization generated the first error message. However, interleaved executions of the sp_MSsetup_publisher_idrange stored procedure do increase the possibility of experiencing this problem. |
| 3. | You can find overlapping merge synchronizations that occur when you receive the "548" error message occurs. To do this, you can review the merge history in the distribution database. To do this, run the following statements:
|
How to correct existing damaged identity ranges for a problematic table
After you install the cumulative update or after you use the method that is described in the workaround section, an existing damaged identity range in a table is not corrected. You will still receive the "548" error message if you try to insert data into the table and synchronize data on a subscriber. Therefore, you must manually correct the damaged identity ranges for the table. To do this, follow these steps.Note These steps involve manually overriding the current identity seed value for the table to correctly reseed the identity value at the publisher. In the damaged state, the current identity value is smaller than the first identity range in the merge replication identity range check constraint. The steps manually raise the identity value to fall inside the identity range that is defined by the merge replication identity range check constraint. These steps assume that identities are configured in an ascending manner and that the identity increment is configured to increase by a value of 1.
| 1. | Confirm that the identity increment value is 1 and that the identity proceeds in ascending manner. You can obtain the identity increment value by running the following statement on the publisher:
|
||||
| 2. | Run the following statement on the publisher to find the current identity value on the problematic identity column:
After you receive the result, note the current identity value value for comparison in the later steps. Notice that the current column value valye may be either larger or smaller than the current identity value value.If the current column value value is larger than the current identity value value, the column value may have originated at other replications in the topology and merged successfully with the publisher replication. If the current column value value is smaller than the current identity value value, the values may have been inserted on the publisher at a earlier time by using the SET IDENTITY_INSERT ON statement before the merge replication configuration. |
||||
| 3. | Run the following statements on the publisher to determine the current identity ranges of the identity range check constraint for the problematic table:
After you receive the result, note the value of the constraint_keys column of the record where the value of the constraint_name column is "repl_identity_range_GUID". The GUID value corresponds to the value of the artid column for the article in the sysmergearticles system table. To obtain the GUID, run the following statement:
The identity range check constraint spans two separate ranges. The two sets of ranges do not have to be contiguous. For example, the value of the constraint_keys column can be as follows:
([ColumnName]>(1001) AND [ColumnName]<=(2001)
Note This article uses this example to present code in the rest of steps.OR [ColumnName] > (9001) AND [ColumnName]<=(10001)) In this example, the ranges each span 1,000 values. 1,000 is the default range size. However, you can change the identity range size by using one of the following methods:
|
||||
| 4. | If you experience the problem that is described in the "Symptoms" section, the current identity value that you noted in step 2 should be smaller than the lower bound of the first identity range of the identity range check constraint that you noted in step 3. If the current identity value in step 2 is larger than the upper bound of the second identity range of the identity range check constraint, resolve the problem by using the method that is recommended in the error message. Therefore, you should run the sp_adjustpublisheridentityrange stored procedure on the publisher. For more information about the sp_adjustpublisheridentityrange stored procedure, visit the following Microsoft Developer Network (MSDN) Web site: http://msdn.microsoft.com/en-us/library/ms181527.aspx (http://msdn.microsoft.com/en-us/library/ms181527.aspx)
|
||||
| 5. | Run the following statement to determine whether any rows are in the current identity ranges of the identity range check constraint:
Notes
|
||||
| 6. | Manually reseed the current identity for the problematic table to fall inside a valid range. Reseed the current identity to the lowest value of the current identity ranges plus 1. For example, if the lowest value of the current identity ranges is 1001, the first possible in-range value is 1002 because the low end of the range of the identity range check constraint uses the greater than sign (>). To do this, run the following statement on the publisher, and then go to step 8:
|
||||
| 7. | Manually reseed the current identity for the problematic table to fall inside a valid range. Assume that the identity increment is 1. Reseed the current identity to the value that you noted in step 5, and then add 1. For example, if the value that you noted in step 5 is 1507, reseed the current identity to 1508. To do this, run the following statement on the publisher:
|
||||
| 8. | Perform a test to determine whether new rows can be inserted into the table in the publisher database without error 548 occurring. |
REFERENCES
For more information about the list of builds that are available after SQL Server Service Pack 2, click the following article number to view the article in the Microsoft Knowledge Base:
For more information about the Incremental Servicing Model for SQL Server, click the following article number to view the article in the Microsoft Knowledge Base:
For more information about how to obtain SQL Server 2005 Service Pack 2, click the following article number to view the article in the Microsoft Knowledge Base:
For more information about the new features and the improvements in SQL Server 2005 Service Pack 2, visit the following Microsoft Web site:
For more information about the naming schema for SQL Server updates, click the following article number to view the article in the Microsoft Knowledge Base:
For more information about software update terminology, click the following article number to view the article in the Microsoft Knowledge Base:
이 글은 스프링노트에서 작성되었습니다.
'Replication' 카테고리의 다른 글
| 복제::LOB DataType 제한 (0) | 2010.06.04 |
|---|---|
| 복제::#5 구현&삭제 스크립트 (0) | 2010.06.04 |
| 복제::스냅숏 DB를 사용한 게시 초기화 (0) | 2010.06.04 |
| 복제::지연된 명령어 확인 (0) | 2010.04.13 |
스냅숏 DB를 사용한 게시 초기화 방법
트랜잭션 복제, 병합복제, 스냅숏 복제에 게시를 초기화 하는 방법 중에 스냅숏 DB를 사용한 게시 초기화 방법.
- SQL Server 2005 Enterprise Edition 서비스 팩 2 이상 버전일 경우만 가능
현재 구독 초기화 방법중 알고 있는 방법은
- 스냅숏 복제를 이용하는 방법
- Db 백업 후 복원을 이용하는 방법
- 게시할 테이블을 BCP 나 SSIS를 통해 데이터를 이관해 둔 상태로 처리하는 방법
- 스냅숏 DB를 사용하는 방법
방법
게시의 속성 중에 sync_method 옵션중에 database snapshot 가 추가 되었음 (database snaphort character : 문자모드, 사용하지 않은 것이 좋을 것 같음)
해당 옵션은 복제 마법사를 통해서 세팅이 불가능하며, 게시를 설정한 후 아래 스크립트로 변경해야 한다.
-
-- 게시 DB에서 실행 해야 한다.
-
exec sp_helppublication; -- 조해 본다.
exec sp_changepublication
@publication = '게시 이름',
@force_invalidate_snapshot = 1,
@property = 'sync_method',
@value = 'database snapshot' -- 5번
결과
- 이 방법으로 변경해서 게시를 초기화 하게 되면 게시이름_DB 이름으로 스탭숏 DB가 생성되며, 게시가 초기화 완료되면 삭제된다. 기존에 동일한 스탭숏 DB가 있다고 해도 항상 새로 생성한다.
- 대용량 DB일 경우 스탭숏 DB를 생성할 공간만 있다면, 이 방법을 사용했을 때 스냅숏 초기화 하는 과정 동안 서비스 DB에 테이블 lock가 걸리지 않으므로 서비스에 지장이 덜 가게 된다.
- 스냅숏 복제 작동 방법 : http://msdn.microsoft.com/ko-kr/library/ms151734(SQL.90).aspx
참고
- 대용량 DB일 경우 Arrary 스토리지를 사용해서 백업/복원하는 초기화 방법을 빠르게할 수도다.: http://sqlcat.com/technicalnotes/archive/2009/05/04/initializing-a-transactional-replication-subscriber-from-an-array-based-snapshot.aspx
- sync_mode 사용 초기화 : http://blogs.msdn.com/mangeshd/archive/2008/05/30/how-to-use-database-snapshot-sync-mode-while-creating-a-new-tran-snapshot-publication-using-sp-addpublication.aspx
- http://sqlcat.com/whitepapers/archive/2008/02/11/database-snapshot-performance-considerations-under-i-o-intensive-workloads.aspx
이 글은 스프링노트에서 작성되었습니다.
'Replication' 카테고리의 다른 글
| 복제::#5 구현&삭제 스크립트 (0) | 2010.06.04 |
|---|---|
| 복제::머지복제에러 (0) | 2010.06.04 |
| 복제::지연된 명령어 확인 (0) | 2010.04.13 |
| 복제::잘못 삭제 했을 경우 (0) | 2010.03.15 |
SSIS 연결 끊기는 현상
INSERT SEEKDEPOSITOR[109]] 오류: SSIS 오류 코드 DTS_E_OLEDBERROR. OLE DB 오류가 발생했습니다.
오류 코드: 0x80004005. OLE DB 레코드를 사용할 수 있습니다.
원본: "Microsoft SQL Native Client" Hresult: 0x80004005 설명: "통신 연결 오류입니다.".
OLE DB 레코드를 사용할 수 있습니다.
원본: "Microsoft SQL Native Client" Hresult: 0x80004005
설명: "TCP 공급자: 현재 연결은 원격 호스트에 의해 강제로 끊겼습니다. ". \\
[INSERT SEEKDEPOSITOR[109]] 오류: SSIS 오류 코드 DTS_E_INDUCEDTRANSFORMFAILUREONERROR.
오류 코드 0xC020907B이(가) 발생했기 때문에
"입력 "OLE DB 대상 입력"(122)"이(가) 실패했으며
"입력 "OLE DB 대상 입력"(122)"에서의
오류 행 처리는 오류 발생 시 실패하도록 지정되어 있습니다.
지정된 구성 요소의 해당 개체에서 오류가 발생했습니다.
오류에 대한 자세한 정보와 함께
이 오류 메시지보다 먼저 게시된 오류 메시지가 있을 수도 있습니다.
[DTS.Pipeline] 오류: SSIS 오류 코드 DTS_E_PROCESSINPUTFAILED. 오류 코드 0xC0209029(으)로 인해 구성 요소 "INSERT SEEKDEPOSITOR"(109)에서 ProcessInput 메서드가 실패했습니다. 식별된 구성 요소가 ProcessInput 메서드에서 오류를 반환했습니다. 이 오류는 해당 구성 요소와 관련되어 있지만 데이터 흐름 작업의 실행을 중지할 수도 있는 오류입니다. 오류에 대한 자세한 정보와 함께 이 오류 메시지보다 먼저 게시된 오류 메시지가 있을 수도 있습니다.
[DTS.Pipeline] 오류: SSIS 오류 코드 DTS_E_THREADFAILED. 스레드 "WorkThread0"이(가) 종료되었습니다(오류 코드 0xC0209029). 스레드가 종료된 이유에 대한 자세한 정보와 함께 이 오류 메시지보다 먼저 게시된 오류 메시지가 있을 수도 있습니다.
[DTS.Pipeline] 정보: 실행 후 단계를 시작하고 있습니다.해당 장비의 에러로그
-- 에러 로그 데이터..
2009-03-30 10:21:18.940 spid156 오류: 4014, 심각도: 20, 상태: 2.
