'Peformance Tuning'에 해당되는 글 21건
- 2015.09.14 Index IGNORE_DUP_KEY 옵션 TEST 1
- 2012.11.19 파티션 테이블 - 문제점, 주의 사항
- 2012.01.29 query plan의 실행 옵션 보기
- 2012.01.22 Dynamic Management Views
- 2011.10.10 Hash Join 제약.
- 2011.10.10 Join의 종류 1
- 2011.01.16 Tuning::Top 10 SQL Server performance Tuning
- 2011.01.16 SQL Server Best Practices Article
- 2011.01.16 Storage Top 10 Best Practices
- 2010.08.24 RML ReadTrace 분석에 필요한 이벤트
- 2010.06.07 dm_os_performance_counters , Server/Process Information
- 2010.06.04 저장 프로시저 및 함수의 마법 깨트리기 #1
- 2010.06.03 성능::ReadTrace 사용법
- 2010.06.03 SQL서버 성능카운터
- 2010.06.03 성능::엑셀이용분석하기
Index IGNORE_DUP_KEY 옵션 TEST
|
No |
방법 |
문제점 |
|
1 |
클러스터 Key IGNORE_DUP_KEY 옵션 |
온라인 Reindex가
되지 않음 -DBA 상에서 관리 이슈 있음 |
|
2 |
유니크 Index를 생성하고 IGNORE_DUP_KEY 옵션 |
No 1의 문제점 해결 |
|
3 |
쿼리 문을 수정 하는 방법 |
Insert 문을 수정해서 입력 하는 방법 -- Insert 문 수정 with except INSERT dbo.PKDUP (pk) select i from dbo.DUMP_INSERT where i between 10000 and 130000 except select pk from dbo.PKDUP
-- merge 문 사용 MERGE dbo.PKDUP AS b USING (SELECT i FROM dbo.DUMP_INSERT WHERE i BETWEEN 10000 AND 130000) AS s ON s.i = b.pk WHEN NOT MATCHED THEN INSERT (pk) VALUES (s.i);
|
|
4 |
INSTEAD OF trigger 사용 방법 |
3번 으로 하면 가장 좋으나 대량의 bulk 성으로 입력을 해야
하는 경우 대안이 될 수 있을 것 같음 |
|
CREATE TABLE dbo.PK_DUP ( pk int NOT NULL, CONSTRAINT PK_PK_DUP PRIMARY KEY (pk) WITH (IGNORE_DUP_KEY = ON) ); GO select * from sys.indexes where object_id = object_id ('PK_DUP') -- Unique values INSERT dbo.PK_DUP (pk) VALUES (1), (3), (5); GO -- key 3 already exists INSERT dbo.PK_DUP (pk) VALUES (2), (3), (4); /* 중복 키가 무시되었습니다. (2개 행이 영향을 받음) */ select * from PK_DUP /* pk 1 2 3 4 5 */ /** Problem 1 : Rebild를 할 수 없다. **/ ALTER INDEX PK_PK_DUP ON dbo.PK_DUP REBUILD WITH (FILLFACTOR = 90, ALLOW_ROW_LOCKS = OFF, ONLINE = ON, IGNORE_DUP_KEY = ON); GO /* 메시지 1979, 수준 16, 상태 1, 줄 1 인덱스 옵션 ignore_dup_key는 PRIMARY KEY 또는 UNIQUE 제약 조건을 적용하므로 이 인덱스 옵션을 사용하여 인덱스 'PK_PK_DUP'을(를) 변경할 수 없습니다. */ |
[성능 TEST No2]
|
-- 새로운 Idea -- 유니크 key를 만들어서 처리 한다. CREATE TABLE dbo.PKDUP (pk int NOT NULL CONSTRAINT PK_PKDUP PRIMARY KEY); GO INSERT dbo.PKDUP (pk) VALUES (1), (2), (3); GO -- New constraint (or index) with IGNORE_DUP_KEY, added ONLINE ALTER TABLE dbo.PKDUP ADD CONSTRAINT UIDX_PKDUP UNIQUE NONCLUSTERED (pk) WITH (IGNORE_DUP_KEY = ON, ONLINE = ON); select * from sys.indexes where object_id = object_id ('PKDUP')
-- key 3을 입력 한다. INSERT dbo.PKDUP (pk) VALUES (3), (4), (5); GO /*중복 키가 무시되었습니다. */ SELECT pk FROM dbo.PKDUP; /* pk 1 2 3 4 5 */ -- Problem 1 해결 ALTER INDEX PK_PKDUP ON dbo.PKDUP REBUILD WITH (FILLFACTOR = 90, ALLOW_ROW_LOCKS = OFF, ONLINE = ON); GO ALTER INDEX UIDX_PKDUP ON dbo.PKDUP REBUILD WITH (FILLFACTOR = 100, ALLOW_ROW_LOCKS = OFF, ONLINE = ON); GO No1의 문제는 해결 되나 성능 상의 이슈로 입력 하는 데이터와 기존 데이터를 비교 하는 추가 적인 작업 단계가 늘어나면서
예상 비용이 3배 정도 증가 함. |


