'성능'에 해당되는 글 11건
- 2010.06.03 성능::ReadTrace 사용법
- 2010.06.03 성능::엑셀이용분석하기
- 2010.04.05 CPU 할당된 Task 상세
- 2010.03.28 Admin::SQL Server wait types
- 2009.12.03 read-ahead는 무었인가?
- 2009.11.24 DeadLock 예제,재 실행하기
- 2009.11.13 성능:: 강제 매개변수화 Forced Parameterization
- 2009.11.12 SQL서버 성능counter
- 2009.11.10 Lock::Trace Flag 1204
- 2009.11.09 쿼리 Plan을 그래프로 보기
- 2009.07.20 DeadLock 발생 원인 찾기
사용법
- --===================================
-- READ TRACE
--===================================
ReadTrace -I파일경로 -S서버명 -dDB명 -U유저 -P패스워드
D:\Program Files\Microsoft Corporation\RML\ReadTrace.exe /?- ReadTrace version 9.00.0023 (X86)
- USAGE:
- NOTE: All command line arguments are case sensitive
- -I File name of the first .TRC file to process [REQUIRED]
- -i If specified, indicates that the .TRC file(s) to process are present inside a CAB/ZIP file with this file name
- -o Full path of directory to place output files [default is current directory]
- -S Name of SQL Server 2005 server to connect to when loading performance analysis data [default is (local)]
- -d Database to use when loading performance data [default is PerfAnalysis].
- User specified below must have CREATE DATABASE permission (if DB doesn't
- exist) or be part of the db_owner role if the database already exists.
- -E Connect to SQL using Windows Authentication [default]
- -U Connect to SQL using this user name
- -P Password for the user specified in -U option
- -a Disable performance analysis
- -f Do not produce .RML output files for each SPID
- -Q Do normalization parse using quoted_identifier OFF symantics. (Default is ON)
- -r# Read at most this # of files (including the first) [default is all files
- until a break in the rollover file sequence is detected].
- -M Mirror trace files by SPID to the specified output directory (All SPIDs
- will be output even if SPID filter is specified)
- -MF Mirror trace files by SPID to the specified output directory (Only SPIDs
- matching filter parameters will be output)
- -A 'INCLUDE or EXCLUDE' events with Applicaiton Names
- -H 'INCLUDE or EXCLUDE' events with Host Names
- -s# 'INCLUDE or EXCLUDE' events from specified SPIDs
- -b Provide a designated start time in required format 2000-05-25 11:46:20:060
- -e Provide a designated stop time in required format 2000-05-25 11:46:20:060
- -D Skip date on log file output
- -? Show usage of command line parameters
- EXAMPLES:
- ReadTrace -Iserver__sp_trace.trc -ic:\temp\traces.cab -oc:\temp\output -f
- ReadTrace -I"c:\my traces\80AllEvents.trc" -o"c:\my output"
- ReadTrace -Ioutput\SQLSRV1__sp_trace_20.trc -ic:\temp\pssdiag.zip -oc:\temp\breakout -f -r2
PSSDIAG 수집 유형
- http://support.microsoft.com/kb/830232
- http://msdn.microsoft.com/en-us/library/aa175399(SQL.80).aspx
이 글은 스프링노트에서 작성되었습니다.
'Peformance Tuning' 카테고리의 다른 글
| dm_os_performance_counters , Server/Process Information (0) | 2010.06.07 |
|---|---|
| 저장 프로시저 및 함수의 마법 깨트리기 #1 (0) | 2010.06.04 |
| SQL서버 성능카운터 (0) | 2010.06.03 |
| 성능::엑셀이용분석하기 (0) | 2010.06.03 |
Problem
In a previous tip, "Setting up Performance Monitor to always collect performance statistics" I wrote about how to collect performance monitor data, but once you have the data then what do you do with it. In this tip I will show you how I use Excel to analyze the data to help determine where your bottlenecks may be and also an easy way to create quick reports and charts for your SQL Servers.
Solution
Before we get started here are a couple of things you will need for this tip.
- Microsoft Excel 2007 - you also can use Excel 2003 or earlier version but for this tip, I used the latest version.
- Perfmon trace files at least one day in "csv" format. - if you have a file in "blg" format, you can easily convert it by using the "relog" tool. When I get a chance, I will write another tip about the relog tool and other tools that work well with Perfmon. To collect data using Perfmon you can review this tip Setting up Performance Monitor to always collect performance statistics.
Step 1: Open the csv file
Once you have collected the performance data you can open the csv file using Excel and you should see data similar to the following.
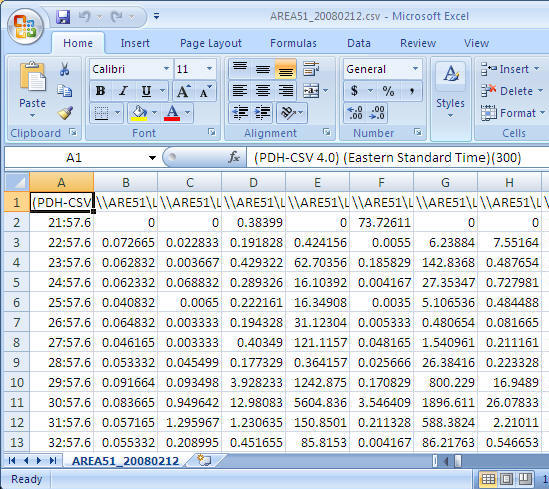
Step 2: Adjust the format
To allow easy reporting of the data there are a few things that I do to adjust the data.
- Replace server name with an empty string - it helps to make reading the counter names easier. In this case I am replacing "\\AREA51\" the name of my server to nothing. (This is optional, but recommended)
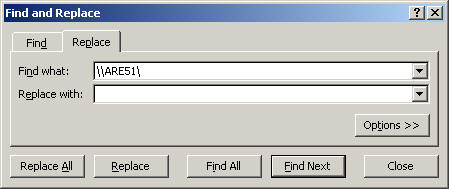
- Cell - A1: Replace "(PDH-CSV 4.0) (Eastern Standard Time)(300)" with "Time" (Optional, but recommended)
- Delete the second row - very often, the first data row has bad data
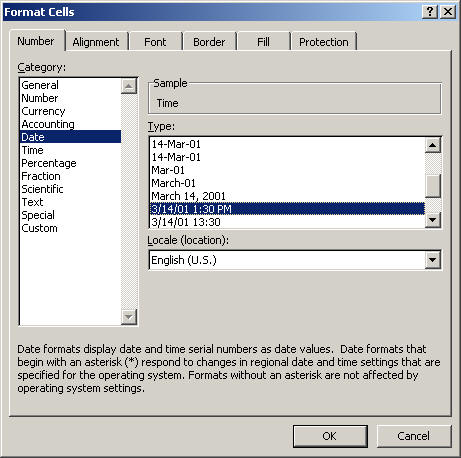
- Change COLUMN A cell format to "date time"
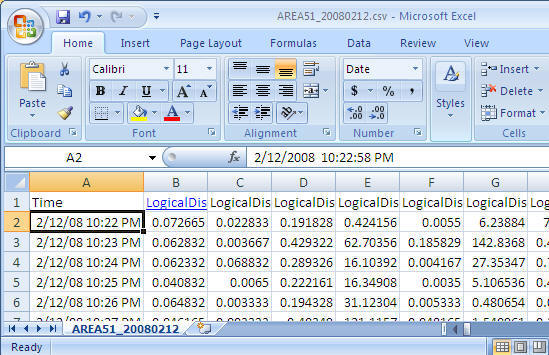
Final look before we start using it the data.
Step 3: Create PivotTable with PivotChart
- From the Insert menu select PivotTable and then select PivotChart as shown below
-
Take the default settings and click "OK"
-
After you select the above you will get a screen similar to the following. (to get a bigger workspace area you can close the "PivotChart Filter Pane")
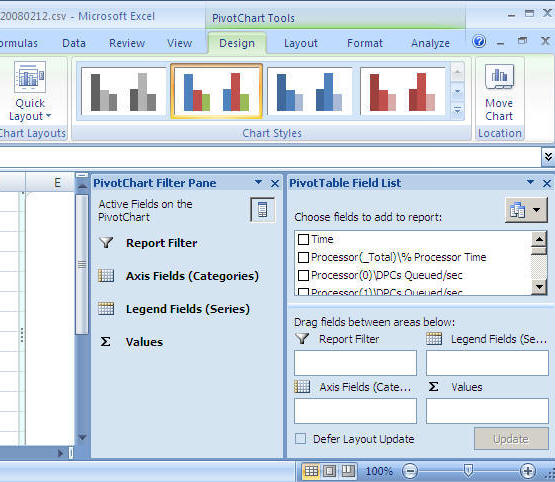
Step 4: Let's generate our first graph
For this example we will look at CPU
- From the "PivotTable Field List" select "Time" and drag it into the "Axis Fields (Categories)" area
- From the "PivotTable Field List" select "Process(_Total)\% Process Time" and drag it into the "Values" area
- At this point you will have a graph similar to the one shown below
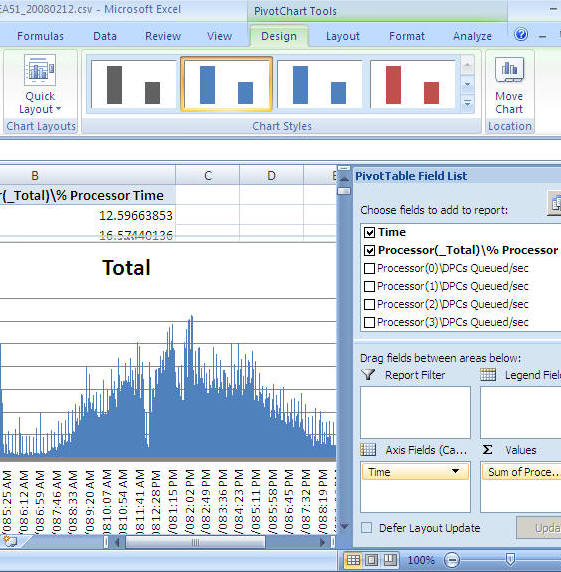
-
You can now just select the chart and copy and paste it into a report, an email, Word document etc... as shown below
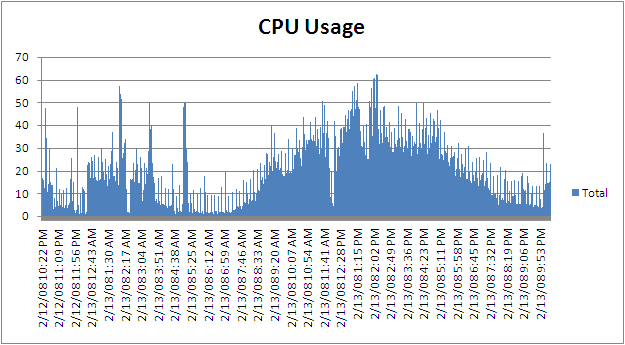
-
If you want to change it from processor time to batch requests you can remove "Process(_Total)\% Process Time" and select "SQLServer:SQL Statistics\Batch Requests/sec" and you will get a chart like below
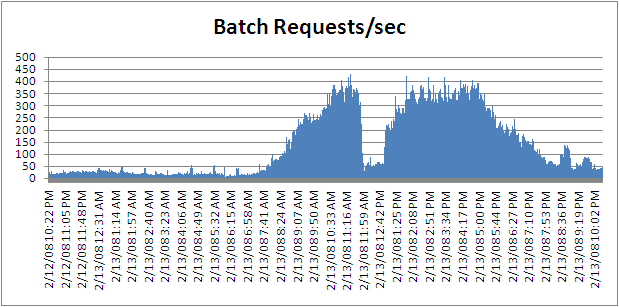
Next Steps
- There are many ways to extend this reporting to make it more useful for both short term and long term needs. In order to do that, it is easier to load the Perfmon data into SQL Server and use the power of SQL Server along with Excel to generate the reports.