2009-03-30 10:21:18.940 spid156 A fatal error occurred while reading the input stream from the network. The session will be terminated.
원인
- 패키지로 이동시 DB의 연결이 끊어져서 이관 실패
원인1
- for 문을 사용해서 연결을 계속 시도할 경우 connection을 다시 맺지 못하는 경우가 있어서 안될 수 있음 기존 연결을 다시 재사용하는 방법을 사용해 볼 수 있다.
- 연결관리자> DB 연결 > 속성 RetainSameConnection을 TRUE로 한번 해보고 한다.
원인2
- DB 에러로그에도 특정하게 연결이 끊김 현상이 발생하면 네트워크 카드 문제나 방확벽 문제 일 수 있다.
- 데이터에 문제가 없는데도 그렇다면 더욱 확실하다.
- 특이 네트워크 카드의 TCP Chimmeny 설정이 원본과 대상 장비가 구성이 같아야 한다. 그렇지 않으면 동일하게 해 주는것이 좋다.
- 관련 정보: http://support.microsoft.com/kb/942861
-
네트워크 단에서 데이터가 유실되는 거라면 Nemon을 이용해서 트래픽을 TRACE 해보면 명확해 진다.
-
관련 정보자료
원인 3
- 패키지를 실행하는 장비의 연결 정보에 영향을 받으므로 Feature Pack for Microsoft SQL Server 2005 을 최신버전으로 설치 해본다.
-
서비스팩에 따라 .SQL Client 연결의 버전이 달라서 달라질 수 있다.
- http://www.microsoft.com/downloads/details.aspx?FamilyID=536fd7d5-013f-49bc-9fc7-77dede4bb075&DisplayLang=en
- 재부팅이 필요한데 그냥 하니가 별 반응이 없었다. 근데 원인이 연결 정보의 버전 차이라면 재부팅 하지 않아도 가능하다.
원인 4
- 데이터에 문제가 없는데 안되는거라면 두 장비 사이의 코드 페이지 확인
- 문자열 컬럼이 존재하고 한글 데이터가 있는데 두 장비 사이에 코드 페이지가 틀리면 입력되면서 깨질 수 있다.
- 코드 페이지를 피하려면 둘다 변경하거나 서비스 장비이기 때문에 변경히 힘들다면, 한 장비에서 BCP out 을 받고 BCP IN을 사용해본다. 이때 -c 옵션으로 해서 안되는데 -n 옵션으로 해서 문제가 없다면 확실한 코드 페이지 때문에 발생하는 문제이다.
원인5
* 이도 저도 아니면.. 방화벽 문제 일 수도 있고 원본장비와 대상 장비의 서비스팩을 동일하게 맞춰보는것도 좋다.
이 글은 스프링노트에서 작성되었습니다.
'Error Case' 카테고리의 다른 글
| ‘A time-out occurred while waiting for buffer latch’ (0) | 2017.07.12 |
|---|---|
| Server Broker Error Case (0) | 2011.03.11 |
| 에러::Agent (1) | 2010.06.03 |
| 에러::64bit 버퍼 풀 페이징 (0) | 2010.06.03 |
Agent 에러 상황별 처리 내역
Agent가 시작되지 않음
-
증상
- SQLServer는 Start 된 상태
-
Agent 시작시 Event LOG
-
- event id : 103
- ServerAgent could not be started (reason: Unable to connect to server '(local)'; SQLServerAgent cannot start).
- event id : 102
- SQLServerAgent service successfully stopped.
- 시작되다가 바로 중지되는 상황을 보임
-
-
Agent 에러 로그
-
- 메시지
[298] SQLServer Error: 10061, TCP Provider: No connection could be made because the target machine actively refused it. [SQLSTATE 08001] - [165] ODBC Error: 0, Login timeout expired [SQLSTATE HYT00]
- [298] SQLServer Error: 10061, An error has occurred while establishing a connection to the server. When connecting to SQL Server 2005, this failure may be caused by the fact that under the default settings SQL Server does not allow remote connections. [SQLSTATE 08001]
- [000] Unable to connect to server '(local)'; SQLServerAgent cannot start
- [298] SQLServer Error: 10061, TCP Provider: No connection could be made because the target machine actively refused it. [SQLSTATE 08001]
- [165] ODBC Error: 0, Login timeout expired [SQLSTATE HYT00]
- [298] SQLServer Error: 10061, An error has occurred while establishing a connection to the server. When connecting to SQL Server 2005, this failure may be caused by the fact that under the default settings SQL Server does not allow remote connections. [SQLSTATE 08001]
- [382] Logon to server '(local)' failed (DisableAgentXPs)
- [098] SQLServerAgent terminated (normally)
- 메시지
- 타켓이 되는 서버에 접속을 못하는 것으로 보임
-
-
그 밖이 증상
- 해당 장비에서 ., (local) 로 해도 접속이 안됨, 즉 자기 장비의 Named 를 찾지를 못함
- agent 실행하는 주체가 Local system 의 Administrators 였음.
- hosts 파일에 자기 장비의 IP를 적고 이름을 적어 놓았음 ex) IP GDB2
- 클라이언트에 GDB2 별칭이 등록되어 있으며, 포트 설정이 잘 못 되어 있었음
-
조치사항
- agent가 실행되는 사용자에게 sysdamin 민 권한을 줌 -> 이미 주었지만 ip 인식 자체가 안되는 거기 때문에 소용 없음.
- 자기 자신에게 링크드 별칭 있는것 우선은 제거 -> 예전에 별칭이 있으면 별칭을 먼저 인식하고 agent가 생성 안되는 경우 있었음 -> 완료
-
인스턴스 재시작 - Stop -> Start 시작
-
서버 재 시작후 exec sp_readerrorlog 0 로 아래 메세지가 있는지 확인
-
Server local connection provider is ready to accept connection on [ \\.\pipe\SQLLocal\MSSQLSERVER ].
Server local connection provider is ready to accept connection on [ \\.\pipe\sql\query ]
-
Server is listening on ['any' <ipv4> <Port Number>] or [ <ipaddress> <ipv4> <Port Number>].
-
포트로 잘 올라왔는지 확인 명령창에서 : "netstat -an or -na| findstr <PortNumber>".
없으면 문제 있는 것임. 서버를 다시 깔아야 할지도 모름.
SQLAgent 올려본다. 위의 에러가 또 발생하면 다음 으로 한번 해보기
-
-
-
메뉴>Miscrosfot SQL Server2005>congiguration Tools> SQL Server Surface Are Congiguration 실행
- Surface Area Congiguration for Services and Connections 실행
- Database Engine 의 remote Connections 에서 Using both TCP/IP and named pipes 체크하고 OK, 인스턴스 재 시작 해보기
-
hosts 파일에 GDB2 있는것 제거 ,
- SQL Server Conguration Manager >SQL Server2005 Network Congiguration>Protocols for MSSQLSERVER >
- Named Pipes : Enagled 해보고 인스턴스 재시작 -> SQLAgent 시작해본다.
- SQLAgent 시작 권한은 Local System의 administraotr로 바꾸고 SQLAgent 시작해 본다. (지금은 도메인으로 되어 있음) : 권한은 이미 처리해 놨음
-
결국, 해당 장비에서 자기 로컬로 DB가 접근되어야 하는데 안되면 안되는 것임.
이 글은 스프링노트에서 작성되었습니다.
'Error Case' 카테고리의 다른 글
| Server Broker Error Case (0) | 2011.03.11 |
|---|---|
| 에러::SSIS 연결끊기는 현상 (1) | 2010.06.03 |
| 에러::64bit 버퍼 풀 페이징 (0) | 2010.06.03 |
| 에러::msdb 복원시 버전차이 (1) | 2010.06.03 |
증상
- 미러링 걸려있던 DB의 로그가 90% 이상.
- 활성 트랜잭션이 없음에도 log 백업을 해도 로그가 줄어들지 않음
- 주 서버에서 미러가 일시 중지됨
-
파트너 서버에 에러 로그 파일 에
2009-07-05 05:39:01.050spid1sA significant part of sql server process memory has been paged out. This may result in a performance degradation. Duration: 0 seconds. Working set (KB): 263552, committed (KB): 528496, memory utilization: 49%.2009-07-05 05:46:21.370spid1sA significant part of sql server process memory has been paged out. This may result in a performance degradation. Duration: 0 seconds. Working set (KB): 265520, committed (KB): 527400, memory utilization: 50%.
2009-07-05 07:28:27.210spid27sError: 1204, Severity: 19, State: 4.
2009-07-05 07:28:27.210spid27sThe instance of the SQL Server Database Engine cannot obtain a LOCK resource at this time.
Rerun your statement when there are fewer active users. Ask the database administrator to check the lock and memory configuration for this instance, or to check for long-running transactions.
2009-07-05 07:28:27.320spid27sError: 1454, Severity: 16, State: 1.
2009-07-05 07:28:27.320spid27sWhile acting as a mirroring partner for database 'DB명', server instance '주서버명' encountered error 1204, status 4, severity 19. Database mirroring will be suspended. Try to resolve the error and resume mirroring.
2009-07-05 07:28:27.820spid27sDatabase mirroring is inactive for database 'DB명'. This is an informational message only. No user action is required.
(주서버)
2009-07-05 07:28:27.920spid34sError: 1453, Severity: 16, State: 1.
2009-07-05 07:28:27.920spid34s'TCP://정보', the remote mirroring partner for database 'DB명', encountered error 1204, status 4, severity 19. Database mirroring has been suspended. Resolve the error on the remote server and resume mirroring, or remove mirroring and re-establish the mirror server instance.
원인
- * significant part of sql server process memory has been paged out. This may result in a performance degradation.
- Windows 운영체제 페이지를 SQL Server 프로세스의 작업 집한 제한 때문에 발생합니다.
-
http://support.microsoft.com/kb/918483
-
데이터베이스 엔진 오류 : 1204
- SQL Server 데이터베이스 엔진 인스턴스에서 지금 LOCK 리소스를 가져올 수 없습니다. 활성 사용자가 적을 때 문을 다시 실행하십시오. 데이터베이스 관리자에게 이 인스턴스의 잠금 및 메모리 구성이나 장기 실행 트랜잭션을 확인하도록 요청하십시오.
- max server memory 옵션 증가시킴
-
SELECT request_session_id, COUNT (*) num_locks FROM sys.dm_tran_locks
GROUP BY request_session_id ORDER BY count (*) DESC
-
위는 전부 페이지 잠금 문제로 발생 했다.
해결
메리의 페이지 잠그기 사용자 권한을 할당하려면 다음과 같이 하십시오.
- 시작 을 클릭하고 실행 을 클릭합니다 gpedit.msc 를 입력한 다음 확인 을 클릭하십시오. 그룹 정책 대화 상자가 나타납니다.
- 확장 컴퓨터 구성 를 확장한 다음 Windows 설정 .
- 보안 설정 을 확장한 다음 로컬 정책 을 확장하십시오.