[성능 TEST No3]
|
CREATE TABLE DUMP_INSERT ( i int ) set nocount on declare @i int set @i =1 while (@i < 10000 ) begin insert into DUMP_INSERT values ( @i ) set @i = @i + 1 end insert into PKDUP select * from DUMP_INSERT set nocount on declare @i int set @i =90000 while (@i < 110001 ) begin insert into DUMP_INSERT values ( @i ) set @i = @i + 1 end -- 유니크 Index 삭제 alter table dbo.PKDUP drop constraint UIDX_PKDUP set nocount on declare @i int set @i =120001 while (@i < 150001 ) begin insert into DUMP_INSERT values ( @i ) set @i = @i + 1 end
-- Insert 문 수정 with except INSERT dbo.PKDUP (pk) select i from dbo.DUMP_INSERT where i between 10000 and 130000 except select pk from dbo.PKDUP
n 여전히 Buffer pool 공간은 사용 하지만 예상 비용은 0.96
-- merge 문 사용 MERGE dbo.PKDUP AS b USING (SELECT i FROM dbo.DUMP_INSERT WHERE i BETWEEN 10000 AND 130000) AS s ON s.i = b.pk WHEN NOT MATCHED THEN INSERT (pk) VALUES (s.i);
- 비용은 증가하나 Buffer pool 공간은 사용하지 않음
|


성능 TEST No4]
|
-- INSTEAD OF trigger -- INSTEAD OF 트리거는 트리거 문의 표준 동작을 무시합니다. -- 따라서 이 트리거를 사용하여 하나 이상의 열에서 오류나 값을 확인하고 행을 삽입, 업데이트 또는 삭제하기 전에 추가 동작을 수행할 수 있습니다. -- INSTEAD OF 트리거가 제약 조건을 위한 하면 AFTER 트리거는 실행되지 않습니다. CREATE TRIGGER tI_PKDUP ON DBO.PKDUP INSTEAD OF INSERT AS BEGIN SET NOCOUNT ON INSERT dbo.PKDUP (pk) SELECT PK FROM INSERTED except select pk from dbo.PKDUP END GO INSERT dbo.PKDUP (pk) SELECT i FROM dbo.DUMP_INSERT WHERE i BETWEEN 10000 AND 130000
- Mearge랑 비슷한 예상 비용이 발생 함. 트리거 사용을 권하지는 않지만 대량 데이터 입력으로 인해 No3 번이 불가능 할 때 고려해 볼 만 함.
|

'Peformance Tuning' 카테고리의 다른 글
| 파티션 테이블 - 문제점, 주의 사항 (0) | 2012.11.19 |
|---|---|
| query plan의 실행 옵션 보기 (0) | 2012.01.29 |
| Dynamic Management Views (0) | 2012.01.22 |
| Hash Join 제약. (0) | 2011.10.10 |
Partitioned Tables, Indexes and Execution Plans: a Cautionary Tale23 October 2012
SQL Server 2005 에서 Partitioned Tables 기능이 나왔을때 우리는 기대를 했다.
많은 데이터를 최소한의 locking 으로 Switch 할 수 있을 것이라고, 그리고 쿼리 성능에도 좋은 영향을 미칠 것이라고..
그러나 무료 제공하는 점심 같은것은 없었다. 파티션 되면서 더 많은 저장 공간이 요구되었다.
Storage space increase
파티션을에 대한 계획을 할 때 꼭, 클러스터된 인덱스 key가 포함되어야 합니다. 불행이도 파티션되어야 하는 key가 고유한 인덱스가 아닐 수도 있습니다. 이 해결책은 클러스터된 인덱스에 포함시키는 방법입니다.
non-clustered index는 clustered index 의 key point를 가지고 있습니다. 파티션 테이블은 일반적으로 대형이며, 클러스터 된 인덱스 키에 새 열을 추가하면, non-clustered index의 모든 레코드가 증가됩니다.
예를 들어 500,000,000 테이블에 clustered index 에 8 byte 날짜 열이 추가된다고 가정해 보면
500000000 * 8/1024/1024/1024 = 3.75GB 인덱스당 저장공간이 증가됩니다.
이 수치는 스토리지 오버헤드의 저장공간은 포함되지 않습니다.
이 증가된 용량은 백업 시간, 복구 시간도 증가하게되며, 색인 유지 보수 비용도 증가합니다.
불행하게도 이 작업에 대한 해결책은 존재하지 않습니다.
데이터가 13개월을 가지고 있고 12개월 데이터를 select 를 매년 초에 해야 한다고 한다면 당연히 날짜 Data가 파티션 key에 존재해야 하며, 파티션이 슬라이등 되어야 합니다. 그러나, 오히려 작은 단위로 데이터를 삭제 하는것이 더 효율 적입니다.
기존 테이블을 파티션 하기 위해 clustered index에 열을 추가하는 것도 쉽지 않습니다.
그나마 대안으로는 indentity 컬럼이 있을 경우 해당 월이 시작되는 값을 알아내어, 그 key로 파티션 하는 것입니다.
저장 공간 뿐 아니라, 실행계획에 대해서도 살펴봐야 합니다.
Suboptimal execution plans
파티셔닝을 구현할 때, 물리적 데이터 레이아웃이 변경됨으로 퀴러의 실행 계획이 예기치 못한 결과를 나타낼 수도 있습니다.
그림 참고)
Listing 1 shows the structure of the Orders table, with clustered index.
GO
CREATE TABLE dbo.Orders
(
Id INT NOT NULL ,
OrderDate DATETIME NOT NULL ,
DateModified DATETIME NOT NULL ,
Placeholder CHAR(500)
NOT NULL
CONSTRAINT Def_Data_Placeholder DEFAULT 'Placeholder',
);
GO
CREATE UNIQUE CLUSTERED INDEX IDX_Orders_Id
ON dbo.Orders(ID);
GO
Listing 1: The Orders table structure
Listing 2 inserts 524,288 records into the Orders table and creates a non-clustered index.
WITH N1 ( C )
AS ( SELECT 0
UNION ALL
SELECT 0
)-- 2 rows
, N2 ( C )
AS ( SELECT 0
FROM N1 AS T1
CROSS JOIN N1 AS T2
)-- 4 rows
, N3 ( C )
AS ( SELECT 0
FROM N2 AS T1
CROSS JOIN N2 AS T2
)-- 16 rows
, N4 ( C )
AS ( SELECT 0
FROM N3 AS T1
CROSS JOIN N3 AS T2
)-- 256 rows
, N5 ( C )
AS ( SELECT 0
FROM N4 AS T1
CROSS JOIN N4 AS T2
)-- 65,536 rows
, N6 ( C )
AS ( SELECT 0
FROM N5 AS T1
CROSS JOIN N2 AS T2
CROSS JOIN N1 AS T3
)-- 524,288 rows
, IDs ( ID )
AS ( SELECT ROW_NUMBER() OVER ( ORDER BY ( SELECT NULL
) )
FROM N6
)
INSERT INTO dbo.Orders
( ID ,
OrderDate ,
DateModified
)
SELECT ID ,
DATEADD(second, 35 * ID, @StartDate) ,
CASE WHEN ID % 10 = 0
THEN DATEADD(second,
24 * 60 * 60 * ( ID % 31 ) + 11200 + ID
% 59 + 35 * ID, @StartDate)
ELSE DATEADD(second, 35 * ID, @StartDate)
END
FROM IDs;
GO
CREATE UNIQUE NONCLUSTERED INDEX IDX_Orders_DateModified_Id
ON dbo.Orders(DateModified, Id);
SELECT TOP 100
ID ,
OrderDate ,
DateModified ,
PlaceHolder
FROM dbo.Orders
WHERE DateModified > @LastDateModified
ORDER BY DateModified ,
Id;
Listing 3: Query that selects the batch of the records