- By using the "relog" tool, you can load the Perfmon data directly into SQL Server
- By using the "logman" tool, you can setup Perfmon to store the performance data directly to SQL Server
- To get you started you can download a sample CSV file here with a lot of performance counters
- Here are a few more examples of reports and charts you can create
Sample 1
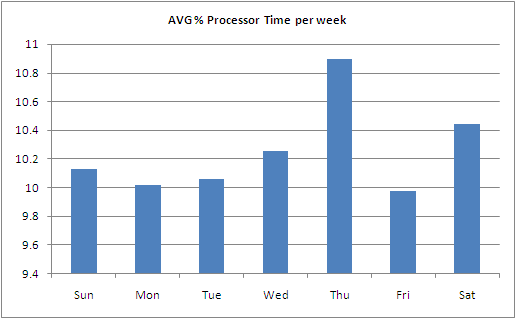
Sample 2
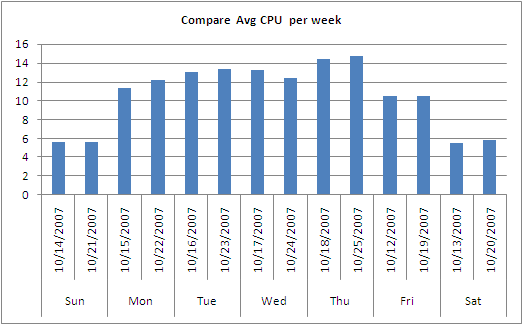
Sample 3
Related Tips
Forum Posts
- Discuss this tip: http://blogs.mssqltips.com/forums/t/640.aspx
- There are 0 comments for this tip
이 글은 스프링노트에서 작성되었습니다.
'Peformance Tuning' 카테고리의 다른 글
| 성능::ReadTrace 사용법 (0) | 2010.06.03 |
|---|---|
| SQL서버 성능카운터 (0) | 2010.06.03 |
| read-ahead는 무었인가? (0) | 2009.12.03 |
| DeadLock 예제,재 실행하기 (0) | 2009.11.24 |
[code sql] select -- object_name(sql_text.objectid) as 'SP명' ses.session_id , ses.host_name , ses.program_name , ses.client_interface_name , ses.login_name --, (case when sr.statement_end_offset = -1 -- then len(convert(nvarchar(max), sql_text.text)) * 2 -- else sr.statement_end_offset end - sr.statement_start_offset)/2) , * from sys.dm_os_schedulers as ss with (nolock) inner join sys.dm_os_tasks as st with (nolock) on ss.scheduler_id = st.scheduler_id inner join sys.dm_exec_requests as sr with (nolock) on st.request_id = sr.request_id inner join sys.dm_exec_sessions as ses with (nolock) on sr.session_id = ses.session_id cross apply sys.dm_exec_sql_text(sr.sql_handle) as sql_text where ss.scheduler_id = 24 -- cpu 번호 [/code]
'Common Admin' 카테고리의 다른 글
| Admin::VLDB성능관리#2 (0) | 2010.04.04 |
|---|---|
| Admin::VLDB성능관리#1 (0) | 2010.04.04 |
| Admin::DB 주의대상 일때. (0) | 2010.03.06 |
| SQL 2008-변경 내용 추적 (0) | 2009.12.28 |
SET STATISTICS IO ON 을 실행하고 프로시저나 쿼리를 실행할때
logical reads 820340, physical reads 0, read-ahead reads 820333 현상이 보인다. 이때 read-ahead는 무엇인가?
- read-head는 페이지를 읽을때 메모리에 이미 있으면 그 값을 반환하는것 같음
- 병렬 처리 실행에서는 사용할 수 없음
- 결국, 높다고 안 좋은건 아닌듯 함
SQL Server 2008
http://msdn.microsoft.com/en-us/library/ms191475.aspx
-
SQL Server 2000
-
SQL Server 2000 uses ReadFileScatter to perform read-ahead operations. SQL Server uses sophisticated algorithms to retrieve data pages that are going to be used in the immediate future.
For example, if you run a query that can use an index to determine applicable rows, a read-ahead may occur on the actual data pages that are needed to complete the select list. As index entries are identified, SQL Server can post OVERLAPPED (async) I/O operations for the data pages that will be used in upcoming steps of the query plan. This is how a query using a bookmark lookup operator uses read-ahead.
This example is just one of many read-ahead situations that SQL Server can use. Allowing the index searching to continue while the data page I/O is in progress maximizes the CPU and I/O of the system. The I/O is often completed by the time it is needed so other steps in the plan have direct memory access to the needed data and do not have to stall while waiting on I/O.
When a read-ahead is posted, it can be from 1 to 1,024 pages. SQL Server limits a single read-ahead request depth to 128 pages on most editions. However, Microsoft SQL Server Enterprise Edition raises the limit to 1,024 pages.
SQL Server uses the following steps to set up read-ahead.
-
Obtain the requested amount of buffers from the free list.
-
For each page:
-
Determine the in-memory status of the page by doing a hash search.
-
If found to be already in memory, set up the read-ahead request to immediately return the buffer to the free list upon I/O completion.
-
Establish the proper I/O request information for ReadFileScatter invocation.
-
Acquire I/O latch to protect buffer from further access.
-
If the page is not found in hash search then insert it into the hash table.
-
-
Issue the ReadFileScatter operation to read the data.
When the I/O operation is complete, each page is sanity checked for a valid page number and torn page errors. In addition, various other data integrity and safety checks are performed. The I/O latch is then released so the page is available for use if it is located on the hash chain. If the page was determined to be already in memory, the page is immediately discarded to the free list.
This process shows the key factors of SQL Server I/O patterns. Read-ahead goes after pages that can already be in memory or not allocated. Because SQL Server maintains the in-memory buffers and hash chains, SQL Server tracks the page’s state. Importantly, read-ahead processing opens the door for overlapping read and write requests at the hardware level.
If a page is already in memory when the read-ahead request is posted, the contiguous read is still needed and is faster than breaking up read requests into multiple physical requests. SQL Server considers the read to be unusable for the page in question, but many of the pages around it may be usable. However, if a write operation is in progress when the read is posted, the subsystem has to determine which image of the read to return. Some implementations return the current version of the page before the write is complete; others make the read wait until the write completes; and yet others return a combination, showing partially new data and partially old data. The key is that SQL Server will discard the read as unusable but the subsystem needs to maintain the proper image for subsequent read operations. The in-progress write, when completed, must be the next read image returned to the server running SQL Server.
Do not confuse read-ahead with parallel query plans. Read-ahead occurs independently of the parallel query plan selection. The parallel plan may drive I/O harder because multiple workers are driving the load, but read-ahead occurs for serial and parallel plans. To ensure that parallel workers do not work on the same data sets, SQL Server implements the parallel page supplier to help segment the data requests.
SQL Server has added increased diagnostics to report previously unreported read failures. The Microsoft Web site contains the following Knowledge Base article that provides diagnostic installation and usage instructions.
-
Additional diagnostics added to SQL Server to detect unreported read failures
http://support.microsoft.com/default.aspx?scid=kb;en-us;841776
-
'Peformance Tuning' 카테고리의 다른 글
| SQL서버 성능카운터 (0) | 2010.06.03 |
|---|---|
| 성능::엑셀이용분석하기 (0) | 2010.06.03 |
| DeadLock 예제,재 실행하기 (0) | 2009.11.24 |
| 성능:: 강제 매개변수화 Forced Parameterization (0) | 2009.11.13 |
관련글 :
Deadlock 발생시 원인과 해결법. 1. Deadlock 이유를 알고 싶으면 trace 1204 를 켜 준다. DBCC traceon(1204,-1) DBCC Tracestatus(...
deadlock이 자주 발생하는 쿼리가 있다면, 해당 원인을 찾아야 한다.
이때 T 1204를와 T 1222를 켜줘서 실행 확인이 가능하다.