- 사용자 권한 할당 을 클릭한 다음 메모리의 페이지 잠그기 두 번 클릭하십시오.
- 로컬 보안 정책 설정 대화 상자에서 사용자 또는 그룹 추가 클릭합니다.
- 사용자 또는 그룹 선택 대화 상자에서 Sqlservr.exe 파일을 실행할 권한이 있는 계정을 추가하고 확인 을 클릭하십시오.
- 그룹 정책 대화 상자를 닫습니다.
- SQL Server 서비스를 다시 시작하십시오
이 글은 스프링노트에서 작성되었습니다.
'Error Case' 카테고리의 다른 글
| 에러::SSIS 연결끊기는 현상 (1) | 2010.06.03 |
|---|---|
| 에러::Agent (1) | 2010.06.03 |
| 에러::msdb 복원시 버전차이 (1) | 2010.06.03 |
| Error::NOLOCK 함께 스캔할 수 없음 - 601 (0) | 2009.12.08 |
Server: Msg 3168, Level 16, State 1, Line 1
The backup of the system database on device d:\temp\master.bak cannot be restored because it was created by a different version of the server (134217904) than this server (134217920).
Server: Msg 3013, Level 16, State 1, Line 1
RESTORE DATABASE is terminating abnormally.
참고:) http://support.microsoft.com/kb/264474/en-us
http://msdn.microsoft.com/en-us/library/aa173515.aspx#
이 글은 스프링노트에서 작성되었습니다.
'Error Case' 카테고리의 다른 글
| 에러::Agent (1) | 2010.06.03 |
|---|---|
| 에러::64bit 버퍼 풀 페이징 (0) | 2010.06.03 |
| Error::NOLOCK 함께 스캔할 수 없음 - 601 (0) | 2009.12.08 |
| Error::Non-yielding IOCP Listener - Stack Dump analysis (0) | 2009.12.07 |
사용법
- --===================================
-- READ TRACE
--===================================
ReadTrace -I파일경로 -S서버명 -dDB명 -U유저 -P패스워드
D:\Program Files\Microsoft Corporation\RML\ReadTrace.exe /?- ReadTrace version 9.00.0023 (X86)
- USAGE:
- NOTE: All command line arguments are case sensitive
- -I File name of the first .TRC file to process [REQUIRED]
- -i If specified, indicates that the .TRC file(s) to process are present inside a CAB/ZIP file with this file name
- -o Full path of directory to place output files [default is current directory]
- -S Name of SQL Server 2005 server to connect to when loading performance analysis data [default is (local)]
- -d Database to use when loading performance data [default is PerfAnalysis].
- User specified below must have CREATE DATABASE permission (if DB doesn't
- exist) or be part of the db_owner role if the database already exists.
- -E Connect to SQL using Windows Authentication [default]
- -U Connect to SQL using this user name
- -P Password for the user specified in -U option
- -a Disable performance analysis
- -f Do not produce .RML output files for each SPID
- -Q Do normalization parse using quoted_identifier OFF symantics. (Default is ON)
- -r# Read at most this # of files (including the first) [default is all files
- until a break in the rollover file sequence is detected].
- -M Mirror trace files by SPID to the specified output directory (All SPIDs
- will be output even if SPID filter is specified)
- -MF Mirror trace files by SPID to the specified output directory (Only SPIDs
- matching filter parameters will be output)
- -A 'INCLUDE or EXCLUDE' events with Applicaiton Names
- -H 'INCLUDE or EXCLUDE' events with Host Names
- -s# 'INCLUDE or EXCLUDE' events from specified SPIDs
- -b Provide a designated start time in required format 2000-05-25 11:46:20:060
- -e Provide a designated stop time in required format 2000-05-25 11:46:20:060
- -D Skip date on log file output
- -? Show usage of command line parameters
- EXAMPLES:
- ReadTrace -Iserver__sp_trace.trc -ic:\temp\traces.cab -oc:\temp\output -f
- ReadTrace -I"c:\my traces\80AllEvents.trc" -o"c:\my output"
- ReadTrace -Ioutput\SQLSRV1__sp_trace_20.trc -ic:\temp\pssdiag.zip -oc:\temp\breakout -f -r2
PSSDIAG 수집 유형
- http://support.microsoft.com/kb/830232
- http://msdn.microsoft.com/en-us/library/aa175399(SQL.80).aspx
이 글은 스프링노트에서 작성되었습니다.
'Peformance Tuning' 카테고리의 다른 글
| dm_os_performance_counters , Server/Process Information (0) | 2010.06.07 |
|---|---|
| 저장 프로시저 및 함수의 마법 깨트리기 #1 (0) | 2010.06.04 |
| SQL서버 성능카운터 (0) | 2010.06.03 |
| 성능::엑셀이용분석하기 (0) | 2010.06.03 |
SQL서버 성능카운터 활용을 위한 팁
원문링크 : http://www.sql-server-performance.com/performance_monitor_counters_sql_server.asp
번역 : 김종균 (jkkim@techdata.co.kr)
SQL서버에서 과도한 I/O의 원인 중 하나는 페이지 분할 입니다. 페이지 split은 인덱스나 데이터 페이지가 꽉 찰 경우에 발생하며, 현재 페이지와 새로이 할당되는 페이지 사이에서 분할이 이루어 집니다. 가끔 발생하는 페이지 분할은 정상입니다만, 과도한 페이지 분할은 과도한 디스크 I/O를 유발하게 되며, 이는 느린 성능을 야기합니다.
SQL서버가 과도한 페이지 분할을 일으키고 있는지를 찾기 원한다면 성능카운터에서 SQL Server Access Methods 개체의 Page Splits/Sec 항목을 모니터 하십시오. 만일 과도한 페이지 분할이 발생하고 있다면, 인덱스의 채우기 비율을 높게 설정하시는걸 고려하십시오. 채우기 비율을 높게 설정하시면 데이터가 가득 차거나, 페이지 분할이 발생하기 전에 데이터 페이지에 보다 더 많은 여유 공간이 있으므로, 페이지 분할을 감소시킬 수 있습니다
높은 Page Splits/sec 은 무얼 의미하는가? 이것은 운영하는 시스템의 I/O하부 시스템에 따라 다르므로 이에 대한 간단이 답을 할 수 없습니다. 그러나 만일 당신이 평상시에 디스크 I/O의 성능 문제가 발생하고, 이 카운터 값이 100을 초과한다면, 채우기 비율을 높여서 성능이 호전 되는지 그렇지 않은지 실험해 보는 것도 좋을 것 입니다.
*****
물리적인 메모리를 SQL서버 Data캐시에 얼마나 할당되었는지 알고 싶다면, SQL Server Buffer Manager Object: Cache Size (pages) 항목을 모니터링 하십시오. 이 수치는 페이지 수로 표시되므로, 이 값에 8K(8192 bytes)를 곱하면, Data캐시로 사용되고 있는 총 메모리의 사용량을 알 수 있습니다.
일반적으로, 이 수치는 서버의 총 메모리 량에 근접해야 합니다. SQL서버로 운영하는 시스템에서 OS커널이나, SQL서버 그리고 기타 유틸리티 프로그램이 사용하는 메모리 량을 최소화 하십시오.
만일 Data캐시 용도로 할당된 메모리 양이 여러분이 생각하는 것 보다 훨씬 작다면, 왜 그런지 원인을 찾으셔야 합니다. 아마도, SQL서버가 메모리를 동적으로 할당하도록 설정하지 않고, 대신에 뜻하지 않게 SQL서버가 적은 메모리를 사용하게 구성 하셨을 겁니다. SQL서버가 가용할 수 있는 Data캐시의 총량은 SQL서버 성능에 아주 큰 영향을 미치기 때문에 원인이 무엇이든 간에 여러분은 해결방안을 찾아야 합니다.
실제로는, SQL서버가 메모리가 부족한지 아닌지를 알기 위해 보다 많은 카운터들이 존재하고, 더 효율적이기 때문에 저는 이러한 카운터(SQL Server Buffer Manager Object: Cache Size (pages))를 모니터 하는데 많은 시간을 사용하지 않습니다. (그래서 어쩌라고. ㅜㅜ)
*****
SQL서버가 얼마나 바쁜지 알기 위해서, SQLServer: SQL Statistics: Batch Requests/Sec 카운터를 모니터 하십시오. 이 카운터는 초당 SQL서버가 받는 배치 요청 수를 측정하고, 일반적으로 서버의 CPU들이 얼마나 바쁜지 나타냅니다. 말하자면, 초당 1000배치가 넘어서면, SQL서버가 매우 바쁘다는 것을 나타내며, CPU병목 현상이 아직 나타나지 않고 있다면, 조만간 CPU병목 현상이 나타날 것임을 알 수 있습니다. 물론 이 수치는 상대적인 것이며, 여러분의 하드웨어가 고 사양이라면, 보다 더 많은 초당 배치요청 수를 커버할 수 있을 것입니다.
네트워크 병목의 관점에서 보자면, 100Mbps 네트워크 카드는 초당 3000 배치 요청을 처리 할 수 있습니다. 만일 네트워크 병목이 심한 서버를 운영하고 계시다면, 네트워크 카드를 2개이상 늘리거나, 1Gbps 네트워크 카드로 교체 할 필요가 있을 것입니다.
몇몇 DBA들은 전체 SQL서버활동량을 측정하기 위해서 SQLServer: Databases: Transaction/Sec: _Total 카운터를 모니터 하는데, 이는 좋은 방법이 아닙니다. Transaction/Sec 카운터는 전체 활동량이 아닌 한 트랜잭션의 내부활동을 측정하며, 왜곡된 값을 나타냅니다. 대신에, SQL서버의 전체 활동량을 측정하는 SQLServer: SQL Statistics: Batch Requests/Sec 카운터를 사용하시기 바랍니다
*****
TSQL코드의 컴파일은 SQL서버의 일반적인 동작입니다. 그러나, 이 컴파일이 CPU와 다른 리소스들을 많이 잡아 먹기 때문에, SQL서버는 가능한 많은 실행계획을 캐시에 저장해서 실행계획이 컴파일 되지 않고 재사용되도록 시도합니다(실행계획은 컴파일이 발생할 때 생성됩니다). 보다 더 많은 실행계획이 재 사용 되어지면, 서버에 대한 부담은 더 적어지게 되며, 전체적인 성능은 더욱 더 향상 됩니다.
SQL서버가 얼마나 많은 컴파일을 하고 있는지 확인 하려면, SQLServer: SQL Statistics: SQL Compilations/Sec 카운터를 모니터 하십시오. 여러분이 기대하시는 것처럼, 이 카운터는 초당 얼마나 많은 컴파일이 SQL서버에 의해서 실행되었는지를 측정합니다.