DROP INDEX IDX_Orders_Id ON dbo.Orders;
GO
CREATE PARTITION FUNCTION pfOrders(DATETIME)
AS RANGE RIGHT FOR VALUES
('2012-02-01', '2012-03-01',
'2012-04-01','2012-05-01','2012-06-01',
'2012-07-01','2012-08-01');
GO
CREATE PARTITION SCHEME psOrders
AS PARTITION pfOrders
ALL TO ([primary]);
GO
CREATE UNIQUE CLUSTERED INDEX IDX_Orders_OrderDate_Id
ON dbo.Orders(OrderDate,ID)
ON psOrders(OrderDate);
GO
CREATE UNIQUE INDEX IDX_Data_DateModified_Id_OrderDate
ON dbo.Orders(DateModified, ID, OrderDate)
ON psOrders(OrderDate);
GO
Listing 4: Table partitioning code



Figure 6 shows how SQL Server actually processes the query.

파티션되지 않은 테이블은 top 100 조회하면 처음 나오는 값 기준으로 정렬없이 100개를 가져오니까 비교적 효율적.
만약 파티셔닝을 구현 한다며 key가 변경되고 정렬되어 있는 것 중에 모두 데이터를 찾아야 한다. 즉, 파티션이 8개 되었다고 한다면 100의 데이터가 있는지 보다 파티션 별로 데이터를 찾아서 정렬한다.
물론, 힌트로 고정할 수도 있지만 예상치 않은 결과 이다.
Fixing the problem
그림 참고)
SELECT TOP 100
ID ,
OrderDate ,
DateModified ,
PlaceHolder
FROM dbo.Orders
WHERE DateModified > @LastDateModified
AND $partition.pfOrders(OrderDate) = 5
ORDER BY DateModified ,
ID;

간혹 이상할 경우 많이 사용하는 방법인데 파티션 범위를 확인하고 지정 파티션을 정해 주는 것이다. (파티션 된 테이블을 조건에 해당하는 데이터를 삭제 할 경우 top 10개로.. 등. 이관시 꼭 실행계획을 확인하고 해당 파티션만 찾게 범위를 지정해 줘야 하는 것이 이 이유이다. )
그러려면 파티션의 총 수를 알아야 한다.. ( ys.partition_range_values)
@BoundaryCount INT;
SELECT @BoundaryCount = MAX(boundary_id) + 1
FROM sys.partition_functions pf
JOIN sys.partition_range_values prf
ON pf.function_id = prf.function_id
WHERE pf.name = 'pfOrders';
WITH Boundaries ( boundary_id )
AS ( SELECT 1
UNION ALL
SELECT boundary_id + 1
FROM Boundaries
WHERE boundary_id < @BoundaryCount
)
SELECT part.ID ,
part.OrderDate ,
part.DateModified ,
$partition.pfOrders(part.OrderDate) AS [Partition Number]
FROM Boundaries b
CROSS APPLY ( SELECT TOP 100
ID ,
OrderDate ,
DateModified
FROM dbo.Orders
WHERE DateModified > @LastDateModified
AND $Partition.pfOrders(OrderDate) =
b.boundary_id
ORDER BY DateModified ,
ID
) part;
Listing 8: Implementation of Step 1 of "Ideal execution plan"
Dealing with Cardinality Estimation Errors
윗 부분 처럼하면 경계값 에러가 발생할 수 있다. 개선책.
tempdb를 사용한다.
(
ID INT NOT NULL
PRIMARY KEY
);
DECLARE @LastDateModified DATETIME = '2012-06-25' ,
@BoundaryCount INT;
SELECT @BoundaryCount = MAX(boundary_id) + 1
FROM sys.partition_functions pf
JOIN sys.partition_range_values prf
ON pf.function_id = prf.function_id
WHERE pf.name = 'pfOrders';
WITH Boundaries ( boundary_id )
AS ( SELECT 1
UNION ALL
SELECT boundary_id + 1
FROM Boundaries
WHERE boundary_id < @BoundaryCount
)
INSERT INTO #T
( ID
)
SELECT boundary_id
FROM Boundaries;
WITH Top100 ( ID, OrderDate, DateModified )
AS ( SELECT TOP 100
part.ID ,
part.OrderDate ,
part.DateModified
FROM #T b
CROSS APPLY ( SELECT TOP 100
ID ,
OrderDate ,
DateModified
FROM dbo.Orders
WHERE DateModified >
@LastDateModified
AND $Partition.pfOrders(OrderDate) =
b.id
ORDER BY DateModified ,
ID
) part
ORDER BY part.DateModified ,
part.ID
)
SELECT d.Id ,
d.OrderDate ,
d.DateModified ,
d.Placeholder
FROM dbo.Orders d
JOIN Top100 t ON d.Id = t.Id
AND d.OrderDate = t.OrderDate
ORDER BY d.DateModified ,
d.ID;
DROP TABLE #T;
Listing 10: Using a temporary table in order to improve cardinality estimation