1204만을 적용되었을 때는 dbcc page 번호를 통해 발생원인이 되는 객체와 인덱스를 찾으면 된다.
몇번의 deadlock이 발생후 멈추는거라면 쿼리를 반복 실행해서 원하는 결과를 얻게 할 수 있다.
이때
** DeadLock 발생 예제 **
1. 필요한 객체 생성
[code sql]
USE AdventureWorks;
GO
-- Verify that the table does not exist.
IF OBJECT_ID (N'my_sales',N'U') IS NOT NULL
DROP TABLE my_sales;
GO
-- Create and populate the table for deadlock simulation.
CREATE TABLE my_sales
(
itemid INT PRIMARY KEY,
sales INT not null
);
GO
INSERT my_sales (itemid, sales) VALUES (1, 1);
INSERT my_sales (itemid, sales) VALUES (2, 1);
GO
-- Create a stored procedure for printing error information.
CREATE PROCEDURE usp_MyErrorLog
AS
PRINT
'Error ' + CONVERT(VARCHAR(50), ERROR_NUMBER()) +
', Severity ' + CONVERT(VARCHAR(5), ERROR_SEVERITY()) +
', State ' + CONVERT(VARCHAR(5), ERROR_STATE()) +
', Line ' + CONVERT(VARCHAR(5), ERROR_LINE());
PRINT
ERROR_MESSAGE();
GO
[/code]
2. session # 1, #2에 동시에 해당 쿼리를 실행한다.
#1을 먼저 실행하게되면, #2에서 deadlock가 발생하며, 재시도 처리하고
그후 원하는 내용으로 update 된다.
[code sql]
USE AdventureWorks;
GO
-- Declare and set variable
-- to track number of retries
-- to try before exiting.
DECLARE @retry INT;
DECLARE @count INT;
SET @retry = 2;
SET @count = 0
-- Keep trying to update
-- table if this task is
-- selected as the deadlock
-- victim.
WHILE (@retry > 0)
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
UPDATE my_sales
SET sales = sales + 1
WHERE itemid = 1;
WAITFOR DELAY '00:00:8';
UPDATE my_sales
SET sales = sales + 1
WHERE itemid = 2;
SET @retry = 0;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- Check error number.
-- If deadlock victim error,
-- then reduce retry count
-- for next update retry.
-- If some other error
-- occurred, then exit
-- retry WHILE loop.
IF (ERROR_NUMBER() = 1205)
BEGIN
SET @count = @count + 1;
SET @retry = @retry - 1;
SELECT @count as '[재 실행count]', ERROR_MESSAGE()
END
ELSE
SET @retry = -1;
-- Print error information.
EXECUTE usp_MyErrorLog;
IF XACT_STATE() <> 0
ROLLBACK TRANSACTION;
END CATCH;
END; -- End WHILE loop.
SELECT @count as '[총 실행count]'
GO
[/code]
deadlock이 발생했을 경우 errorlog 기록된 내역
2009-11-24 17:30:10.780 spid4s Wait-for graph
2009-11-24 17:30:10.780 spid4s NULL
2009-11-24 17:30:10.780 spid4s Node:1
2009-11-24 17:30:10.780 spid4s KEY: 10:72057594054639616 (020068e8b274) CleanCnt:3 Mode:X Flags: 0x0
2009-11-24 17:30:10.780 spid4s Grant List 1:
2009-11-24 17:30:10.780 spid4s Owner:0x054AD9A0 Mode: X Flg:0x0 Ref:0 Life:02000000 SPID:55 ECID:0 XactLockInfo: 0x0962185C
2009-11-24 17:30:10.780 spid4s SPID: 55 ECID: 0 Statement Type: UPDATE Line #: 24
2009-11-24 17:30:10.780 spid4s Input Buf: Language Event:
-- Declare and set variable
-- to track number of retries
-- to try before exiting.
DECLARE @retry INT;
DECLARE @count INT;
SET @retry = 2;
SET @count = 1;
--Keep trying to update
-- table if this task is
-- selected as the deadlock
-- vict
2009-11-24 17:30:10.780 spid4s Requested By:
2009-11-24 17:30:10.780 spid4s ResType:LockOwner Stype:'OR'Xdes:0x09621290 Mode: X SPID:59 BatchID:0 ECID:0 TaskProxy:(0x097F8378) Value:0x54ae760 Cost:(0/208)
2009-11-24 17:30:10.780 spid4s NULL
2009-11-24 17:30:10.780 spid4s Node:2
2009-11-24 17:30:10.780 spid4s KEY: 10:72057594054639616 (010086470766) CleanCnt:2 Mode:X Flags: 0x0
2009-11-24 17:30:10.780 spid4s Grant List 1:
2009-11-24 17:30:10.780 spid4s Owner:0x054AF040 Mode: X Flg:0x0 Ref:0 Life:02000000 SPID:59 ECID:0 XactLockInfo: 0x096212B4
2009-11-24 17:30:10.780 spid4s SPID: 59 ECID: 0 Statement Type: UPDATE Line #: 23
2009-11-24 17:30:10.780 spid4s Input Buf: Language Event:
-- Declare and set variable
-- to track number of retries
-- to try before exiting.
DECLARE @retry INT;
SET @retry = 2;
-- Keep trying to update
-- table if this task is
-- selected as the deadlock
-- victim.
WHILE (@retry > 0)
BEGIN
2009-11-24 17:30:10.780 spid4s Requested By:
2009-11-24 17:30:10.780 spid4s ResType:LockOwner Stype:'OR'Xdes:0x09621838 Mode: X SPID:55 BatchID:0 ECID:0 TaskProxy:(0x0983C378) Value:0x54adc40 Cost:(0/208)
2009-11-24 17:30:10.780 spid4s NULL
2009-11-24 17:30:10.780 spid4s Victim Resource Owner:
2009-11-24 17:30:10.780 spid4s ResType:LockOwner Stype:'OR'Xdes:0x09621838 Mode: X SPID:55 BatchID:0 ECID:0 TaskProxy:(0x0983C378) Value:0x54adc40 Cost:(0/208)
2009-11-24 17:30:10.780 spid15s deadlock-list
2009-11-24 17:30:10.780 spid15s deadlock victim=process2e58e38
2009-11-24 17:30:10.780 spid15s process-list
2009-11-24 17:30:10.780 spid15s process id=process2e58e38 taskpriority=0 logused=208 waitresource=KEY: 10:72057594054639616 (010086470766) waittime=3978 ownerId=347267 transactionname=user_transaction lasttranstarted=2009-11-24T17:30:03.803 XDES=0x9621838 lockMode=X schedulerid=2 kpid=9648 status=suspended spid=55 sbid=0 ecid=0 priority=0 transcount=2 lastbatchstarted=2009-11-24T17:30:03.783 lastbatchcompleted=2009-11-24T17:30:03.780 clientapp=Microsoft SQL Server Management Studio - 쿼리 hostname=최보라 hostpid=8252 loginname=sa isolationlevel=read committed (2) xactid=347267 currentdb=10 lockTimeout=4294967295 clientoption1=671090784 clientoption2=390200
2009-11-24 17:30:10.780 spid15s executionStack
2009-11-24 17:30:10.780 spid15s frame procname=adhoc line=24 stmtstart=38 sqlhandle=0x020000007245e338daab90ce8e17c9bb5e80187b4d642c14
2009-11-24 17:30:10.780 spid15s UPDATE [my_sales] set [sales] = [sales]+@1 WHERE [itemid]=@2
2009-11-24 17:30:10.780 spid15s frame procname=adhoc line=24 stmtstart=938 stmtend=1106 sqlhandle=0x020000002ac2d80354f3e91e11b6251c8c189c5d7eccce5d
2009-11-24 17:30:10.780 spid15s UPDATE my_sales
2009-11-24 17:30:10.780 spid15s SET sales = sales + 5
2009-11-24 17:30:10.780 spid15s WHERE itemid = 1;
2009-11-24 17:30:10.780 spid15s inputbuf
2009-11-24 17:30:10.780 spid15s -- Declare and set variable
2009-11-24 17:30:10.780 spid15s -- to track number of retries
2009-11-24 17:30:10.780 spid15s -- to try before exiting.
2009-11-24 17:30:10.780 spid15s DECLARE @retry INT;
2009-11-24 17:30:10.780 spid15s DECLARE @count INT;
2009-11-24 17:30:10.780 spid15s SET @retry = 2;
2009-11-24 17:30:10.780 spid15s SET @count = 1;
2009-11-24 17:30:10.780 spid15s --Keep trying to update
2009-11-24 17:30:10.780 spid15s -- table if this task is
2009-11-24 17:30:10.780 spid15s -- selected as the deadlock
2009-11-24 17:30:10.780 spid15s -- victim.
2009-11-24 17:30:10.780 spid15s WHILE (@retry > 0)
2009-11-24 17:30:10.780 spid15s BEGIN
2009-11-24 17:30:10.780 spid15s BEGIN TRY
2009-11-24 17:30:10.780 spid15s BEGIN TRANSACTION;
2009-11-24 17:30:10.780 spid15s UPDATE my_sales
2009-11-24 17:30:10.780 spid15s SET sales = sales + 5
2009-11-24 17:30:10.780 spid15s WHERE itemid = 2;
2009-11-24 17:30:10.780 spid15s WAITFOR DELAY '00:00:03';
2009-11-24 17:30:10.780 spid15s UPDATE my_sales
2009-11-24 17:30:10.780 spid15s SET sales = sales + 5
2009-11-24 17:30:10.780 spid15s WHERE itemid = 1;
2009-11-24 17:30:10.780 spid15s SET @retry = 0;
2009-11-24 17:30:10.780 spid15s COMMIT TRANSACTION;
2009-11-24 17:30:10.780 spid15s END TRY
2009-11-24 17:30:10.780 spid15s BEGIN CATCH
2009-11-24 17:30:10.780 spid15s -- Check error number.