말하자면, 이 카운터의 수치가 초당 100을 넘어서면, 불필요한 컴파일 오버헤드를 경험하고 계신 것 입니다. 이러한 높은 수치는 여러분의 서버가 매우 바쁨을 나타내거나, 불필요한 컴파일들이 실행되고 있다고 볼 수 있겠습니다. 예를 들어, 오브젝트의 스키마가 변경되거나, 병렬로 실행계획이 잡혀있던 것이 직렬로 실행되어야 하거나, 통계가 다시 계산되었다거나 하는 등의 이유로 SQL서버로부터 재 컴파일 하라는 지시를 받았을 수도 있습니다. 어떤 경우에는, 불필요한 컴파일을 줄이기 위해서 여러분의 노력이 필요할 수 도 있습니다. (역주. 잘 아시듯이, adhoc 쿼리를 저장프로시져로 만들면 컴파일 이슈가 없어지죠)
만약, 여러분의 서버가 초당 100회 이상의 컴파일을 수행한다면, 이 원인이 여러분이 조절할 수 있는 것인지 아닌지 찾기 위해 애 쓰셔야 합니다. 너무 많은 컴파일은 SQL서버의 성능에 악영향을 끼칩니다.
*****
SQLServer: Databases: Log Flushes/sec 카운터는 초당 플러쉬 된 로그 수를 나타냅니다. 이 카운터는 데이터베이스 별로 측정되거나, 단일 SQL서버의 전체 데이터베이스에 대한 값으로 측정 될 수 있습니다.
로그 플러쉬란 무엇일까요? 이해를 쉽게 하기 위해서 예를 들어 설명 하는 게 좋을 것 같습니다. 10개의 INSERT명령이 있는 트랜잭션을 시작한다고 가정하겠습니다. 트랜잭션이 시작되고, 그리고, 첫 번째 INSERT가 실행되고, 새 데이터가 데이터 페이지로 삽입 되어질 때, 필수적으로 동시에 두 가지의 일이 발생합니다. 버퍼캐시의 데이터페이지는 새로이 삽입된 데이터로 변경됩니다, 그리고 이 단일 INSERT명령에 대한 적당한 로그용 데이터가 로그캐시에 쓰여집니다. 이 과정은 트랜잭션이 완료 될 때까지 계속 됩니다. 이때, 로그캐시에 기록된 트랜잭션을 위한 로그 데이터는 즉시 로그파일에 기록됩니다, 그러나 버퍼캐시에 있는 데이터는 다음 체크포인트 프로세스가 실행되기 전까지 버퍼캐시에 머무르게 됩니다. 그리고, 그때 데이터베이스는 새로이 삽입된 행으로 업데이트 됩니다.
여러분은 로그캐시에 대해서 한번도 들어보지 못했을지도 모릅니다. 이것은 SQL서버가 로그파일에 쓰여질 데이터를 기록하는 메모리의 한 영역입니다. 로그캐시의 목적은 트랜잭션이 커밋 되기 전에 특정상황이 발생하여 롤백 해야 하는 상황에서 트랜잭션을 롤백 하는 용도로 사용되기 때문에 매우 중요합니다. 그러나, 트랜잭션이 완료되면 (완료되면 절대 롤백 되지 않음), 로그 캐시는 즉시 물리적인 로그파일로 플러시 됩니다. 이것이 정상적인 절차입니다. SELECT쿼리는 데이터를 수정하지도 않고 트랜잭션을 생성하지도 않고, 로그 플러시를 발생하게 하지도 않음을 명심 하십시오.
본질적으로, 로그캐시에 있는 데이터가 물리적인 로그파일로 쓰여질 때 하나의 로그 플러시가 발생합니다. 따라서, 하나의 트랜잭션이 완료될 때마다, 로그 플러시는 발생하며, 많은 수의 로그 플러시 발생은 SQL서버로부터 수행되는 많은 수의 트랜잭션과 관련이 있습니다. 그리고, 짐작하시는 것처럼 로그 플러시(얼마나 많은 데이터가 로크 캐시로부터 디스크에 기록 되어졌는가) 의 크기는 트랜잭션에 따라 다릅니다. 이 내용이 도움이 되었나요?
우리가 디스크 I/O 병목현상을 격 고 있고, 그 원인을 확신하지 못하고 있다고 가정합시다. 디스크 I/O에 대한 병목을 해결하기 위한 하나의 방법은 Log Flushes/sec 카운터 데이터를 수집하고, 이 과정을 처리하는데 얼마나 바쁜지 보는 것입니다. 여러분의 서버에 많은 트랜잭션이 발생하고 있다며, 로그 플러시 양은 당연히 많을 것입니다, 따라서 이 카운터 항목으로 보는 값은 트랜잭션을 발생하는 활동 형 쿼리가 얼마나 바쁜가에 따라 서버마다 다양할 것입니다. 이 카운터 정보로써 여러분은 초당 발생하는 로그 플러시 수가 운영하는 서버에서 예상되는 트랜잭션의 수 보다 확연하게 높은가에 대한 상황 판단에 도움을 줄 것이다.
예를 들어, 매일 1,000,000행을 한 테이블로 삽입하는 작업을 한다고 가정합시다. 이 행들이 삽입되어질 수 있는 방법은 다양합니다. 첫째, 각 행은 따로따로 삽입되어 질 수 있습니다. 각 INSERT는 단일 트랜잭션 내부에 감싸집니다. 둘째, 모든 INSERTS는 단일 트랜잭션 내에서 수행되어 질 수 있습니다. 마지막으로, INSERTs는 1과 1,000,000사이의 어딘가에 여러 개의 트랜잭션으로 나누어 질 수 있습니다. 각 형태의 처리는 다르며, SQL서버와 초당 플러시 되는 로그 수에 매우 다른 영향을 미칩니다. 더구나, 프로세스가 멀티 트랜잭션으로 처리되고 있는데, 단일 트랜잭션으로 처리되고 있다고 착각할 수 도 있다. 많은 사람들이 단일 프로세스를 단일 트랜잭션으로 생각하고 있는 경향이 있습니다.
첫째의 경우에서, 만일 1,000,000행이 1,000,000개의 트랜잭션으로 삽입되어진다면, 1,000,000번의 로그 플러시가 발생할 것입니다. 그러나, 두 번째 경우에는, 단일 트랜잭션에서 1,000,000행이 삽입되어 질 것이고, 단지 하나의 로그 플러시가 발생할 것입니다. 그리고, 세 번째 경우 에는 플러시 되는 로그의 수는 트랜잭션의 수와 같을 것입니다. 명백히, 로그 플러시의 크기는 1,000,000트랜잭션이 1트랜잭션보다 훨씬 클 것입니다, 그러나, 대개의 경우 성능의 관점에서 여기서 언급한 내용은 그다지 중요하지 않습니다.
어떤 옵션이 가장 좋은가요? 모든 경우에서, 많은 디스크 I/O를 유발할 것입니다. 1,000,000행을 핸들링 할 경우에는 I/O양을 줄일 묘안이 없습니다. 그러나, 하나 혹은 적은 수의 트랜잭션을 사용함으로써 로그 플러시 양을 많이 줄일 수 있을 것이고, 이는 디스크 I/O양을 줄이게 되어, I/O병목 감소와 성능을 높여줄 것입니다.
우리는 두 가지 포인트를 배웠습니다. 첫째는, 여러분이 플러시 되는 로그 양을 가능한 많이 줄이길 원할 것이라는 것과, 둘째, 여러분의 서버에서 발생하는 트랜잭션의 수를 줄이는 것입니다.
*****
SQL서버를 사용하는 많은 수의 사용자는 성능에 영향을 미치기 때문에, 여러분은 SQL Server General Statistics Object: User Connections 카운터에 관심을 가질것입니다. 이 카운터는 사용자 수가 아닌, SQL서버에 현재 연결된 사용자 연결 수를 나타냅니다
이 수치를 해석할 때, 하나의 단일 사용자는 여러 개의 연결들로 열릴 수 있음을 유념하십시오. 그리고 또한, 여러 명의 사람이 하나의 단일 사용자 연결을 공유할 수 도 있습니다. 이 수가 실제 사용자수를 나타낸다고 가정하지 마십시오. 대신에, 서버가 얼마나 바쁜가에 대한 상대적 척도로 사용하십시오. 여러 시간에 걸쳐서 이 수치를 모니터 해보시면, 서버가 많이 사용되고 있는지, 적게 사용되고 있는지 느낄 수 있을 것 입니다.
*****
만약 여러분들의 데이터베이스들이 데드락 문제로 괴로워하고 있다면, SQL Server Locks Object: Number of Deadlocks/sec 카운터를 통해서 추적할 수 있습니다. 그러나, 이 값이 상대적으로 높지 않다면, 이 값은 초단위로 측정되기 때문에 여러분은 더 많이 보기 원할 것입니다. 그리고, 눈에 띄게 보여지기 위해서는 다량의 데드락이 있어야 합니다. (ㅜㅜ)
그러나, 여전히 이 카운터는 여러분이 데드락 문제를 가지고 있는지 확인하기 위해서 가치있는 항목입니다. 차라리, 데드락을 추적하기 위해서 프로필러를 이용하십시오. 이는 보다 상세한 정보를 제공할 것입니다. 데드락 문제를 발견하기 위해서 Number of Deadlocks/sec 카운터를 활용하시고, 좀 더 세부적인 분석을 위해서 프로필러를 사용하십시오.
*****
만약에, 사용자들이 트랜잭션의 완료를 위한 대기시간 때문에 불만을 나타낸다면, 여러분은 개체 잠금이 이 문제가 되고 있는지 찾고 싶을 것 입니다. 문제점을 찾기 위해서, SQL Server Locks Object: Average Wait Time (ms) 카운터를 사용하십시오. 이 카운터는 database, extent, key, paLock Timeouts/secge, RID, table의 다양한 잠금에 대한 평균 대기 시간 정보를 측정합니다.
DBA로써, 여러분은 평균 대기 시간이 얼마 정도까지 허용될 수 있는지 결정해야 합니다. 한가지 방법으로써, 개별 잠금 종류에 대해서 장시간 동안 이 카운터 항목을 모니터 하시고, 각 잠금 별 평균을 파악하시는 겁니다. 그리고 그 평균값을 참고 자료로 활용 하시는 거죠. 예를 들어, RID의 평균 잠금 대기시간이 500ms 라면, 500보다 큰 대기시간을 가지는 개체들은 , 잠재적인 문제점을 가지고 있다고 판단할 수 있을 것입니다. 특히 500보다 훨씬 크거나, 장시간 동안 연장되는 개체들은 더 쉽게 판단할 수 있습니다.
여러분이 트랜잭션 지연에 의한 단일 혹은 다양한 종류의 잠금을 확인 할 수 있다면, 어떤 트랜잭션들이 잠금의 원인이 되었는지 확인할 수 있는지 알기 위해서 조사하길 원할 것 입니다.