Figure 11: Using temporary table in order to improve cardinality estimation
Hardcoding the number of Partitions
그림 참고)
WITH Boundaries ( boundary_id )
AS ( SELECT V.v
FROM ( VALUES ( 1), ( 2), ( 3), ( 4), ( 5), ( 6), ( 7),
( 8) ) AS V ( v )
),
Top100 ( ID, OrderDate, DateModified )
AS ( SELECT TOP 100
part.ID ,
part.OrderDate ,
part.DateModified
FROM Boundaries b
CROSS APPLY ( SELECT TOP 100
ID ,
OrderDate ,
DateModified
FROM dbo.Orders
WHERE DateModified >
@LastDateModified
AND $Partition.pfOrders(OrderDate) =
b.boundary_id
ORDER BY DateModified ,
ID
) part
ORDER BY part.DateModified ,
part.ID
)
SELECT d.Id ,
d.OrderDate ,
d.DateModified ,
d.Placeholder
FROM dbo.Orders d
JOIN Top100 t ON d.Id = t.Id
AND d.OrderDate = t.OrderDate
ORDER BY d.DateModified ,
d.ID;
Listing 11: Hardcode static number of partitions in order to improve cardinality estimation

Figure 12: Hardcode static number of partitions in order to improve cardinality estimation
윗 부분 처럼 하면 사용하고자 하는 메모리보다 더 많은 메모리를 사용하게 된다. ( 일부 파티션에 데이터가 없는 경우)
파티션 수를 하드 코딩 한다. -> 파티션을 추가 되었을 경우 수정해야 한다. 이론.. ㅜㅜ;;
Summary
테이블 파티셔닝은 다양한 디자인과 성능 문제에 도움을 줄 수 있는 훌륭한 기능이지만, 또한 문제 집합을 만 들 수도 있습니다.
clustered index에 파티션 열을 추가하면 저장공간 및 인덱스 유지 보수 비용이 증가합니다.
다른 물리적 데이터 레이아웃 변경이 될 경우 실행 계획이 변화 될 수 있습니다. 이런 부작용이 있다는것을 알고 적용하기 전에 꼭 Test 해봐야 합니다.
==> 그래서 처음 설계 부터 파티션 하게 하거나, 자주 조회되지 않은 과거 테이블이나 이력 테이블을 적용하고 있고
또는 키를 변경하기 보다는 기존 key의 범위로 파티션 key를 사용하고 있다, 물론 조회되는 중요 sp들의 조건 절을 확인한다.
기존 테이블을 파티셔닝 하는것은 항상 조심해야 한다.
'Peformance Tuning' 카테고리의 다른 글
| Index IGNORE_DUP_KEY 옵션 TEST (1) | 2015.09.14 |
|---|---|
| query plan의 실행 옵션 보기 (0) | 2012.01.29 |
| Dynamic Management Views (0) | 2012.01.22 |
| Hash Join 제약. (0) | 2011.10.10 |
- sql server에 실행되고 있는 query 들의 실제 plan 하고 다르게 테스트 한 plan이 다르게 나타나는 경우가 있다.
- 실제 서버에서 실행되는 옵티마이저가 판단하는 세션에 대한 옵션이 다를 수 있기 때문이다.
- 실행되는 plan_handle 값에 대한 속성 값을 아래 쿼리에서 확인 할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | SELECT DEQP.query_plan, DEPA.attribute, DEPA.value FROM sys.dm_exec_cached_plans DECP CROSS APPLY sys.dm_exec_query_plan(DECP.plan_handle) AS DEQP CROSS APPLY sys.dm_exec_plan_attributes(DECP.plan_handle) AS DEPA WHERE DECP.plan_handle = (0x0600010069AB592540617182000000000000000000000000)-- 특정 login 에 대한 옵션SELECT SDEQP.query_plan, SDEPA.attribute, SDEPA.value FROM sys.dm_exec_cached_plans SDECP INNER JOIN sys.dm_exec_requests SDER ON SDECP.plan_handle = SDER.plan_handle INNER JOIN sys.dm_exec_sessions SDES ON SDER.session_id = SDES.session_id CROSS APPLY sys.dm_exec_query_plan(SDECP.plan_handle) AS SDEQP CROSS APPLY sys.dm_exec_plan_attributes(SDECP.plan_handle) AS SDEPA WHERE SDES.login_name = 'bora-PC\bora' |
'Peformance Tuning' 카테고리의 다른 글
| Index IGNORE_DUP_KEY 옵션 TEST (1) | 2015.09.14 |
|---|---|
| 파티션 테이블 - 문제점, 주의 사항 (0) | 2012.11.19 |
| Dynamic Management Views (0) | 2012.01.22 |
| Hash Join 제약. (0) | 2011.10.10 |
|
출처:http://www.mssqltips.com/sqlservertutorial/273/dynamic-management-views/ 정리가 잘 되어있어서 가져왔습니다.
Dynamic Management Views (Tools) |
Overview
With the introduction of SQL Server 2005, Microsoft introduced Dynamic Management Views (DMVs) which allow you to get better insight into what is happening in SQL Server. Without these new tools a lot of the information was unavailable or very difficult to obtain.
DMVs are a great tool to help troubleshoot performance related issues and once you understand their power they will become a staple for your Database Administration.
Explanation