2009-11-24 17:30:10.780 spid15s -- If deadlock victim error,
2009-11-24 17:30:10.780 spid15s -- then reduce retry count
2009-11-24 17:30:10.780 spid15s -- for next update retry.
2009-11-24 17:30:10.780 spid15s -- If some other error
2009-11-24 17:30:10.780 spid15s -- occurred, then exit
2009-11-24 17:30:10.780 spid15s -- retry WHILE loop.
2009-11-24 17:30:10.780 spid15s IF (ERROR_NUMBER() = 1205)
2009-11-24 17:30:10.780 spid15s BEGIN
2009-11-24 17:30:10.780 spid15s SET @retry = @retry - 1;
2009-11-24 17:30:10.780 spid15s SELECT @count as '[실행count]', ERROR_MESSAGE()
2009-11-24 17:30:10.780 spid15s process id=process2e58f28 taskpriority=0 logused=208 waitresource=KEY: 10:72057594054639616 (020068e8b274) ownerId=347255 transactionname=user_transaction lasttranstarted=2009-11-24T17:30:02.793 XDES=0x9621290 lockMode=X schedulerid=2 kpid=6876 status=suspended spid=59 sbid=0 ecid=0 priority=0 transcount=2 lastbatchstarted=2009-11-24T17:30:02.793 lastbatchcompleted=2009-11-24T17:30:02.793 clientapp=Microsoft SQL Server Management Studio - 쿼리 hostname=최보라 hostpid=8252 loginname=sa isolationlevel=read committed (2) xactid=347255 currentdb=10 lockTimeout=4294967295 clientoption1=671090784 clientoption2=390200
2009-11-24 17:30:10.780 spid15s executionStack
2009-11-24 17:30:10.780 spid15s frame procname=adhoc line=23 stmtstart=38 sqlhandle=0x020000007245e338daab90ce8e17c9bb5e80187b4d642c14
2009-11-24 17:30:10.780 spid15s UPDATE [my_sales] set [sales] = [sales]+@1 WHERE [itemid]=@2
2009-11-24 17:30:10.780 spid15s frame procname=adhoc line=23 stmtstart=868 stmtend=1036 sqlhandle=0x020000008a4537232ab1f574eb75390b8f81a691db149df4
2009-11-24 17:30:10.780 spid15s UPDATE my_sales
2009-11-24 17:30:10.780 spid15s SET sales = sales + 1
2009-11-24 17:30:10.780 spid15s WHERE itemid = 2;
2009-11-24 17:30:10.780 spid15s inputbuf
2009-11-24 17:30:10.780 spid15s -- Declare and set variable
2009-11-24 17:30:10.780 spid15s -- to track number of retries
2009-11-24 17:30:10.780 spid15s -- to try before exiting.
2009-11-24 17:30:10.780 spid15s DECLARE @retry INT;
2009-11-24 17:30:10.780 spid15s SET @retry = 2;
2009-11-24 17:30:10.780 spid15s -- Keep trying to update
2009-11-24 17:30:10.780 spid15s -- table if this task is
2009-11-24 17:30:10.780 spid15s -- selected as the deadlock
2009-11-24 17:30:10.780 spid15s -- victim.
2009-11-24 17:30:10.780 spid15s WHILE (@retry > 0)
2009-11-24 17:30:10.780 spid15s BEGIN
2009-11-24 17:30:10.780 spid15s BEGIN TRY
2009-11-24 17:30:10.780 spid15s BEGIN TRANSACTION;
2009-11-24 17:30:10.780 spid15s UPDATE my_sales
2009-11-24 17:30:10.780 spid15s SET sales = sales + 1
2009-11-24 17:30:10.780 spid15s WHERE itemid = 1;
2009-11-24 17:30:10.780 spid15s WAITFOR DELAY '00:00:8';
2009-11-24 17:30:10.780 spid15s UPDATE my_sales
2009-11-24 17:30:10.780 spid15s SET sales = sales + 1
2009-11-24 17:30:10.780 spid15s WHERE itemid = 2;
2009-11-24 17:30:10.780 spid15s SET @retry = 0;
2009-11-24 17:30:10.780 spid15s COMMIT TRANSACTION;
2009-11-24 17:30:10.780 spid15s END TRY
2009-11-24 17:30:10.780 spid15s BEGIN CATCH
2009-11-24 17:30:10.780 spid15s -- Check error number.
2009-11-24 17:30:10.780 spid15s -- If deadlock victim error,
2009-11-24 17:30:10.780 spid15s -- then reduce retry count
2009-11-24 17:30:10.780 spid15s -- for next update retry.
2009-11-24 17:30:10.780 spid15s -- If some other error
2009-11-24 17:30:10.780 spid15s -- occurred, then exit
2009-11-24 17:30:10.780 spid15s -- retry WHILE loop.
2009-11-24 17:30:10.780 spid15s IF (ERROR_NUMBER() = 1205)
2009-11-24 17:30:10.780 spid15s BEGIN
2009-11-24 17:30:10.780 spid15s SET @retry = @retry - 1;
2009-11-24 17:30:10.780 spid15s SELECT ERROR_MESSAGE()
2009-11-24 17:30:10.780 spid15s END
2009-11-24 17:30:10.780 spid15s ELSE
2009-11-24 17:30:10.780 spid15s SET @retry = -1;
2009-11-24 17:30:10.780 spid15s resource-list
2009-11-24 17:30:10.780 spid15s keylock hobtid=72057594054639616 dbid=10 objectname=AdventureWorks.dbo.my_sales indexname=PK__my_sales__7CA47C3F id=lock5446f00 mode=X associatedObjectId=72057594054639616
2009-11-24 17:30:10.780 spid15s owner-list
2009-11-24 17:30:10.780 spid15s owner id=process2e58f28 mode=X
2009-11-24 17:30:10.780 spid15s waiter-list
2009-11-24 17:30:10.780 spid15s waiter id=process2e58e38 mode=X requestType=wait
2009-11-24 17:30:10.780 spid15s keylock hobtid=72057594054639616 dbid=10 objectname=AdventureWorks.dbo.my_sales indexname=PK__my_sales__7CA47C3F id=lock5447340 mode=X associatedObjectId=72057594054639616
2009-11-24 17:30:10.780 spid15s owner-list
2009-11-24 17:30:10.780 spid15s owner id=process2e58e38 mode=X
2009-11-24 17:30:10.780 spid15s waiter-list
2009-11-24 17:30:10.780 spid15s waiter id=process2e58f28 mode=X requestType=wait
'Peformance Tuning' 카테고리의 다른 글
| 성능::엑셀이용분석하기 (0) | 2010.06.03 |
|---|---|
| read-ahead는 무었인가? (0) | 2009.12.03 |
| 성능:: 강제 매개변수화 Forced Parameterization (0) | 2009.11.13 |
| SQL서버 성능counter (0) | 2009.11.12 |
One of the main benefits of using a stored procedure to execute Transact-SQL code is that once a stored procedure is compiled and executed the first time, the query plan is cached by SQL Server. So the next time the same stored procedure is run (assuming the same connection parameters are used), SQL Server does not have to recompile the stored procedure again, instead reusing the query plan created during the first compilation of the stored procedure.
If the same stored procedure is called over and over again, with the query plan being reused each time, this can help reduce the burden on SQL Server's resources, boosting its overall performance.
그러나 application에서 SQL Server로 보내는 쿼리는 동적 쿼리도 존재한다. 이런 쿼리들은 매개 변수화 되지 않아서 재 사용이 이루어 지지 않는다.
ALTER DATABASE 문에서 PARAMETERIZATION 옵션을 FORCED로 설정하여 강제 매개 변스화를 설정하면 쿼리 컴파일 및 재 컴파일을 빈도를 줄여 특정 데이터베이스의 성능을 향상 시킬 수 있다.
이것을 설정하면 SELECT, INSERT, UPDATE, DELETE 문에 표시되는 리터럴 값이 쿼리 컴파일 중 매개변수로 변환된다.
다음 구문에 나타나는 리터럴은 예외이다.
WHERE T.col2 >= @bb와 같은 변수를 참조하는 문
[code sql] ALTER DATABASE FORCED [/code]
참고:) http://msdn.microsoft.com/ko-kr/library/ms175037.aspx
'Peformance Tuning' 카테고리의 다른 글
| read-ahead는 무었인가? (0) | 2009.12.03 |
|---|---|
| DeadLock 예제,재 실행하기 (0) | 2009.11.24 |
| SQL서버 성능counter (0) | 2009.11.12 |
| Lock::Trace Flag 1204 (0) | 2009.11.10 |
SQL서버 성능카운터 활용을 위한 팁
원문링크 : http://www.sql-server-performance.com/performance_monitor_counters_sql_server.asp
번역 : 김종균 (jkkim@techdata.co.kr)
SQL서버에서 과도한 I/O의 원인 중 하나는 페이지 분할 입니다. 페이지 split은 인덱스나 데이터 페이지가 꽉 찰 경우에 발생하며, 현재 페이지와 새로이 할당되는 페이지 사이에서 분할이 이루어 집니다. 가끔 발생하는 페이지 분할은 정상입니다만, 과도한 페이지 분할은 과도한 디스크 I/O를 유발하게 되며, 이는 느린 성능을 야기합니다.
SQL서버가 과도한 페이지 분할을 일으키고 있는지를 찾기 원한다면 성능카운터에서 SQL Server Access Methods 개체의 Page Splits/Sec 항목을 모니터 하십시오. 만일 과도한 페이지 분할이 발생하고 있다면, 인덱스의 채우기 비율을 높게 설정하시는걸 고려하십시오. 채우기 비율을 높게 설정하시면 데이터가 가득 차거나, 페이지 분할이 발생하기 전에 데이터 페이지에 보다 더 많은 여유 공간이 있으므로, 페이지 분할을 감소시킬 수 있습니다
높은 Page Splits/sec 은 무얼 의미하는가? 이것은 운영하는 시스템의 I/O하부 시스템에 따라 다르므로 이에 대한 간단이 답을 할 수 없습니다. 그러나 만일 당신이 평상시에 디스크 I/O의 성능 문제가 발생하고, 이 카운터 값이 100을 초과한다면, 채우기 비율을 높여서 성능이 호전 되는지 그렇지 않은지 실험해 보는 것도 좋을 것 입니다.