*****
그런데 가끔 인덱스 탐색보다 테이블 스캔이 빠른 경우에, 일반적으로 적은 테이블 스캔이 보다 많은 테이블 스캔 보다 좋다. 여러분의 서버에서 얼마나 많은 테이블 스캔이 발생하는지 알아보기 위해서, SQL Server Access Methods Object: Full Scans/sec 카운터를 사용하십시오.이 카운터는 단일 데이터베이스가 아닌 전체 서버에 대한 값이라는 사실을 염두에 두셔야 합니다. 이 카운터 값으로 알게 될 사실 하나는 가끔씩 예측이 가능한 스캔 형태를 나타낸다는 것 입니다. 대부분의 경우에 이 값들은 SQL서버가 내부적으로 사용하는 것 들입니다.
여러분의 응용프로그램에서 나타나는 불규칙적인 테이블 스캔들을 파악하길 원하실 것입니다. 과도한 테이블 스캔이 발생될지를 고려하기 위해서 프로필러 데이터를 수집하고 인덱스 튜닝 마법사를 통해서, 어떤 것이 원인이 되는지 결정 할 수 있게 도움을 받을 수 있습니다. 그리고 몇몇 인덱스를 추가함으로써 테이블 스캔을 줄일 수 있을 것 입니다. 물론 SQL서버는 이 작업을 훌륭하게 수행할 것이고, 더 효율적이라면, 인덱스를 사용하는 것 대신에 테이블 스캔을 수행 할 것입니다. 그러나 내부적으로 어떤 일이 발생하는지 찾아 보지 않는 한 여러분은 알지 못 할 것입니다.
*****
만일 백업 및 복원 명령이 최적이 아닌 속도로 수행된다면, SQL Server Backup Device Object: Device Throughput Bytes/sec 카운터를 이용해서, 이 문제를 확인 할 수 있습니다. 이 카운터는 여러분의 백업이 얼마나 빨리 수행되는지 알려 줄 것입니다. 또한 문제에 대한 의구심을 해결하기 위해서 Physical Disk Object: Avg. Disk Queue Length 카운터를 같이 조사해 볼 수 도 있습니다. 대부분의 경우에 백업과 복원의 성능 문제가 있다면, I/O 병목에 의한 것들입니다.
DBA로써 경험하고 다루게 되는 I/O병목에 대한 판단의 작업 또한 수행할 것입니다. 예를 들면, 느린 백업 또는 복원의 원인이 같은 시점에 수행되는 단순한 DTS작업 때문일 수 있으며, 작업에 대한 일정의 재조정으로 문제를 해결 할 수 있습니다.
*****
여러분이 트랜잭션 복제를 사용하고 계신다면, 로그 리더가 트랜잭션들을 데이터베이스의 트랜잭션 로그로부터 배포 데이터베이스로 옮겨질 때까지의 지연시간을 모니터하길 원하실 것입니다.
또한 배포 에이젼트가 트랜잭션들을 배포데이터베이스에서 구독자 데이터베이스로 옮기는데 소요되는 시간을 모니터 하길 원할 것입니다. 이 두 지연시간의 합은 하나의 트랜잭션이 게시 데이터베이스에서 구독 데이터베이스로 전달되는 총 소요시간입니다.
이 두 카운터는 SQL Server Replication LogReader: Delivery Latency 와 SQL Server Replication Dist.: Delivery Latency 입니다.
만약, 둘 중의 하나의 과정중에 과도한 지연시간 증가를 발견한다면, 이것은 어떤 새로운 변화가 발생하여 지연 시간을 증가 시켰는지 살펴봐야 한다는 신호입니다.
*****
관찰하여야 할 주요한 카운터는 SQL Server Buffer Manager Object: Buffer Cache Hit Ratio 입니다. 이것은 SQL서버가 데이터를 액세스 하기 위해 하드디스크가 아닌 버퍼를 얼마나 자주 참조하는가를 나타냅니다. 보다 높은 이 수치는, SQL서버가 데이터를 가져오기 위해서 하드디스크에 아주 가끔 액세스한다는 것이며, 이는 SQL서버의 성능을 극대화 시킵니다.
SQL서버를 모니터하는 다른 카운터들과는 달리, 이 카운터는 SQL서버가 다시 시작한 시점 이후부터의 버퍼 캐시 히트율의 평균 값입니다. 다른 말로, 이 카운터는 현재 시점의 측정 값이 아니라 SQL서버가 시작된 이후의 모든 날들의 평균값입니다. 현재 시점의 버퍼캐시에서 어떤일이 발생하고 있는지 정확한 자료를 얻기 원한다면, 여러분은 SQL서버를 중지 했다가 다시 시작해야만 하고, 정확한 버퍼 캐시 히트율을 확인하기 위해 SQL서버를 여러 시간 동안 일반적인 활동을 하게 내버려 둬야 합니다.
만약 최근에 SQL서버를 재 시작 하지 않았다면, 여러분이 보고 있는 버퍼 캐시 히트율은 아마도 현재 발생하는 버퍼 캐시 히트율을 위해서는 정확한 정보가 아닐 것 입니다. 또한 버퍼 캐시 히트율이 좋아 보일지라도, 오랜 시간의 평균값으로 계산되었기 때문에 실제로는 좋지 않을 지도 모릅니다.
OLTP 응용프로그램 환경에서, 이 수치는 90~95% 이상이어야 합니다. 그렇지 않다면, 여러분은 성능 향상을 위해서 서버에 RAM을 추가할 필요가 있습니다.
OLAP 응용프로그램 환경에서는, OLAP작동하는 기본특성 때문에 이 수치는 OLTP 보다 더 작을 수 있습니다. 어떤 경우라도, 더 많은 RAM은 SQL서버의 OLAP 활동의 성능을 증가 시킬것입니다.
*****
이 두 카운터를 관측하는걸 고려하십시요. SQLServer:Memory Manager: Total Server Memory (KB) and SQLServer:Memory Manager: Target Server Memory (KB). 첫번째 카운터 SQLServer:Memory Manager: Total Server Memory (KB) 는 mssqlserver서비스가 메모리를 얼마나 사용하고 있는가를 말해줍니다. 이것은 SQL서버 Bpool영역으로 커밋된 전체 버퍼수를 포함하고, ‘OS in Use’ 로 표시되는 OS버퍼들도 포함합니다.
두번째 카운터, SQLServer:Memory Manager: Target Server Memory (KB)는 SQL서버가 얼마나 많은 메모리를 가용할 수 있는가를 나타냅니다. 이는 SQL서버가 시작시에 예약한 버퍼수에 기초합니다.
만약, Total Server Memory (KB)이 Target Server Memory (KB)보다 작다면, 이는 SQL서버가 충분한 메모리를 가졌고, 효율적으로 사용하고 있다는 것을 의미합니다. 반면에 Total Server Memory (KB)이 Target Server Memory (KB)보다 크거나 같다면, 이는 SQL서버가 메모리 압박을 받고 있고, 더 많은 물리적 메모리에 액세스 하고 있음을 나타냅니다.
*****
디스크로부터 데이터를 읽는 대신에 버퍼 캐시로부터 데이터를 가져온다면 SQL서버는 보다 적은 자원으로 보다 훨씬 더 빠르게 수행합니다. 몇몇 경우에, 메모리 집중적인 명령들로 인해 데이터 페이지들이 이상적으로 플러시 되기 전에 캐시 밖으로 밀려 나가기도 한다. 이는 버퍼 캐시가 충분히 크지 않거나 메모리 집중적인 명령의 작업을 위한 더 많은 버퍼 공간 요구에 의해 발생할 수 있습니다. 이런 경우에는 버퍼에 추가 적인 공간을 만들기 위해서 플러시 된 데이터 페이지들은 디스크로부터 읽혀지게 되며, 성능에 안 좋은 영향을 미치게 됩니다.
여러분들의 SQL서버가 이러한 문제를 가지고 있는지 확인 하기 위한 3개의 SQL 서버 카운터가 있습니다.
· SQL Server Buffer Mgr: Page Life Expectancy : 이 성능 카운터는 데이터 페이지가 얼마나 오랫동안 버퍼공간에 머무르는지를 평균적으로 나타내 줍니다. 만약 이 값이 300초 보다 작은 값을 보인다면, 여러분의 SQL서버는 성능의 극대화를 위해서 추가적인 메모리가 필요함을 잠재적으로 나타내는 것입니다.
· SQL Server Buffer Mgr: Lazy Writes/Sec : 이 카운터는 버퍼 공간을 비우기 위해서 지연기록기 프로세스가 더티 페이지들을 버퍼공간에서 디스크로 초당 얼마나 많이 옮겼는지 나타냅니다. 일반적으로 말하자면, 이 항목은 높은 값(초당 20정도)이어서는 안됩니다. 이상적으로, 0에 가까워야 합니다. 만약 이 값이 0이라면, 여러분의 SQL서버는 아주 큰 버퍼 공간을 가지고 있고, 일정한 체크 포인트가 발생하여 더티페이지가 반환되기를 기다리는 대신에, 더티페이지 반환을 하지 않아도 됨을 나타냅니다. 만약 이 값이 높다면, 보다 더 많은 메모리가 필요함을 나타냅니다.
· SQL Server Buffer Mgr: Checkpoint Pages/Sec: 체크포인트가 발생할 때, 모든 더티 페이지들은 디스크에 쓰여 집니다. 이것은 일반적인 절차이며, 체크포인트가 처리되는 동안에 이 카운터가 발생하는 근원이 됩니다. 시간에 걸쳐서 이 카운터의 높은 값을 보길 원치 않으실 것입니다. 이는 SQL서버의 귀중한 자원을 많이 사용할 수 있는 체크포인트 프로세스가 보다 더 자주 실행됨을 나타냅니다. 만약 이 값이 높은 값을 가진다면, 빈번한 체크 포인트 발생을 줄이기 위해서 더 많은 RAM을 추가할 것을 고려하시거나, SQL서버의 구성옵션 중에 ‘복구 간격(recovery interval)’ 옵션 값을 늘려주십시오.
이러한 성능 모니터 카운터들은 “메모리 부족”의 잠재적인 진단을 위해서 고려되거나, 고도화하거나, 정제하기 위해 사용되어야 합니다.
*****
래치는 본질적으로 “경량 잠금” 입니다. 기술적인 관점에서, 래치는 가볍고, 짧은 동기화 개체입니다. 래치는 마치 잠금 처럼 동작하고, 예상치 않은 변화로부터 데이터를 보호하기 위한 목적을 가지고 있습니다. 예를 들면, 하나의 행이 버퍼로부터 SQL서버의 저장소 엔진으로 이동될 때, 이 매우 짧은 시간 동안의 이동 중에 행 내부의 데이터 변형을 방지하기 위해서 SQL서버에 의해서 래치가 사용되어 집니다.
마치 잠금과 같이, 래치는 데이터베이스의 행들에 대해 접근하지 못하게 SQL서버를 방해 할 수 있고, 이는 성능에 안 좋은 영향을 줍니다. 이러한 이유 때문에 여러분은 래치 시간을 최소화하길 원하실 것입니다.