The DMVs were introduced in SQL 2005 and with each new release, Microsoft has been adding additional DMVs to help troubleshoot issues. DMVs actually come in two flavors DMVs (dynamic management views) and DMFs (dynamic management functions) and are sometimes classified as DMOs (dynamic management objects). The DMVs act just like any other view where you can select data from them and the DMFs require values to be passed to the function just like any other function.
The DMVs are broken down into the following categories:
- Change Data Capture Related Dynamic Management Views
- Change Tracking Related Dynamic Management Views
- Common Language Runtime Related Dynamic Management Views
- Database Mirroring Related Dynamic Management Views
- Database Related Dynamic Management Views
- Execution Related Dynamic Management Views and Functions
- Extended Events Dynamic Management Views
- Full-Text Search Related Dynamic Management Views
- Filestream-Related Dynamic Management Views (Transact-SQL)
- I/O Related Dynamic Management Views and Functions
- Index Related Dynamic Management Views and Functions
- Object Related Dynamic Management Views and Functions
- Query Notifications Related Dynamic Management Views
- Replication Related Dynamic Management Views
- Resource Governor Dynamic Management Views
- Service Broker Related Dynamic Management Views
- SQL Server Operating System Related Dynamic Management Views
- Transaction Related Dynamic Management Views and Functions
- Security Related Dynamic Management Views
Here are some of the more useful DMVs that you should familiarize yourself with:
- sys.dm_exec_cached_plans - Cached query plans available to SQL Server
- sys.dm_exec_sessions - Sessions in SQL Server
- sys.dm_exec_connections - Connections to SQL Server
- sys.dm_db_index_usage_stats - Seeks, scans, lookups per index
- sys.dm_io_virtual_file_stats - IO statistics for databases and log files
- sys.dm_tran_active_transactions - Transaction state for an instance of SQL Server
- sys.dm_exec_sql_text - Returns TSQL code
- sys.dm_exec_query_plan - Returns query plan
- sys.dm_os_wait_stats - Returns information what resources SQL is waiting on
- sys.dm_os_performance_counters - Returns performance monitor counters related to SQL Server
Additional Information
Here are some additional articles about DMVs.
'Peformance Tuning' 카테고리의 다른 글
| 파티션 테이블 - 문제점, 주의 사항 (0) | 2012.11.19 |
|---|---|
| query plan의 실행 옵션 보기 (0) | 2012.01.29 |
| Hash Join 제약. (0) | 2011.10.10 |
| Join의 종류 (1) | 2011.10.10 |
if object_id('tblx') is not null
drop table tblx
go
if object_id('tbly') is not null
drop table tbly
go
create table tblx
(idx int
,c1 int
)
go
create table tbly
(idx int
,c1 int
)
go
insert into tblx values (1,1)
insert into tblx values (1,2)
insert into tbly values (1,1)
insert into tbly values (2,null)
go
select * from tblx
select * from tbly
set statistics profile on
select *
from tblx a
join tbly b
on a.idx = b.idx
where a.idx > 1
option (hash join)

select *
from tblx a
join tbly b
on a.idx = b.idx
where a.idx = 1
option (hash join)
메시지8622, 수준16, 상태1, 줄1
이쿼리에정의된힌트로인해쿼리프로세서에서쿼리계획을생성할수없습니다. 힌트를지정하거나SET FORCEPLAN을사용하지않고쿼리를다시전송하십시오.
-
select *
from tblx a
join tbly b
on a.idx = b.idx
where a.idx = 1

- Hash Join은 적어도 하나의 equijoin predicate가 있어야 풀 수 있다. 그런데 위 커리는 그런 부분이 없다. Mearge join도 마찬가지다.
select *
from tblx a
full outer join tbly b
on a.idx = 1
option (merge join)
- 위 쿼리는 가능하다. Full outer mearge join의 경우 non equijion도 가능하기 때문이다.
select *
from tblx a
join tbly b
on a.idx > b.idx