*****
물리적인 메모리를 SQL서버 Data캐시에 얼마나 할당되었는지 알고 싶다면, SQL Server Buffer Manager Object: Cache Size (pages) 항목을 모니터링 하십시오. 이 수치는 페이지 수로 표시되므로, 이 값에 8K(8192 bytes)를 곱하면, Data캐시로 사용되고 있는 총 메모리의 사용량을 알 수 있습니다.
일반적으로, 이 수치는 서버의 총 메모리 량에 근접해야 합니다. SQL서버로 운영하는 시스템에서 OS커널이나, SQL서버 그리고 기타 유틸리티 프로그램이 사용하는 메모리 량을 최소화 하십시오.
만일 Data캐시 용도로 할당된 메모리 양이 여러분이 생각하는 것 보다 훨씬 작다면, 왜 그런지 원인을 찾으셔야 합니다. 아마도, SQL서버가 메모리를 동적으로 할당하도록 설정하지 않고, 대신에 뜻하지 않게 SQL서버가 적은 메모리를 사용하게 구성 하셨을 겁니다. SQL서버가 가용할 수 있는 Data캐시의 총량은 SQL서버 성능에 아주 큰 영향을 미치기 때문에 원인이 무엇이든 간에 여러분은 해결방안을 찾아야 합니다.
실제로는, SQL서버가 메모리가 부족한지 아닌지를 알기 위해 보다 많은 카운터들이 존재하고, 더 효율적이기 때문에 저는 이러한 카운터(SQL Server Buffer Manager Object: Cache Size (pages))를 모니터 하는데 많은 시간을 사용하지 않습니다. (그래서 어쩌라고. ㅜㅜ)
*****
SQL서버가 얼마나 바쁜지 알기 위해서, SQLServer: SQL Statistics: Batch Requests/Sec 카운터를 모니터 하십시오. 이 카운터는 초당 SQL서버가 받는 배치 요청 수를 측정하고, 일반적으로 서버의 CPU들이 얼마나 바쁜지 나타냅니다. 말하자면, 초당 1000배치가 넘어서면, SQL서버가 매우 바쁘다는 것을 나타내며, CPU병목 현상이 아직 나타나지 않고 있다면, 조만간 CPU병목 현상이 나타날 것임을 알 수 있습니다. 물론 이 수치는 상대적인 것이며, 여러분의 하드웨어가 고 사양이라면, 보다 더 많은 초당 배치요청 수를 커버할 수 있을 것입니다.
네트워크 병목의 관점에서 보자면, 100Mbps 네트워크 카드는 초당 3000 배치 요청을 처리 할 수 있습니다. 만일 네트워크 병목이 심한 서버를 운영하고 계시다면, 네트워크 카드를 2개이상 늘리거나, 1Gbps 네트워크 카드로 교체 할 필요가 있을 것입니다.
몇몇 DBA들은 전체 SQL서버활동량을 측정하기 위해서 SQLServer: Databases: Transaction/Sec: _Total 카운터를 모니터 하는데, 이는 좋은 방법이 아닙니다. Transaction/Sec 카운터는 전체 활동량이 아닌 한 트랜잭션의 내부활동을 측정하며, 왜곡된 값을 나타냅니다. 대신에, SQL서버의 전체 활동량을 측정하는 SQLServer: SQL Statistics: Batch Requests/Sec 카운터를 사용하시기 바랍니다
*****
TSQL코드의 컴파일은 SQL서버의 일반적인 동작입니다. 그러나, 이 컴파일이 CPU와 다른 리소스들을 많이 잡아 먹기 때문에, SQL서버는 가능한 많은 실행계획을 캐시에 저장해서 실행계획이 컴파일 되지 않고 재사용되도록 시도합니다(실행계획은 컴파일이 발생할 때 생성됩니다). 보다 더 많은 실행계획이 재 사용 되어지면, 서버에 대한 부담은 더 적어지게 되며, 전체적인 성능은 더욱 더 향상 됩니다.
SQL서버가 얼마나 많은 컴파일을 하고 있는지 확인 하려면, SQLServer: SQL Statistics: SQL Compilations/Sec 카운터를 모니터 하십시오. 여러분이 기대하시는 것처럼, 이 카운터는 초당 얼마나 많은 컴파일이 SQL서버에 의해서 실행되었는지를 측정합니다.
말하자면, 이 카운터의 수치가 초당 100을 넘어서면, 불필요한 컴파일 오버헤드를 경험하고 계신 것 입니다. 이러한 높은 수치는 여러분의 서버가 매우 바쁨을 나타내거나, 불필요한 컴파일들이 실행되고 있다고 볼 수 있겠습니다. 예를 들어, 오브젝트의 스키마가 변경되거나, 병렬로 실행계획이 잡혀있던 것이 직렬로 실행되어야 하거나, 통계가 다시 계산되었다거나 하는 등의 이유로 SQL서버로부터 재 컴파일 하라는 지시를 받았을 수도 있습니다. 어떤 경우에는, 불필요한 컴파일을 줄이기 위해서 여러분의 노력이 필요할 수 도 있습니다. (역주. 잘 아시듯이, adhoc 쿼리를 저장프로시져로 만들면 컴파일 이슈가 없어지죠)
만약, 여러분의 서버가 초당 100회 이상의 컴파일을 수행한다면, 이 원인이 여러분이 조절할 수 있는 것인지 아닌지 찾기 위해 애 쓰셔야 합니다. 너무 많은 컴파일은 SQL서버의 성능에 악영향을 끼칩니다.
*****
SQLServer: Databases: Log Flushes/sec 카운터는 초당 플러쉬 된 로그 수를 나타냅니다. 이 카운터는 데이터베이스 별로 측정되거나, 단일 SQL서버의 전체 데이터베이스에 대한 값으로 측정 될 수 있습니다.
로그 플러쉬란 무엇일까요? 이해를 쉽게 하기 위해서 예를 들어 설명 하는 게 좋을 것 같습니다. 10개의 INSERT명령이 있는 트랜잭션을 시작한다고 가정하겠습니다. 트랜잭션이 시작되고, 그리고, 첫 번째 INSERT가 실행되고, 새 데이터가 데이터 페이지로 삽입 되어질 때, 필수적으로 동시에 두 가지의 일이 발생합니다. 버퍼캐시의 데이터페이지는 새로이 삽입된 데이터로 변경됩니다, 그리고 이 단일 INSERT명령에 대한 적당한 로그용 데이터가 로그캐시에 쓰여집니다. 이 과정은 트랜잭션이 완료 될 때까지 계속 됩니다. 이때, 로그캐시에 기록된 트랜잭션을 위한 로그 데이터는 즉시 로그파일에 기록됩니다, 그러나 버퍼캐시에 있는 데이터는 다음 체크포인트 프로세스가 실행되기 전까지 버퍼캐시에 머무르게 됩니다. 그리고, 그때 데이터베이스는 새로이 삽입된 행으로 업데이트 됩니다.
여러분은 로그캐시에 대해서 한번도 들어보지 못했을지도 모릅니다. 이것은 SQL서버가 로그파일에 쓰여질 데이터를 기록하는 메모리의 한 영역입니다. 로그캐시의 목적은 트랜잭션이 커밋 되기 전에 특정상황이 발생하여 롤백 해야 하는 상황에서 트랜잭션을 롤백 하는 용도로 사용되기 때문에 매우 중요합니다. 그러나, 트랜잭션이 완료되면 (완료되면 절대 롤백 되지 않음), 로그 캐시는 즉시 물리적인 로그파일로 플러시 됩니다. 이것이 정상적인 절차입니다. SELECT쿼리는 데이터를 수정하지도 않고 트랜잭션을 생성하지도 않고, 로그 플러시를 발생하게 하지도 않음을 명심 하십시오.
본질적으로, 로그캐시에 있는 데이터가 물리적인 로그파일로 쓰여질 때 하나의 로그 플러시가 발생합니다. 따라서, 하나의 트랜잭션이 완료될 때마다, 로그 플러시는 발생하며, 많은 수의 로그 플러시 발생은 SQL서버로부터 수행되는 많은 수의 트랜잭션과 관련이 있습니다. 그리고, 짐작하시는 것처럼 로그 플러시(얼마나 많은 데이터가 로크 캐시로부터 디스크에 기록 되어졌는가) 의 크기는 트랜잭션에 따라 다릅니다. 이 내용이 도움이 되었나요?
우리가 디스크 I/O 병목현상을 격 고 있고, 그 원인을 확신하지 못하고 있다고 가정합시다. 디스크 I/O에 대한 병목을 해결하기 위한 하나의 방법은 Log Flushes/sec 카운터 데이터를 수집하고, 이 과정을 처리하는데 얼마나 바쁜지 보는 것입니다. 여러분의 서버에 많은 트랜잭션이 발생하고 있다며, 로그 플러시 양은 당연히 많을 것입니다, 따라서 이 카운터 항목으로 보는 값은 트랜잭션을 발생하는 활동 형 쿼리가 얼마나 바쁜가에 따라 서버마다 다양할 것입니다. 이 카운터 정보로써 여러분은 초당 발생하는 로그 플러시 수가 운영하는 서버에서 예상되는 트랜잭션의 수 보다 확연하게 높은가에 대한 상황 판단에 도움을 줄 것이다.