SQL서버는 래치의 활동을 측정하기 위한 3가지 다른 방법을 제공합니다.
· Average Latch Wait Time (ms): 래치 요청들을 위해 대기해야 하는 시간입니다. 이는 오직 대기해야 하는 래치 요청들에 대한 측정값입니다. 대부분의 경우에 대기가 없습니다. 따라서, 이 값은 모든 래치에 대한 것이 아니라, 대기 해야 하는 래치에 대해서만 적용된 값임을 유념하십시오.
· Latch Waits/sec: 이 값은 즉시 승인 받지 못한 래치 요청수입니다. 다시 말해서, 1초 동안에 대기 해야 했던 총 래치의 수입니다. 따라서, 이는 Average Latch Wait Time으로 부터 측정된 래치들 입니다.
· Total Latch Wait Time (ms): 이는 지난 초 동안의 총 래치 대기 시간 (ms) 입니다.
이 값을 읽을 때, 성능카운터에서 배율을 정확히 읽었는지 확인하십시오. 배율은 카운터 값마다 다르게 표시될 수 있습니다.
제 경험에 비추어 볼 때, Average Latch Wait Rime 카운터는 거의 변함이 없습니다. 반면에 다른 두 개의 카운터(Latch Waits/sec , Total Latch Wait Time (ms)) 는 SQL서버가 뭘 하느냐에 따라서 큰 변동폭을 보일 수 있습니다.
각각의 서버가 약간씩 다르기 때문에, 래치 활동도 각 서버마다 다릅니다. 전형적인 작업부하가 있을 때, 이 카운터에 대한 기준 값을 확보해 두시는 것은 아주 좋은 생각입니다. 이는 현재 어떤 일이 발생하고 있는가에 대해서 래치 활동이 평상시 보다 많은지 적은지에 대한 비교자료가 될 것입니다.
래치 활동이 기대치 보다 높다면, 이는 종종 하나 혹은 두 개의 잠재적인 문제점들을 나타냅니다. 첫째, 여러분의 SQL서버가 보다 많은 메모리를 사용할 수 있음을 의미할지도 모릅니다. 래치 활동이 높다면, 버퍼 캐시 히트 비율이 어떤지 확인하십시오. 이 값이 99% 이하라면, 보다 더 많은 양의 메모리가 서버의 성능에 도움을 줄 것입니다. 만약 99% 이상이라면, 문제를 유발하는 것은 IO시스템일수도 있습니다. 빠른 IO시스템은 서버 성능에 유리합니다.
래치에 대해서 보다 더 많이 배우고, 실험해보고 싶으시면, 여기 두 개의 명령이 있습니다.
SELECT * FROM SYSPROCESSES WHERE waittime>0 and spid>50
이 쿼리는 현재 대기상태에 있는 waittype, waittime, lastwaittype, waitresource, SPID들을 표시해 줍니다. lastwaittype은 래치 종류를, waitresource는 SPID가 어떤 개체를 위해 대기 중인지를 알려줍니다. 이 쿼리를 실행하게 되면, 실행 시점에 대기가 발생하고 있지 않다면, 아무런 결과도 얻지 못 할 지도 모릅니다. 그러나 계속해서 실행하다 보면, 결국 몇몇 결과를 얻게 될 것입니다.
DBCC SQLPerf (waitstats, clear) --대기 통계초기화
DBCC SQLPerf (waitstats) -- SQL서버 재시작(대기 통계 초기화) 이후의 대기 통계정보
이 쿼리는 대기유형, 대기시간과 함께 현재의 래치들을 나타내줍니다. 여러분은 아마도 통계정보를 초기화하길 원할 겁니다. 그런 다음에는 어떤 래치가 가장 많은 시간을 차지하는지 알기 위하여, DBCC SQLPerf(waitstats)명령을 짧은 시간에 걸쳐서 정기적으로 실행하십시오.
이 글은 스프링노트에서 작성되었습니다.
'Peformance Tuning' 카테고리의 다른 글
| 저장 프로시저 및 함수의 마법 깨트리기 #1 (0) | 2010.06.04 |
|---|---|
| 성능::ReadTrace 사용법 (0) | 2010.06.03 |
| 성능::엑셀이용분석하기 (0) | 2010.06.03 |
| read-ahead는 무었인가? (0) | 2009.12.03 |
Problem
In a previous tip, "Setting up Performance Monitor to always collect performance statistics" I wrote about how to collect performance monitor data, but once you have the data then what do you do with it. In this tip I will show you how I use Excel to analyze the data to help determine where your bottlenecks may be and also an easy way to create quick reports and charts for your SQL Servers.
Solution
Before we get started here are a couple of things you will need for this tip.
- Microsoft Excel 2007 - you also can use Excel 2003 or earlier version but for this tip, I used the latest version.
- Perfmon trace files at least one day in "csv" format. - if you have a file in "blg" format, you can easily convert it by using the "relog" tool. When I get a chance, I will write another tip about the relog tool and other tools that work well with Perfmon. To collect data using Perfmon you can review this tip Setting up Performance Monitor to always collect performance statistics.
Step 1: Open the csv file
Once you have collected the performance data you can open the csv file using Excel and you should see data similar to the following.
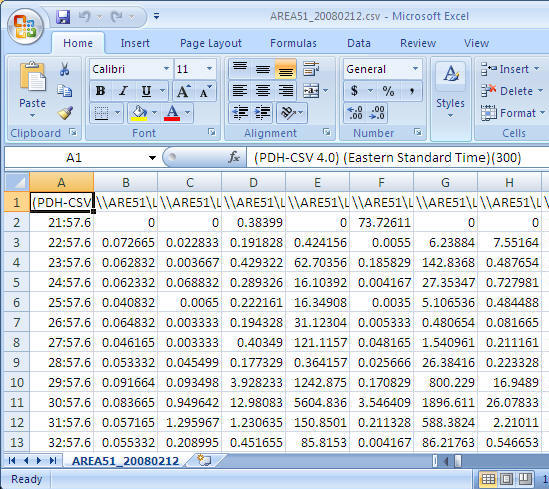
Step 2: Adjust the format
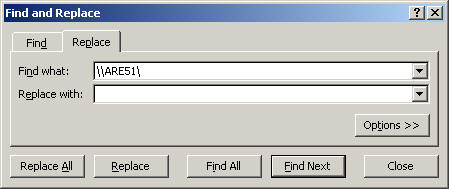
To allow easy reporting of the data there are a few things that I do to adjust the data.
- Replace server name with an empty string - it helps to make reading the counter names easier. In this case I am replacing "\\AREA51\" the name of my server to nothing. (This is optional, but recommended)
- Cell - A1: Replace "(PDH-CSV 4.0) (Eastern Standard Time)(300)" with "Time" (Optional, but recommended)
- Delete the second row - very often, the first data row has bad data
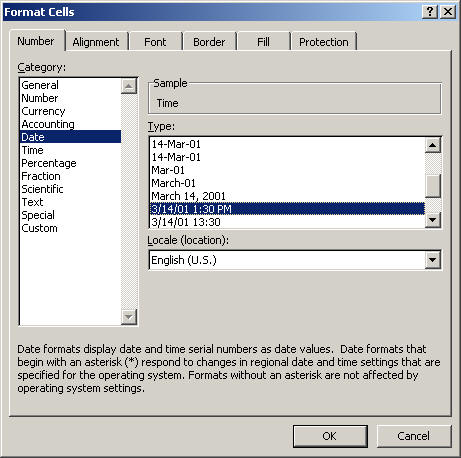
- Change COLUMN A cell format to "date time"
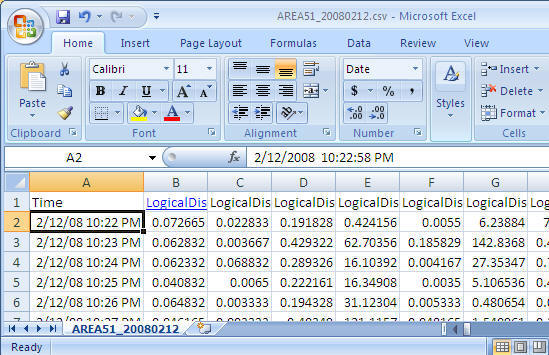
Final look before we start using it the data.