- Hash join이 가능한가? 안된다. Hash 함수는 통과한 값의 크다 작다를 비교할 수 없다.
-
select *
from tblx a
join tbly b
on a.idx > b.idx
option (hash join)
메시지 8622, 수준 16, 상태 1, 줄 1
이 쿼리에 정의된 힌트로 인해 쿼리 프로세서에서 쿼리 계획을 생성할 수 없습니다. 힌트를 지정하거나 SET FORCEPLAN을 사용하지 않고 쿼리를 다시 전송하십시오.
if object_id('tblx') is not null
drop table tblx
go
if object_id('tbly') is not null
drop table tbly
go
create table tblx
(idx int
,c1 int
)
go
create table tbly
(idx int
,c1 int
)
go
insert into tblx values (1,1)
insert into tblx values (2,2)
insert into tbly values (1,1)
insert into tbly values (2,null)
go
select * from tblx where c1 in (select c1 from tbly) option(hash join)
select * from tblx where c1 not in (select c1 from tbly) option(hash join)
에러. null 있다.
- Tblx에 c1 컬럼에 not null 체크조건을 주거나 null을 입력하지 않으면 hash join을 잘 사용할 수 있다.
혹은 아래 처럼 한다. 그래야 equijoin predicate 가 존재한다.
select * from tblx where c1 not in (select c1 from tbly where c1 is not null)
and c1 is not null option(hash join)
'Peformance Tuning' 카테고리의 다른 글
| query plan의 실행 옵션 보기 (0) | 2012.01.29 |
|---|---|
| Dynamic Management Views (0) | 2012.01.22 |
| Join의 종류 (1) | 2011.10.10 |
| Tuning::Top 10 SQL Server performance Tuning (0) | 2011.01.16 |
1) 조인의 종류 : 물리적인 방법의 조인을 말한다.
A. 중첩 루프 (Nested Lopp) 조인
B. 병합 (Merge) 조인
C. 해시 (Hash) 조인
D. Remote 조인

- Row 많아질수록 쿼리의 Cost가 높아진다, Loop가 가장 기본 적인 방법이며, 양이 적을때에는 성능이 좋지만 데이터가 많아질수록 비용도 급격히 증가한다.
- Merge 방식은 데이터가 적을 경우에는 Loop 보다는 못하지만, 양이 많아 질수록 더 뛰어난 성능을 보인다.
- Hash 방식은 데이터가 얼마 없을 경우에는 Overhead로 인하여 성능이 좋지 않지만 데이터가 많을수록 Loop 보다는 낮고 Merge 보다는 못하게 비용이 증가한다.
1) Nested Loop (중첩 루프 조인)
- 한집합의 원소값을 다른 집합의 원소 값과 매칭해 나가는 작업, 가능한 모든 경우를 조회하여 결과 집합을 찾는 방법
- 선행테이블 (Drving Table ) = 바깥 테이블 = 찾는 주체가 되는 테이블
- 후행 테이블 (Driven Table) = 안쪽 테이블 = 비교 대상이 되는 테이블
- 여기서 바깥/안쪽 의 의미는 조인에서의 위치가 아닌 먼저 조회 되느냐 마느냐의 의미임.
- 힌트가 없을시에는 선행테이블은 옵티마이저가 알아서 배치하나 힌트가 있을 시에는 테이블 배치 순서에 따른다.
- 성능을 높이기 위한 방법
n 후행 테이블의 크기가 작을수록, 후해 테이블에 인덱스가 미리 설정되어야 한다.
n 선행 테이블이 이미 sort되어 있으면 좀 더 빠르다.


- set statistics io on
-
- select e.emp_id, e.fname + e.lname as name, j.job_id, j.job_desc
- from dbo.employee as e with(nolock)
- join jobs as j with(nolock) on e.job_id = j.job_id
- 테이블 'jobs'. 검색 수 43, 논리적 읽기 수 86,
- 테이블 'employee'. 검색 수 1, 논리적 읽기 수 2,

- 실행계획에 employee 부터 읽혀지며, job_id에 인덱스가 없기 때문에 full scan 하는것과 동일하다. 아래 그림처럼 emplolyee의 job_id를 읽어서 순서대로 jobs테이블에 찾는 작업을 한다.
- Employee 테이블의 row수가 43개 행이기 때문에 jobs을 43번 scan 한다.

그럼 강제로 jobs를 선행 테이블로 읽게 변경해 보자.
- select e.emp_id, e.fname + e.lname as name, j.job_id, j.job_desc
- from jobs as j with(nolock)
- join employee as e with(nolock) on e.job_id = j.job_id
- option (force order, loop join)
-
- --테이블'employee'. 검색수14, 논리적읽기수29
- --테이블'jobs'. 검색수1, 논리적읽기수2

- Cost 비용을 봐서는 jobs늘 선행 테이블로 해서 강제로 loop 하는것이 더 좋아보인다.
- Jobs 테이블의 row 수만큼 employee 를 풀 스캔 한다. (14개)
- 아래 쿼리는 두 테이블의 데이터 길이이다.
- select CAST( sum( datalength(emp_id) + datalength(fname) + datalength(minit)
- + datalength(lname) + datalength(job_id) + datalength (job_lvl) + DATALENGTH(pub_id)
- + DATALENGTH(hire_date)) as varchar) + ' byte'
- from employee with(nolock)
- --1607 byte
-
- select CAST( sum( datalength(job_id) + datalength(job_desc) + datalength(min_lvl)
- + datalength(max_lvl) ) as varchar) + ' byte'
- from JOBS with(nolock)
- --314 byte
- 첫번째 쿼리는 employee 테이블 만큼 스캔 하였으니 1067 바이트 만틈 읽었고 jobs는 clustred index seek 하였으니 314 바이트 만큼 읽었다. 총 1067+ 314 = 1921 byte
- 두번째 쿼리는 jobs를 먼저 full scan 하였으므로 (1067 * 14) + 314 = 22812 byte
- 첫번째 쿼리가 11배 정도 입/출력이 작다. 쿼리의 성능을 입/출력 양으로 측정은 쿼리 수행 속도를 결정한다., 위 두 쿼리는 어떤 테이블을 사용하던지 한쪽은 full scan 해야 한다.
create index IDX_EMPLOYEE_JOB_ID on employee ( job_id)
- 인덱스를 생성하고 두번째 쿼리를 다시 실행하면 employee 를 index seek 하기 때문에 좀 더 성능이 좋아진다.