예를 들어, 매일 1,000,000행을 한 테이블로 삽입하는 작업을 한다고 가정합시다. 이 행들이 삽입되어질 수 있는 방법은 다양합니다. 첫째, 각 행은 따로따로 삽입되어 질 수 있습니다. 각 INSERT는 단일 트랜잭션 내부에 감싸집니다. 둘째, 모든 INSERTS는 단일 트랜잭션 내에서 수행되어 질 수 있습니다. 마지막으로, INSERTs는 1과 1,000,000사이의 어딘가에 여러 개의 트랜잭션으로 나누어 질 수 있습니다. 각 형태의 처리는 다르며, SQL서버와 초당 플러시 되는 로그 수에 매우 다른 영향을 미칩니다. 더구나, 프로세스가 멀티 트랜잭션으로 처리되고 있는데, 단일 트랜잭션으로 처리되고 있다고 착각할 수 도 있다. 많은 사람들이 단일 프로세스를 단일 트랜잭션으로 생각하고 있는 경향이 있습니다.
첫째의 경우에서, 만일 1,000,000행이 1,000,000개의 트랜잭션으로 삽입되어진다면, 1,000,000번의 로그 플러시가 발생할 것입니다. 그러나, 두 번째 경우에는, 단일 트랜잭션에서 1,000,000행이 삽입되어 질 것이고, 단지 하나의 로그 플러시가 발생할 것입니다. 그리고, 세 번째 경우 에는 플러시 되는 로그의 수는 트랜잭션의 수와 같을 것입니다. 명백히, 로그 플러시의 크기는 1,000,000트랜잭션이 1트랜잭션보다 훨씬 클 것입니다, 그러나, 대개의 경우 성능의 관점에서 여기서 언급한 내용은 그다지 중요하지 않습니다.
어떤 옵션이 가장 좋은가요? 모든 경우에서, 많은 디스크 I/O를 유발할 것입니다. 1,000,000행을 핸들링 할 경우에는 I/O양을 줄일 묘안이 없습니다. 그러나, 하나 혹은 적은 수의 트랜잭션을 사용함으로써 로그 플러시 양을 많이 줄일 수 있을 것이고, 이는 디스크 I/O양을 줄이게 되어, I/O병목 감소와 성능을 높여줄 것입니다.
우리는 두 가지 포인트를 배웠습니다. 첫째는, 여러분이 플러시 되는 로그 양을 가능한 많이 줄이길 원할 것이라는 것과, 둘째, 여러분의 서버에서 발생하는 트랜잭션의 수를 줄이는 것입니다.
*****
SQL서버를 사용하는 많은 수의 사용자는 성능에 영향을 미치기 때문에, 여러분은 SQL Server General Statistics Object: User Connections 카운터에 관심을 가질것입니다. 이 카운터는 사용자 수가 아닌, SQL서버에 현재 연결된 사용자 연결 수를 나타냅니다
이 수치를 해석할 때, 하나의 단일 사용자는 여러 개의 연결들로 열릴 수 있음을 유념하십시오. 그리고 또한, 여러 명의 사람이 하나의 단일 사용자 연결을 공유할 수 도 있습니다. 이 수가 실제 사용자수를 나타낸다고 가정하지 마십시오. 대신에, 서버가 얼마나 바쁜가에 대한 상대적 척도로 사용하십시오. 여러 시간에 걸쳐서 이 수치를 모니터 해보시면, 서버가 많이 사용되고 있는지, 적게 사용되고 있는지 느낄 수 있을 것 입니다.
*****
만약 여러분들의 데이터베이스들이 데드락 문제로 괴로워하고 있다면, SQL Server Locks Object: Number of Deadlocks/sec 카운터를 통해서 추적할 수 있습니다. 그러나, 이 값이 상대적으로 높지 않다면, 이 값은 초단위로 측정되기 때문에 여러분은 더 많이 보기 원할 것입니다. 그리고, 눈에 띄게 보여지기 위해서는 다량의 데드락이 있어야 합니다. (ㅜㅜ)
그러나, 여전히 이 카운터는 여러분이 데드락 문제를 가지고 있는지 확인하기 위해서 가치있는 항목입니다. 차라리, 데드락을 추적하기 위해서 프로필러를 이용하십시오. 이는 보다 상세한 정보를 제공할 것입니다. 데드락 문제를 발견하기 위해서 Number of Deadlocks/sec 카운터를 활용하시고, 좀 더 세부적인 분석을 위해서 프로필러를 사용하십시오.
*****
만약에, 사용자들이 트랜잭션의 완료를 위한 대기시간 때문에 불만을 나타낸다면, 여러분은 개체 잠금이 이 문제가 되고 있는지 찾고 싶을 것 입니다. 문제점을 찾기 위해서, SQL Server Locks Object: Average Wait Time (ms) 카운터를 사용하십시오. 이 카운터는 database, extent, key, paLock Timeouts/secge, RID, table의 다양한 잠금에 대한 평균 대기 시간 정보를 측정합니다.
DBA로써, 여러분은 평균 대기 시간이 얼마 정도까지 허용될 수 있는지 결정해야 합니다. 한가지 방법으로써, 개별 잠금 종류에 대해서 장시간 동안 이 카운터 항목을 모니터 하시고, 각 잠금 별 평균을 파악하시는 겁니다. 그리고 그 평균값을 참고 자료로 활용 하시는 거죠. 예를 들어, RID의 평균 잠금 대기시간이 500ms 라면, 500보다 큰 대기시간을 가지는 개체들은 , 잠재적인 문제점을 가지고 있다고 판단할 수 있을 것입니다. 특히 500보다 훨씬 크거나, 장시간 동안 연장되는 개체들은 더 쉽게 판단할 수 있습니다.
여러분이 트랜잭션 지연에 의한 단일 혹은 다양한 종류의 잠금을 확인 할 수 있다면, 어떤 트랜잭션들이 잠금의 원인이 되었는지 확인할 수 있는지 알기 위해서 조사하길 원할 것 입니다.
*****
그런데 가끔 인덱스 탐색보다 테이블 스캔이 빠른 경우에, 일반적으로 적은 테이블 스캔이 보다 많은 테이블 스캔 보다 좋다. 여러분의 서버에서 얼마나 많은 테이블 스캔이 발생하는지 알아보기 위해서, SQL Server Access Methods Object: Full Scans/sec 카운터를 사용하십시오.이 카운터는 단일 데이터베이스가 아닌 전체 서버에 대한 값이라는 사실을 염두에 두셔야 합니다. 이 카운터 값으로 알게 될 사실 하나는 가끔씩 예측이 가능한 스캔 형태를 나타낸다는 것 입니다. 대부분의 경우에 이 값들은 SQL서버가 내부적으로 사용하는 것 들입니다.
여러분의 응용프로그램에서 나타나는 불규칙적인 테이블 스캔들을 파악하길 원하실 것입니다. 과도한 테이블 스캔이 발생될지를 고려하기 위해서 프로필러 데이터를 수집하고 인덱스 튜닝 마법사를 통해서, 어떤 것이 원인이 되는지 결정 할 수 있게 도움을 받을 수 있습니다. 그리고 몇몇 인덱스를 추가함으로써 테이블 스캔을 줄일 수 있을 것 입니다. 물론 SQL서버는 이 작업을 훌륭하게 수행할 것이고, 더 효율적이라면, 인덱스를 사용하는 것 대신에 테이블 스캔을 수행 할 것입니다. 그러나 내부적으로 어떤 일이 발생하는지 찾아 보지 않는 한 여러분은 알지 못 할 것입니다.
*****
만일 백업 및 복원 명령이 최적이 아닌 속도로 수행된다면, SQL Server Backup Device Object: Device Throughput Bytes/sec 카운터를 이용해서, 이 문제를 확인 할 수 있습니다. 이 카운터는 여러분의 백업이 얼마나 빨리 수행되는지 알려 줄 것입니다. 또한 문제에 대한 의구심을 해결하기 위해서 Physical Disk Object: Avg. Disk Queue Length 카운터를 같이 조사해 볼 수 도 있습니다. 대부분의 경우에 백업과 복원의 성능 문제가 있다면, I/O 병목에 의한 것들입니다.
DBA로써 경험하고 다루게 되는 I/O병목에 대한 판단의 작업 또한 수행할 것입니다. 예를 들면, 느린 백업 또는 복원의 원인이 같은 시점에 수행되는 단순한 DTS작업 때문일 수 있으며, 작업에 대한 일정의 재조정으로 문제를 해결 할 수 있습니다.
*****
여러분이 트랜잭션 복제를 사용하고 계신다면, 로그 리더가 트랜잭션들을 데이터베이스의 트랜잭션 로그로부터 배포 데이터베이스로 옮겨질 때까지의 지연시간을 모니터하길 원하실 것입니다.
또한 배포 에이젼트가 트랜잭션들을 배포데이터베이스에서 구독자 데이터베이스로 옮기는데 소요되는 시간을 모니터 하길 원할 것입니다. 이 두 지연시간의 합은 하나의 트랜잭션이 게시 데이터베이스에서 구독 데이터베이스로 전달되는 총 소요시간입니다.
이 두 카운터는 SQL Server Replication LogReader: Delivery Latency 와 SQL Server Replication Dist.: Delivery Latency 입니다.
만약, 둘 중의 하나의 과정중에 과도한 지연시간 증가를 발견한다면, 이것은 어떤 새로운 변화가 발생하여 지연 시간을 증가 시켰는지 살펴봐야 한다는 신호입니다.
*****
관찰하여야 할 주요한 카운터는 SQL Server Buffer Manager Object: Buffer Cache Hit Ratio 입니다. 이것은 SQL서버가 데이터를 액세스 하기 위해 하드디스크가 아닌 버퍼를 얼마나 자주 참조하는가를 나타냅니다. 보다 높은 이 수치는, SQL서버가 데이터를 가져오기 위해서 하드디스크에 아주 가끔 액세스한다는 것이며, 이는 SQL서버의 성능을 극대화 시킵니다.