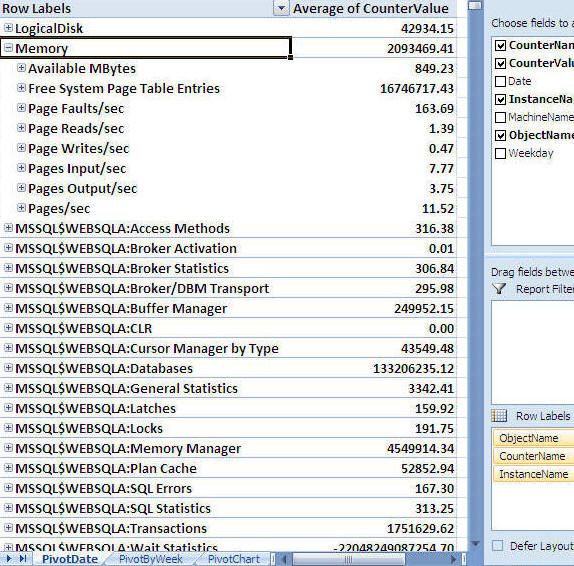
Step 3: Create PivotTable with PivotChart
- From the Insert menu select PivotTable and then select PivotChart as shown below
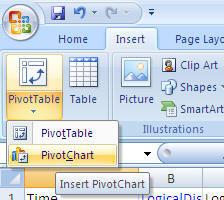
-
Take the default settings and click "OK"
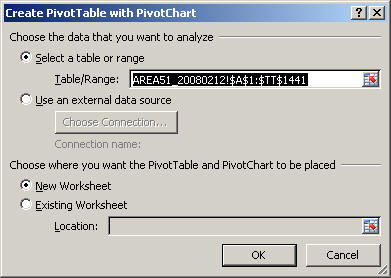
-
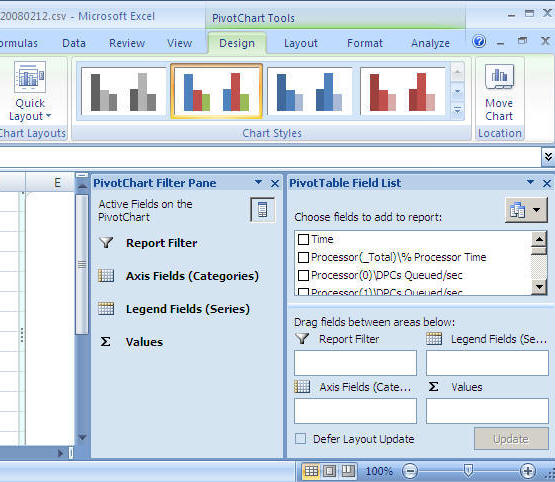
After you select the above you will get a screen similar to the following. (to get a bigger workspace area you can close the "PivotChart Filter Pane")
Step 4: Let's generate our first graph
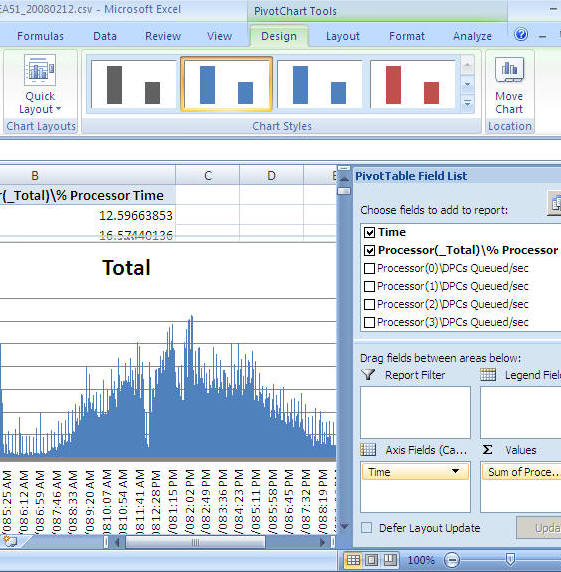
For this example we will look at CPU
- From the "PivotTable Field List" select "Time" and drag it into the "Axis Fields (Categories)" area
- From the "PivotTable Field List" select "Process(_Total)\% Process Time" and drag it into the "Values" area
- At this point you will have a graph similar to the one shown below
-
You can now just select the chart and copy and paste it into a report, an email, Word document etc... as shown below
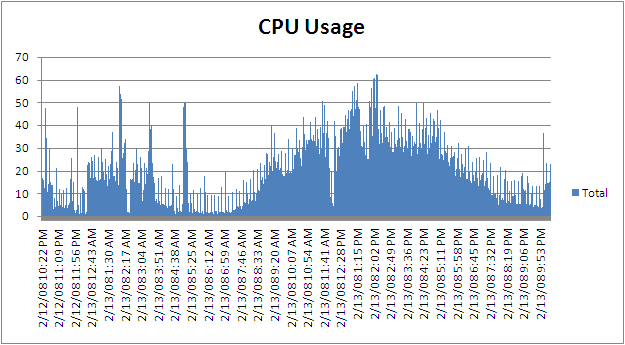
-
If you want to change it from processor time to batch requests you can remove "Process(_Total)\% Process Time" and select "SQLServer:SQL Statistics\Batch Requests/sec" and you will get a chart like below
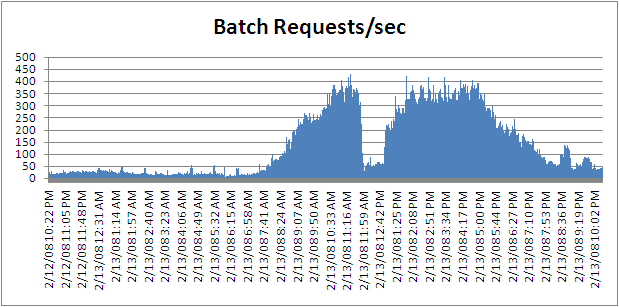
Next Steps
- There are many ways to extend this reporting to make it more useful for both short term and long term needs. In order to do that, it is easier to load the Perfmon data into SQL Server and use the power of SQL Server along with Excel to generate the reports.
- By using the "relog" tool, you can load the Perfmon data directly into SQL Server
- By using the "logman" tool, you can setup Perfmon to store the performance data directly to SQL Server
- To get you started you can download a sample CSV file here with a lot of performance counters
- Here are a few more examples of reports and charts you can create
Sample 1
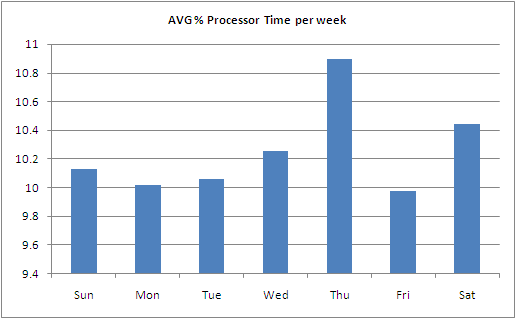
Sample 2
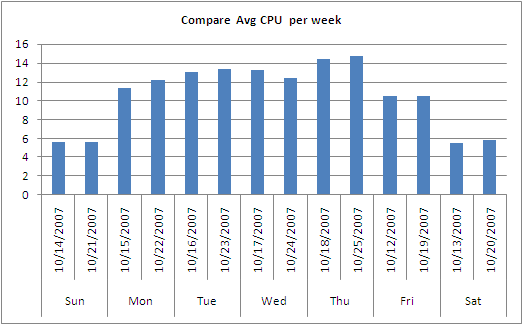
Sample 3
Related Tips
Forum Posts
- Discuss this tip: http://blogs.mssqltips.com/forums/t/640.aspx
- There are 0 comments for this tip
이 글은 스프링노트에서 작성되었습니다.
'Peformance Tuning' 카테고리의 다른 글
| 성능::ReadTrace 사용법 (0) | 2010.06.03 |
|---|---|
| SQL서버 성능카운터 (0) | 2010.06.03 |
| read-ahead는 무었인가? (0) | 2009.12.03 |
| DeadLock 예제,재 실행하기 (0) | 2009.11.24 |
쉬운것 같으면서도 가끔 PK 생성때 중복 데이터가 있어서 안될 경우.
그게 또 대용량 데이터라면.. 참.. 다시 데이터를 넣거나. 아니면 임시에 넣었다가 지우거나 그랬는데..
rowcount 쓰는 법이랑 2005의 row_number()를 이용할 수 있음.
Sometimes, in SQL, it is the routine operations that turn out to be the trickiest for a DBA or developer. The cleaning up, or de-duplication, of data is one of those. András runs through a whole range of methods and tricks, and ends with a a fascinating technique using CTE, ROW_NUMBER() and DELETE
Only rarely will you need to remove duplicate entries from a table on a production database. The tables in these databases should have a constraint, such as a primary key or unique constraint, to prevent these duplicate entries occurring in the first place. However, last year at SQL Bits 3 in Reading, I asked my audience how many of them needed to remove duplicate rows from a table, and almost eighty percent raised a hand.
How is it that duplicates can get into a properly-designed table? Most commonly, this is due to changes in the business rules that define what constitutes a duplicate, especially after the merging of two different systems. In this article, I will look at some ways of removing duplicates from tables in SQL Server 2000 and later versions, and at some of the problems that may arise.
Checking for Duplicates
On any version of SQL Server, you can identify duplicates using a simple query, with GROUP BY and HAVING, as follows:
DECLARE @table TABLE (data VARCHAR(20))
INSERT INTO @table VALUES ('not duplicate row')
INSERT INTO @table VALUES ('duplicate row')
INSERT INTO @table VALUES ('duplicate row')
SELECT data
, COUNT(data) nr
FROM @table
GROUP BY data
HAVING COUNT(data) > 1
The result indicates that there are two occurrences of the row containing the “duplicate row” text:
data nr
-------------------- -----------
duplicate row 2
Removing Duplicate Rows in SQL Server
The following sections present a variety of techniques for removing duplicates from SQL Server database tables, depending on the nature of the table design.
Tables with no primary key
When you have duplicates in a table that has no primary key defined, and you are using an older version of SQL Server, such as SQL Server 2000, you do not have an easy way to identify a single row. Therefore, you cannot simply delete this row by specifying a WHERE clause in a DELETE statement.
You can, however, use the SET ROWCOUNT 1 command, which will restrict the subsequent DELETE statement to removing only one row. For example:
DECLARE @table TABLE (data VARCHAR(20))
INSERT INTO @table VALUES ('not duplicate row')
INSERT INTO @table VALUES ('duplicate row')
INSERT INTO @table VALUES ('duplicate row')
SET ROWCOUNT 1
DELETE FROM @table WHERE data = 'duplicate row'
SET ROWCOUNT 0
In the above example, only one row is deleted. Consequently, there will be one remaining row with the content “duplicate row”. If you have more than one duplicate of a particular row, you would simply adjust the ROWCOUNT accordingly. Note that after the delete, you should reset the ROWCOUNT to 0 so that subsequent queries are not affected.
To remove all duplicates in a single pass, the following code will work, but is likely to be horrendously slow if there are a large number of duplicates and table rows:
DECLARE @table TABLE (data VARCHAR(20))
INSERT INTO @table VALUES ('not duplicate row')
INSERT INTO @table VALUES ('duplicate row')
INSERT INTO @table VALUES ('duplicate row')
SET NOCOUNT ON
SET ROWCOUNT 1
WHILE 1 = 1
BEGIN
DELETE FROM @table
WHERE data IN (SELECT data
FROM @table
GROUP BY data
HAVING COUNT(*) > 1)
IF @@Rowcount = 0
BREAK ;
END
SET ROWCOUNT 0
When cleaning up a table that has a large number of duplicate rows, a better approach is to select just a distinct list of the duplicates, delete all occurrences of those duplicate entries from the original and then insert the list into the original table.
DECLARE @table TABLE(data VARCHAR(20))
INSERT INTO @table VALUES ('not duplicate row')
INSERT INTO @table VALUES ('duplicate row')
INSERT INTO @table VALUES ('duplicate row')
INSERT INTO @table VALUES ('second duplicate row')
INSERT INTO @table VALUES ('second duplicate row')
SELECT data
INTO #duplicates
FROM @table
GROUP BY data
HAVING COUNT(*) > 1
-- delete all rows that are duplicated
DELETE FROM @table
FROM @table o INNER JOIN #duplicates d
ON d.data = o.data
-- insert one row for every duplicate set
INSERT INTO @table(data)
SELECT data
FROM #duplicates
As a variation of this technique, you could select all the data, without duplicates, into a new table, delete the old table, and then rename the new table to match the name of the original table:
CREATE TABLE duplicateTable3(data VARCHAR(20))
INSERT INTO duplicateTable3 VALUES ('not duplicate row')
INSERT INTO duplicateTable3 VALUES ('duplicate row')
INSERT INTO duplicateTable3 VALUES ('duplicate row')
INSERT INTO duplicateTable3 VALUES ('second duplicate row')
INSERT INTO duplicateTable3 VALUES ('second duplicate row')
SELECT DISTINCT data
INTO tempTable
FROM duplicateTable3
GO
TRUNCATE TABLE duplicateTable3
DROP TABLE duplicateTable3
exec sp_rename 'tempTable', 'duplicateTable3'
In this solution, the SELECT DISTINCT will select all the rows from our table except for the duplicates. These rows are immediately inserted into a table named tempTable. This is a temporary table in the sense that we will use it to temporarily store the unique rows. However, it is not a true temporary table (i.e. one that lives in the temporary database), because we need the table to exist in the current database, so that it can later be renamed, using sp_Rename.