- 일반적으로 테이블의 10% 정도까지의 데이터를 접근할 때 인덱스를 사용하는 것이 낮다고 한다 실제적으로 쿼리 수행해보면 (8% 정도 였던것 같기도 함) 그러나 이것도 상대적이다 1억건의 테이블에서 1천만건을 읽는데 인덱스 이용하면 오래 걸린다. 인덱스로 한건 한건 접근하기 때문이다.
- 인덱스를 사용하지 않고 조인 한다면
- select e.emp_id, e.fname + e.lname as name, j.job_id, j.job_desc
- from jobs as j with(index(0))
- join employee as e with(index(0)) on e.job_id = j.job_id
- 테이블 'employee'. 검색 수 1, 논리적 읽기 수 2
- 테이블 'jobs'. 검색 수 1, 논리적 읽기 수 2,

- Hash 조인을 사용한다. Merge join의 경우 sort를 하기 때문에 비용이 더 많이 든다. 이 두 테이블은 row수가 많이 않기 때문에 hash join이 가장 적합하다.
2) Mearge Join (병합조인)
- 전제 조건은 양 테이블이 모두 조인 키에 의해 정렬되어 있어야 함.
- 선행,후행 테이블의 크기는 성능과 관련이 없다, 그러나 선행 테이블이 중복 행이 존재하지 않을 때, 즉 고유할 때, 메모리 사용량이 적으며, 이것이 권장된다.
- 병합조인은 중복 행이 존재한다면 어지간히 해서 발생하지 않는다, 그래서 다:1 관계에서 발생하지 다:다 에서는 발생하지 않는다. 이럴 경우는 hash join을 한다.
- 큰 장점은 양쪽 테이블에서 스캔 수가 한번 일어난다.
- 데이터가 많을 때 이미 정렬되어 있기 때문에 전부 찾지 않는다.
- 정렬되어 있지 않다면 정렬 하는 작업을 하기 때문에 메모리를 더 사용할 수 있다. 그래서 유니클 할때만 힌트를 사용해서 고정하는 것이 좋다. 그렇지 않으면 정렬 비용이 발생하고 tempdb의 페이지 할당이 증가된다.
- select *
- from employee as e
- join jobs as j on e.job_id = j.job_id
- option(merge join)
테이블'jobs'. 검색수1, 논리적읽기수2
테이블'employee'. 검색수1, 논리적읽기수88