SQL서버를 모니터하는 다른 카운터들과는 달리, 이 카운터는 SQL서버가 다시 시작한 시점 이후부터의 버퍼 캐시 히트율의 평균 값입니다. 다른 말로, 이 카운터는 현재 시점의 측정 값이 아니라 SQL서버가 시작된 이후의 모든 날들의 평균값입니다. 현재 시점의 버퍼캐시에서 어떤일이 발생하고 있는지 정확한 자료를 얻기 원한다면, 여러분은 SQL서버를 중지 했다가 다시 시작해야만 하고, 정확한 버퍼 캐시 히트율을 확인하기 위해 SQL서버를 여러 시간 동안 일반적인 활동을 하게 내버려 둬야 합니다.
만약 최근에 SQL서버를 재 시작 하지 않았다면, 여러분이 보고 있는 버퍼 캐시 히트율은 아마도 현재 발생하는 버퍼 캐시 히트율을 위해서는 정확한 정보가 아닐 것 입니다. 또한 버퍼 캐시 히트율이 좋아 보일지라도, 오랜 시간의 평균값으로 계산되었기 때문에 실제로는 좋지 않을 지도 모릅니다.
OLTP 응용프로그램 환경에서, 이 수치는 90~95% 이상이어야 합니다. 그렇지 않다면, 여러분은 성능 향상을 위해서 서버에 RAM을 추가할 필요가 있습니다.
OLAP 응용프로그램 환경에서는, OLAP작동하는 기본특성 때문에 이 수치는 OLTP 보다 더 작을 수 있습니다. 어떤 경우라도, 더 많은 RAM은 SQL서버의 OLAP 활동의 성능을 증가 시킬것입니다.
*****
이 두 카운터를 관측하는걸 고려하십시요. SQLServer:Memory Manager: Total Server Memory (KB) and SQLServer:Memory Manager: Target Server Memory (KB). 첫번째 카운터 SQLServer:Memory Manager: Total Server Memory (KB) 는 mssqlserver서비스가 메모리를 얼마나 사용하고 있는가를 말해줍니다. 이것은 SQL서버 Bpool영역으로 커밋된 전체 버퍼수를 포함하고, ‘OS in Use’ 로 표시되는 OS버퍼들도 포함합니다.
두번째 카운터, SQLServer:Memory Manager: Target Server Memory (KB)는 SQL서버가 얼마나 많은 메모리를 가용할 수 있는가를 나타냅니다. 이는 SQL서버가 시작시에 예약한 버퍼수에 기초합니다.
만약, Total Server Memory (KB)이 Target Server Memory (KB)보다 작다면, 이는 SQL서버가 충분한 메모리를 가졌고, 효율적으로 사용하고 있다는 것을 의미합니다. 반면에 Total Server Memory (KB)이 Target Server Memory (KB)보다 크거나 같다면, 이는 SQL서버가 메모리 압박을 받고 있고, 더 많은 물리적 메모리에 액세스 하고 있음을 나타냅니다.
*****
디스크로부터 데이터를 읽는 대신에 버퍼 캐시로부터 데이터를 가져온다면 SQL서버는 보다 적은 자원으로 보다 훨씬 더 빠르게 수행합니다. 몇몇 경우에, 메모리 집중적인 명령들로 인해 데이터 페이지들이 이상적으로 플러시 되기 전에 캐시 밖으로 밀려 나가기도 한다. 이는 버퍼 캐시가 충분히 크지 않거나 메모리 집중적인 명령의 작업을 위한 더 많은 버퍼 공간 요구에 의해 발생할 수 있습니다. 이런 경우에는 버퍼에 추가 적인 공간을 만들기 위해서 플러시 된 데이터 페이지들은 디스크로부터 읽혀지게 되며, 성능에 안 좋은 영향을 미치게 됩니다.
여러분들의 SQL서버가 이러한 문제를 가지고 있는지 확인 하기 위한 3개의 SQL 서버 카운터가 있습니다.
· SQL Server Buffer Mgr: Page Life Expectancy : 이 성능 카운터는 데이터 페이지가 얼마나 오랫동안 버퍼공간에 머무르는지를 평균적으로 나타내 줍니다. 만약 이 값이 300초 보다 작은 값을 보인다면, 여러분의 SQL서버는 성능의 극대화를 위해서 추가적인 메모리가 필요함을 잠재적으로 나타내는 것입니다.
· SQL Server Buffer Mgr: Lazy Writes/Sec : 이 카운터는 버퍼 공간을 비우기 위해서 지연기록기 프로세스가 더티 페이지들을 버퍼공간에서 디스크로 초당 얼마나 많이 옮겼는지 나타냅니다. 일반적으로 말하자면, 이 항목은 높은 값(초당 20정도)이어서는 안됩니다. 이상적으로, 0에 가까워야 합니다. 만약 이 값이 0이라면, 여러분의 SQL서버는 아주 큰 버퍼 공간을 가지고 있고, 일정한 체크 포인트가 발생하여 더티페이지가 반환되기를 기다리는 대신에, 더티페이지 반환을 하지 않아도 됨을 나타냅니다. 만약 이 값이 높다면, 보다 더 많은 메모리가 필요함을 나타냅니다.
· SQL Server Buffer Mgr: Checkpoint Pages/Sec: 체크포인트가 발생할 때, 모든 더티 페이지들은 디스크에 쓰여 집니다. 이것은 일반적인 절차이며, 체크포인트가 처리되는 동안에 이 카운터가 발생하는 근원이 됩니다. 시간에 걸쳐서 이 카운터의 높은 값을 보길 원치 않으실 것입니다. 이는 SQL서버의 귀중한 자원을 많이 사용할 수 있는 체크포인트 프로세스가 보다 더 자주 실행됨을 나타냅니다. 만약 이 값이 높은 값을 가진다면, 빈번한 체크 포인트 발생을 줄이기 위해서 더 많은 RAM을 추가할 것을 고려하시거나, SQL서버의 구성옵션 중에 ‘복구 간격(recovery interval)’ 옵션 값을 늘려주십시오.
이러한 성능 모니터 카운터들은 “메모리 부족”의 잠재적인 진단을 위해서 고려되거나, 고도화하거나, 정제하기 위해 사용되어야 합니다.
*****
래치는 본질적으로 “경량 잠금” 입니다. 기술적인 관점에서, 래치는 가볍고, 짧은 동기화 개체입니다. 래치는 마치 잠금 처럼 동작하고, 예상치 않은 변화로부터 데이터를 보호하기 위한 목적을 가지고 있습니다. 예를 들면, 하나의 행이 버퍼로부터 SQL서버의 저장소 엔진으로 이동될 때, 이 매우 짧은 시간 동안의 이동 중에 행 내부의 데이터 변형을 방지하기 위해서 SQL서버에 의해서 래치가 사용되어 집니다.
마치 잠금과 같이, 래치는 데이터베이스의 행들에 대해 접근하지 못하게 SQL서버를 방해 할 수 있고, 이는 성능에 안 좋은 영향을 줍니다. 이러한 이유 때문에 여러분은 래치 시간을 최소화하길 원하실 것입니다.
SQL서버는 래치의 활동을 측정하기 위한 3가지 다른 방법을 제공합니다.
· Average Latch Wait Time (ms): 래치 요청들을 위해 대기해야 하는 시간입니다. 이는 오직 대기해야 하는 래치 요청들에 대한 측정값입니다. 대부분의 경우에 대기가 없습니다. 따라서, 이 값은 모든 래치에 대한 것이 아니라, 대기 해야 하는 래치에 대해서만 적용된 값임을 유념하십시오.
· Latch Waits/sec: 이 값은 즉시 승인 받지 못한 래치 요청수입니다. 다시 말해서, 1초 동안에 대기 해야 했던 총 래치의 수입니다. 따라서, 이는 Average Latch Wait Time으로 부터 측정된 래치들 입니다.
· Total Latch Wait Time (ms): 이는 지난 초 동안의 총 래치 대기 시간 (ms) 입니다.
이 값을 읽을 때, 성능카운터에서 배율을 정확히 읽었는지 확인하십시오. 배율은 카운터 값마다 다르게 표시될 수 있습니다.
제 경험에 비추어 볼 때, Average Latch Wait Rime 카운터는 거의 변함이 없습니다. 반면에 다른 두 개의 카운터(Latch Waits/sec , Total Latch Wait Time (ms)) 는 SQL서버가 뭘 하느냐에 따라서 큰 변동폭을 보일 수 있습니다.
각각의 서버가 약간씩 다르기 때문에, 래치 활동도 각 서버마다 다릅니다. 전형적인 작업부하가 있을 때, 이 카운터에 대한 기준 값을 확보해 두시는 것은 아주 좋은 생각입니다. 이는 현재 어떤 일이 발생하고 있는가에 대해서 래치 활동이 평상시 보다 많은지 적은지에 대한 비교자료가 될 것입니다.
래치 활동이 기대치 보다 높다면, 이는 종종 하나 혹은 두 개의 잠재적인 문제점들을 나타냅니다. 첫째, 여러분의 SQL서버가 보다 많은 메모리를 사용할 수 있음을 의미할지도 모릅니다. 래치 활동이 높다면, 버퍼 캐시 히트 비율이 어떤지 확인하십시오. 이 값이 99% 이하라면, 보다 더 많은 양의 메모리가 서버의 성능에 도움을 줄 것입니다. 만약 99% 이상이라면, 문제를 유발하는 것은 IO시스템일수도 있습니다. 빠른 IO시스템은 서버 성능에 유리합니다.
래치에 대해서 보다 더 많이 배우고, 실험해보고 싶으시면, 여기 두 개의 명령이 있습니다.
SELECT * FROM SYSPROCESSES WHERE waittime>0 and spid>50
이 쿼리는 현재 대기상태에 있는 waittype, waittime, lastwaittype, waitresource, SPID들을 표시해 줍니다. lastwaittype은 래치 종류를, waitresource는 SPID가 어떤 개체를 위해 대기 중인지를 알려줍니다. 이 쿼리를 실행하게 되면, 실행 시점에 대기가 발생하고 있지 않다면, 아무런 결과도 얻지 못 할 지도 모릅니다. 그러나 계속해서 실행하다 보면, 결국 몇몇 결과를 얻게 될 것입니다.