The sp_Rename command is an absolutely horrible way of renaming textual objects, such as stored procedures, because it does not update all the system tables consistently. However, it works well for non-textual schema objects, such as tables.
Note that this solution is usually used on table that has no primary key. If there is a key, and there are foreign keys referencing the rows that are identified as being duplicates, then the foreign key constraints need to be dropped and re-created again during the table swap.
Tables with a primary key, but no foreign key constraints
If your table has a primary key, but no foreign key constraints, then the following solution offers a way to remove duplicates that is much quicker, as it entails less iteration:
DECLARE @table TABLE(
id INT IDENTITY(1, 1)
, data VARCHAR(20)
)
INSERT INTO @table VALUES ('not duplicate row')
INSERT INTO @table VALUES ('duplicate row')
INSERT INTO @table VALUES ('duplicate row')
WHILE 1 = 1
BEGIN
DELETE FROM @table
WHERE id IN (SELECT MAX(id)
FROM @table
GROUP BY data
HAVING COUNT(*) > 1)
IF @@Rowcount = 0
BREAK ;
END
Unfortunately, this sort of technique does not scale well.
If your table has a reliable primary key, for example one that has an assigned a value that can be used in a comparison, such as a numeric value in a column with the IDENTITY property enabled, then the following approach is probably the neatest and best. Essentially, it deletes all the duplicates except for the one with the highest value for the primary key. If a table has a unique column such as a number or integer, that will reliably return just one value with MAX() or MIN(), then you can use this technique to identify the chosen survivor of the group of duplicates.
DECLARE @table TABLE (
id INT IDENTITY(1, 1)
, data VARCHAR(20)
)
INSERT INTO @table VALUES ('not duplicate row')
INSERT INTO @table VALUES ('duplicate row')
INSERT INTO @table VALUES ('duplicate row')
INSERT INTO @table VALUES ('second duplicate row')
INSERT INTO @table VALUES ('second duplicate row')
DELETE FROM @table
FROM @table o
INNER JOIN ( SELECT data
FROM @table
GROUP BY data
HAVING COUNT(*) > 1
) f ON o.data = f.data
LEFT OUTER JOIN ( SELECT [id] = MAX(id)
FROM @table
GROUP BY data
HAVING COUNT(*) > 1
) g ON o.id = g.id
WHERE g.id IS NULL
This can be simplified even further, though the logic is rather harder to follow.
DELETE FROM f
FROM @table AS f INNER JOIN @table AS g
ON g.data = f.data
AND f.id < g.id
Tables that are referenced by a Foreign Key
If you've you’ve set up your constraints properly then you will be unable to delete duplicate rows from a table that is referenced by another table, using the above techniques unless you have specified cascading deletes in the foreign key constraints.
You can alter existing foreign key constraints by adding a cascading delete on the foreign key constraint. This means that rows in other tables that refer to the duplicate row via a foreign key constraint will be deleted. Because you will lose the referenced data as well as the duplicate, you are more likely to wish to save the duplicate data in its entirety first in a holding table. When you are dealing with real data, you are likely to need to identify the duplicate rows that are being referred to, and delete the duplicates that are not referenced, or merge duplicates and update the references. This task will probably have to be done manually in order to ensure data integrity.
Tables with columns that cannot have a UNIQUE constraint
Sometimes, of course, you may have columns on which you cannot define a unique constraint, or you cannot even use the DISTINCT keyword. Large object types, like NTEXT, TEXT and IMAGE in SQL Server 2000 are good examples of this. These are data types that cannot be compared, and so the above solutions would not work.
In these situations, you will need to add an extra column to the table that you could use as a surrogate key. Such a surrogate key is not derived from the application data. Its value may be automatically generated, similarly to the identity columns in our previous examples. Unfortunately, in SQL Server, you cannot add an identity column to a table as part of the ALTER TABLE command. The only way to add such a column is to rebuild the table, using SELECT INTO and the IDENTITY() function, as follows:
CREATE TABLE duplicateTable4 (data NTEXT)
INSERT INTO duplicateTable4 VALUES ('not duplicate row')
INSERT INTO duplicateTable4 VALUES ('duplicate row')
INSERT INTO duplicateTable4 VALUES ('duplicate row')
INSERT INTO duplicateTable4 VALUES ('second duplicate row')
INSERT INTO duplicateTable4 VALUES ('second duplicate row')
SELECT IDENTITY( INT, 1,1 ) AS id,
data
INTO duplicateTable4_Copy
FROM duplicateTable4
The above will create the duplicateTable4_Copy table. This table will have an identity column named id, which will already have unique numeric values set. Note that although we are creating an Identity column, uniqueness is not enforced in this case; you will need to add a unique index or define the id column as a primary key.
Using a cursor
People with application development background would consider using a cursor to try to eliminate duplicates. The basic idea is to order the contents of the table, iterate through the ordered rows, and check if the current row is equal to the previous row. If it does, then delete the row. This solution could look like the following in T-SQL:
CREATE TABLE duplicateTable5 (data varchar(30))
INSERT INTO duplicateTable5 VALUES ('not duplicate row')
INSERT INTO duplicateTable5 VALUES ('duplicate row')
INSERT INTO duplicateTable5 VALUES ('duplicate row')
INSERT INTO duplicateTable5 VALUES ('second duplicate row')
INSERT INTO duplicateTable5 VALUES ('second duplicate row')
DECLARE @data VARCHAR(30),
@previousData VARCHAR(30)
DECLARE cursor1 CURSOR SCROLL_LOCKS
FOR SELECT data
FROM duplicateTable5
ORDER BY data
FOR UPDATE
OPEN cursor1
FETCH NEXT FROM cursor1 INTO @data
WHILE @@FETCH_STATUS = 0
BEGIN
IF @previousData = @data
DELETE FROM duplicateTable5
WHERE CURRENT OF cursor1
SET @previousData = @data
FETCH NEXT FROM cursor1 INTO @data
END
CLOSE cursor1
DEALLOCATE cursor1
The above script will not work, because once you apply the ORDER BY clause in the cursor declaration the cursor will become read-only. If you remove the ORDER BY clause, then there will be no guarantee that the rows will be in order, and checking two subsequent rows would no longer be sufficient to identify duplicates. Interestingly, since the above example creates a small table where all the rows fit onto a single database page and duplicate rows are inserted in groups, removing the ORDER BY clause does make the cursor solution work. It will fail, however, with any table that is larger and has seen some modifications.
New Techniques for Removing Duplicate Rows in SQL Server 2005
SQL Server 2005 has introduced the row_number() function, which provides an alternative means of identifying duplicates. Rewriting the first example, for tables with no primary key, we can now assign a row number to each row in a duplicate group, with a command such as:
DECLARE @duplicateTable4 TABLE (data VARCHAR(20))
INSERT INTO @duplicateTable4 VALUES ('not duplicate row')
INSERT INTO @duplicateTable4 VALUES ('duplicate row')
INSERT INTO @duplicateTable4 VALUES ('duplicate row')
INSERT INTO @duplicateTable4 VALUES ('second duplicate row')
INSERT INTO @duplicateTable4 VALUES ('second duplicate row')
SELECT data
, row_number() OVER ( PARTITION BY data ORDER BY data ) AS nr
FROM @duplicateTable4
The result will show:
data nr
-------------------- --------------------
duplicate row 1
duplicate row 2
not duplicate row 1
second duplicate row 1
second duplicate row 2
In the above example, we specify an ordering and partitioning for the row_number() function. Note that the row_number() is a ranking window function, therefore the ORDER BY and the PARTITION BY in the OVER clause are used only to determine the value for the nr column, and they do not affect the row order of the query. Also, while the above is similar to our previous GROUP BY clause, there is a big difference concerning the returned rows. With GROUP BY you must use an aggregate on the columns that are not listed after the GROUP BY. With the OVER clause there is no such restriction, and you can get access to the individual rows in the groups specified by the PARTITION BY clause. This gives us access to the individual duplicate rows, so we can get not only the number of occurrences, but also a sequence number for the individual duplicates. To filter out the duplicate rows only, we could just put the above query into a CTE or a subquery. The CTE approach is as follows:
DECLARE @duplicateTable4 TABLE (data VARCHAR(20))
INSERT INTO @duplicateTable4 VALUES ('not duplicate row')
INSERT INTO @duplicateTable4 VALUES ('duplicate row')
INSERT INTO @duplicateTable4 VALUES ('duplicate row')
INSERT INTO @duplicateTable4 VALUES ('second duplicate row')
INSERT INTO @duplicateTable4 VALUES ('second duplicate row')
;
WITH numbered
AS ( SELECT data
, row_number() OVER ( PARTITION BY data ORDER BY data ) AS nr
FROM @duplicateTable4
)
SELECT data
FROM numbered
WHERE nr > 1
This is not really any different from what we could do on SQL Server 2000. However, here comes an absolutely amazing feature in SQL Server 2005 and later: We can refer to, and identify, a duplicate row based on the row_number() column and then, with the above CTE expression, we can use a DELETE statement instead of a SELECT, and directly remove the duplicate entries from our table.
We can demonstrate this technique with the following example:
DECLARE @duplicateTable4 TABLE (data VARCHAR(20))
INSERT INTO @duplicateTable4 VALUES ('not duplicate row')
INSERT INTO @duplicateTable4 VALUES ('duplicate row')
INSERT INTO @duplicateTable4 VALUES ('duplicate row')
INSERT INTO @duplicateTable4 VALUES ('second duplicate row')
INSERT INTO @duplicateTable4 VALUES ('second duplicate row')
;
WITH numbered
AS ( SELECT data
, row_number() OVER ( PARTITION BY data ORDER BY data ) AS nr
FROM @duplicateTable4
)
DELETE FROM numbered
WHERE nr > 1
This solution will even work with large objects, if you stick to the new large object types introduced in SQL Server 2005: i.e. use VARCHAR(MAX) instead of TEXT, NVARCHAR(MAX) instead of NTEXT, and VARBINARY(MAX) instead of IMAGE. These new types are comparable to the deprecated TEXT, NTEXT and IMAGE, and they have the advantage that you will be able to use them with both DISTINCT and row_number().
I find this last solution, using CTE, ROW_NUMBER() and DELETE, fascinating. Partly because now we can identify rows in a table when there is no other alternative way of doing it, and partly because it is a solution to a problem that should not, in theory, exist at all since production tables will have a unique constraint or a primary key to prevent duplicates getting into the table in the first place.
This article has been viewed 9208 times.
이 글은 스프링노트에서 작성되었습니다.
'T-SQL' 카테고리의 다른 글
| T_SQL::미 사용 Table (0) | 2010.06.15 |
|---|---|
| 데이터베이스 사이즈 (0) | 2010.06.04 |
| T-SQL::DB_Restore_move_to (0) | 2010.06.03 |
| T-SQL::Convert hex value to String 32bit (0) | 2010.06.03 |
 Prev
Prev