DBCC SQLPerf (waitstats, clear) --대기 통계초기화
DBCC SQLPerf (waitstats) -- SQL서버 재시작(대기 통계 초기화) 이후의 대기 통계정보
이 쿼리는 대기유형, 대기시간과 함께 현재의 래치들을 나타내줍니다. 여러분은 아마도 통계정보를 초기화하길 원할 겁니다. 그런 다음에는 어떤 래치가 가장 많은 시간을 차지하는지 알기 위하여, DBCC SQLPerf(waitstats)명령을 짧은 시간에 걸쳐서 정기적으로 실행하십시오.
'Peformance Tuning' 카테고리의 다른 글
| DeadLock 예제,재 실행하기 (0) | 2009.11.24 |
|---|---|
| 성능:: 강제 매개변수화 Forced Parameterization (0) | 2009.11.13 |
| Lock::Trace Flag 1204 (0) | 2009.11.10 |
| 쿼리 Plan을 그래프로 보기 (0) | 2009.11.09 |
원본출처: http://blogs.msdn.com/bartd/attachment/747119.ashx
Below you’ll see sample -T1204 output for a very simple deadlock between two spids, spid 51 and spid 52. The deadlock is represented as a list of “nodes”. Each node represents one resource – most commonly a lock – that is involved in the deadlock. For each node, or lock, information is provided about both the spid that is blocked waiting for access to this resource, and about the spid is already has a lock on the resource that is blocking the first spid. A simple deadlock involves two spids and two locked resources, but deadlocks involving 3 or more spids are also possible.
The -T1204 output is annotated to explain the most relevant parts of the output. If you are viewing this page in Internet Explorer, you may need to enable active content for the page before you can see the annotations. Hover over the comment markers to see the annotations.
spid4 Deadlock encountered .... Printing deadlock information
spid4
spid4 Wait-for graph
spid4
spid4 KEY: 7:2121058592:2 (a70064fb1eac)[BKD2] CleanCnt:1 Mode: X[BKD3] Flags: 0x0
spid4 Grant List 0::
spid4 Owner:0x42bdefa0 Mode: X[BKD4] Flg:0x0 Ref:0 Life:02000000 SPID:52 ECID:0
spid4 SPID: 52[BKD5] ECID: 0 Statement Type: DELETE[BKD6] Line #: 6[BKD7]
spid4 Input Buf: Language Event:
EXEC spClearItemStatus 152363[BKD8]
spid4 Requested By:
spid4 ResType:LockOwner Stype:'OR' Mode: U SPID:51[BKD9] ECID:0 Ec:(0x43F5F588) Value:0x42bded20 Cost:(0/10AC)
spid4
spid4 KEY: 7:1977058079:1 (02014f0bec4e)[BKD11] CleanCnt:1 Mode: X Flags: 0x0
spid4 Grant List 0::
spid4 Owner:0x42bde9a0 Mode: X Flg:0x0 Ref:0 Life:02000000 SPID:51 ECID:0
spid4 SPID: 51 ECID: 0 Statement Type: UPDATE Line #: 47
spid4 Input Buf: Language Event:
spUpdateItemProp 152363, ' QTY', 3525
spid4 Requested By:
spid4 ResType:LockOwner Stype:'OR' Mode: X SPID:52 ECID:0 Ec:(0x43983588) Value:0x42bdee40 Cost:(0/54)
spid4 Victim Resource Owner:
spid4 ResType:LockOwner Stype:'OR' Mode: X SPID:52[BKD12] ECID:0 Ec:(0x43983588) Value:0x42bdee40 Cost:(0/54)
By using the info highlighted in the first node above, and the same items from the second node, you can reconstruct the following more readable description of the deadlock scenario:
Spid 52 is running a DELETE statement on line 6 of the stored proc spClearItemStatus. He holds an X lock on the key resource KEY: 7:2121058592:2 (a70064fb1eac). This lock is blocking spid 51, who is waiting to acquire a U lock on the same key.
Spid 51 is running an UPDATE statement on line 47 of the stored proc spUpdateItemProp. He holds an X lock on key KEY: 7:1977058079:1 (02014f0bec4e). His X lock is blocking spid 52, who is waiting to acquire an X lock on the same key.
So, spid 51 is blocked by 52, while spid 52 is blocked by 51. This is a circular blocking chain, which is another name for a deadlock.
It would be better to identify the key lock using a more meaningful table name and index name instead of using cryptic resource IDs like “KEY: 7:2121058592:2 (a70064fb1eac)”. It is not possible to figure out what tables and indexes are involved from -T1204 output alone because we don’t have the necessary data to decode these lock resource IDs. For example, the resource “KEY: 7:2121058592:2 (a70064fb1eac)” corresponds to a particular index key in nonclustered index 2, on a table with object ID 2121058592, in the database with dbid 7. You can figure out what table and index this is by looking at sysobjects and sysindexes for the relevant database. After decoding the lock resource IDs and identifying the specific queries involved, the description of the first node might look like this:
'Peformance Tuning' 카테고리의 다른 글
| DeadLock 예제,재 실행하기 (0) | 2009.11.24 |
|---|---|
| 성능:: 강제 매개변수화 Forced Parameterization (0) | 2009.11.13 |
| SQL서버 성능counter (0) | 2009.11.12 |
| 쿼리 Plan을 그래프로 보기 (0) | 2009.11.09 |
'Peformance Tuning' 카테고리의 다른 글
| DeadLock 예제,재 실행하기 (0) | 2009.11.24 |
|---|---|
| 성능:: 강제 매개변수화 Forced Parameterization (0) | 2009.11.13 |
| SQL서버 성능counter (0) | 2009.11.12 |
| Lock::Trace Flag 1204 (0) | 2009.11.10 |
Deadlock 발생시 원인과 해결법.
1. Deadlock 이유를 알고 싶으면 trace 1204 를 켜 준다.
DBCC Tracestatus(-1) -- 잘 실행되고 있는지 확인
2. Deadlock 발생되면 SQL의 에러로그에 로그가 남게 된다.
Wait-for graph
Node:1 PAG: 9:1:18061 CleanCnt:2 Mode: SIU Flags: 0x2
Grant List 1::
Grant List 2::
Owner:0x27c007e0 Mode: S Flg:0x0 Ref:0 Life:00000001 SPID:84 ECID:0
SPID: 84 ECID: 0 Statement Type: UPDATE Line #: 11
Input Buf: RPC Event: dbo.Example_Stored_proc
Requested By: 0
ResType:LockOwner Stype:'OR' Mode: IX SPID:78 ECID:0 Ec:(0x44AA55F0) Value:0x3affcd00 Cost:(0/0)
Node:2 PAG: 9:1:18134 CleanCnt:2 Mode: SIU Flags: 0x2
Grant List 1::
Owner:0x28e6f060 Mode: S Flg:0x0 Ref:0 Life:00000001 SPID:78 ECID:0
SPID: 78 ECID: 0 Statement Type: UPDATE Line #: 11
Input Buf: RPC Event: dbo. Example_Stored_proc
Grant List 2::
Requested By:
ResType:LockOwner Stype:'OR' Mode: IX SPID:84 ECID:0 Ec:(0x239955F0) Value:0x3affc940 Cost:(0/0)
Victim Resource Owner:
ResType:LockOwner
Stype:'OR' Mode: IX SPID:84 ECID:0 Ec:(0x239955F0) Value:0x3affc940 Cost
3. 에러로그를 확인해 보면 'Example_stored_proc' 프로시저에서 update 시 exclusive lock 이 발생하고 있다는 것을 확인 할 수 있다.
4. sp_helptext 'Example_stored_proc' 를 실행하여 프로시저의 내용을 확인 한다.
5. 이와 관련있는 프로시저를 확인하고 deadlock 이 발생하는 page를 확인할 수 있다.
Node:1 PAG: 9:1:18061 CleanCnt:2 Mode: SIU Flags: 0x2
6. 해당 페이지를 조사해 본다. , DBCC Page 사용
MSDN : http://support.microsoft.com/kb/83065
---------------
BUFFER:
-------
BUF @0x01665900
---------------
bpage = 0x1DF58000 bhash = 0x00000000 bpageno = (1:18061)
bdbid = 9 breferences = 1 bstat = 0xb
bspin = 0 bnext = 0x00000000
PAGE HEADER:
------------
Page @0x1DF58000
----------------
m_pageId = (1:18061) m_headerVersion = 1 m_type = 1
m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x8000
m_objId = 1013578649 m_indexId = 0 m_prevPage = (0:0)
m_nextPage = (0:0) pminlen = 52 m_slotCnt = 82
m_freeCnt = 3075 m_freeData = 5009 m_reservedCnt = 0
m_lsn = (2689:87968:2) m_xactReserved = 0 m_xdesId = (0:0)
m_ghostRecCnt = 0 m_tornBits = 0
.................
object_id를 알아 낼 수 있다.
7. object 확인
Use DBNAME
Select object_name(OBJECT_ID)
8. 프로시저에서 해당 object를 확인하고 update 문을 찾아 그대로 update 테스트 해 본다.
이때, 해당 컬럼에 인덱스가 있는지 확인 한다. update 시 인덱스가 없으면 table scan 을 하게되고 exclusive lock 이 발생한다.
9. Key 되는 컬럼에 인덱스를 생성 해 준다.
10. 후에 다시 실행해봐서 deadlock 이 발생하는지 확인 한다.
'Monitoring' 카테고리의 다른 글
| Admin::Tempdb 의 작업, 모니터링 (0) | 2011.01.30 |
|---|---|
| T_SQL::SP_WHO2 + DBCC (0) | 2010.06.03 |
| CPU에 할당된 Task 보기 (1) | 2010.03.14 |
| DBCC FLUSHPROCINDB (0) | 2010.02.04 |
 Prev
Prev