3) Hash Join
- 선행 테이블을 해시 버킷을 만드는데 사용되며, 이것을 빌드 입력이라고 부른다. 후행 테이블은 검색입력 이라고 부른다.
- 선행 테이블은 후행 테이블이 처리되기 전에 완전히 읽혀져야 함으로 응답 시간이 조인들 중에서 가장 늦다.
- 작은 테이블이 선행 테이블로 사용되어져야 한다. 큰 테이블이 선행 테이블이 되면 해시 버킷을 만들어야 하는데 메모리 사용량이 늘어 난다.
- 해시조인의 결과의 순서가 없다 그래서 순서가 필요하다면, ORDER BY를 꼭 명시해야 한다.
- 인덱스가 없을 때 주로 해시 조인이 사용된다.
- select *
- from employee as e
- join jobs as j on e.job_id = j.job_id
- option(hash join)
- 테이블 'employee'. 검색 수 1, 논리적 읽기 수 2
- 테이블 'jobs'. 검색 수 1, 논리적 읽기 수 2,
1) Input Order 필요한가?
요즘 옵티마이저는 똑똑해서 필요 없다.
- Loop join : 아니다, 하지만 더 낳은 성능을 위해 선행 테이블이 정렬될 수도 있다.
- Merge join : 양 테이블이 반드시 조인 키에 의해 정렬되어 있어야 한다.
- Hash join : 필요 없다.
2) Sort Order 필요한가?
- Loop join : 선행 테이블
- Merge join : 둘 다
- Hash join : 필요 없다.
3) 선행/후행 테이블 선택은 어떻게 ?
- Loop join : 후행 테이블은 인덱스가 있거나 작아야 한다.
- Merge join : 별로 중요하지 않다.
- Hash join : 작은 테이블이 선행 테이블이 되어야 한다.
4) 메모리 사용량
- Loop join : 추가 메모리 필요 없다.
- Merge join : back loop 위해 추가 메모리 필요
- Hash join : 해시 버킷을 위해 추가 메모리 필요
'Peformance Tuning' 카테고리의 다른 글
| Dynamic Management Views (0) | 2012.01.22 |
|---|---|
| Hash Join 제약. (0) | 2011.10.10 |
| Tuning::Top 10 SQL Server performance Tuning (0) | 2011.01.16 |
| SQL Server Best Practices Article (0) | 2011.01.16 |
Tuning::Top 10 SQL Server performance Tuning
SQL Server Magazine 2011.01 Cover Store
- Andrew J.Kelly
1. TIP 1: Stop Waiting Around
먼저 Waits and Queues 대해서 알아야 한다. 많이 보이는 Waits Type에 대해 알고 있어야, 튜닝을 할 수 있다.
2. TIP 2:Locate I/O Bottlenecks
I/O bottlenecks 에는 Performance의 중요한 key다. page_I/O_latch waits 혹은 log_write 대기가 발생하는지 살펴봐야 한다.
sys.dm_io_virtual_file_stats() 를 통해서 확인이 가능하다.
성능 counter Avg.Disk sec/Read , Avg sec/Write 카운터를 살펴본다.
OLTP 환경에서는 log file 대기는 몇 ms 초여야 한다. 적어도 10ms 이하여야 한다. 허나, 이보다 높을 경우에도 서비스에는 문제되지 않을 수 있다. 항상 자기 서버의 base line을 알아야 한다.
3. Tip 3: Root out Problem Queries
놀랍게도 서비스에 문제되는 쿼리는 8~ 10개 정도이다. 이 쿼리들이 해당 리소스를 80 ~ 90% 사용한다.
그러므로 문제되는 쿼리를 찾아서 튜닝을 해야 한다.
sys.dm_execc_query_stats, sys.dm_exec_cached_plans, sys.dm_exec_sql_text()를 이용
-> 각자에 맞는 쿼리를 만들어야 한다. 저 같은 경우도 주기적으로 쿼리하여 적재하고 모니터링 한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | SELECTCOALESCE(DB_NAME(t.[dbid]),'Unknown') AS [DB Name],ecp.objtype AS [Object Type],t.[text] AS [Adhoc Batch or Object Call], SUBSTRING(t.[text], (qs.[statement_start_offset]/2) + 1, ((CASE qs.[statement_end_offset] WHEN -1 THEN DATALENGTH(t.[text]) ELSE qs.[statement_end_offset] END - qs.[statement_start_offset])/2) + 1) AS [Executed Statement] , qs.[execution_count] AS [Counts] , qs.[total_worker_time] AS [Total Worker Time], (qs.[total_worker_time] /qs.[execution_count]) AS [Avg Worker Time] , qs.[total_physical_reads] AS [Total Physical Reads],(qs.[total_physical_reads] / qs.[execution_count]) AS [Avg Physical Reads] , qs.[total_logical_writes] AS [Total Logical Writes],(qs.[total_logical_writes] / qs.[execution_count]) AS [Avg Logical Writes] , qs.[total_logical_reads] AS [Total Logical Reads],(qs.[total_logical_reads] / qs.[execution_count]) AS [Avg Logical Reads] , qs.[total_clr_time] AS [Total CLR Time], (qs.[total_clr_time] /qs.[execution_count]) AS [Avg CLR Time] , qs.[total_elapsed_time] AS [Total Elapsed Time], (qs.[total_elapsed_time]/ qs.[execution_count]) AS [Avg Elapsed Time] , qs.[last_execution_time] AS [Last Exec Time], qs.[creation_time] AS [Creation Time]FROM sys.dm_exec_query_stats AS qs JOIN sys.dm_exec_cached_plans ecp ON qs.plan_handle = ecp.plan_handle CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS t-- ORDER BY [Total Worker Time] DESC-- ORDER BY [Total Physical Reads] DESC-- ORDER BY [Total Logical Writes] DESC-- ORDER BY [Total Logical Reads] DESC-- ORDER BY [Total CLR Time] DESC-- ORDER BY [Total Elapsed Time] DESC ORDER BY [Counts] DESC |
4.Tip 4: Plan to Reuse
Plan을 재 사용하는지 확인 한다.
5. Tip 5: Monitor Index Usage
sys.dm_db_index_operational_stats() DMF를 이용해서 인덱스가 잘 사용되고 있는지, 어떤 정보로 사용되는지 확인한다.
6. Tip 6: Separate Datea and Log File
7. Tip 7:Use Separate Staging Database
Temp성 데이터를 exporting or importing 하는데는 많은 비용이 들어간다. 서비스되고 있는 DB는 Full 모드이라면 모든 활동을 logging 한다.
몇몇 DB는 성능 이익을 위해서 simple 모드로 해야 한다. 작은 로깅은 성능을 향상 시키고 작은 load만 있으면 된다.
Staging Database는 Simple 모드로 하는것이 좋고 백업이 필요 없을 수도 있다.
8. Tip 8: Pay Attention to Log File
항상 Log File의 여유 공간을 확인해야 하고 증가를 주의깊게 봐야 한다.
VLFs가 증가하면 성능은 저하된다.
http://www.sqlskills.com/BLOGS/KIMBERLY/post/Transaction-Log-VLFs-too-many-or-too-few.aspx
9. Tip 9: Minimize tempdb contention
application이 tempdb를 무겁게 사용하면 내부적으로 tempdb를 할당하기 위해 contention이 발생한다.
tempdb contention은 최소화 해야 한다.
Workign with tempdb in SQL Server 2005 : http://technet.microsoft.com/en-us/library/cc966545.aspx
processor core 하나에 tempdb file 하나를 생성하기를 권장한다. 모든 같은 사이즈여야 한다.그렇지 않으면 이익이 없다.
임시성 테이블을 항상 drop 해줘야 한다.
10. Tip 10 : Change the Max Memory Limit
'Peformance Tuning' 카테고리의 다른 글
| Hash Join 제약. (0) | 2011.10.10 |
|---|---|
| Join의 종류 (1) | 2011.10.10 |
| SQL Server Best Practices Article (0) | 2011.01.16 |
| Storage Top 10 Best Practices (0) | 2011.01.16 |
'Peformance Tuning' 카테고리의 다른 글
| Join의 종류 (1) | 2011.10.10 |
|---|---|
| Tuning::Top 10 SQL Server performance Tuning (0) | 2011.01.16 |
| Storage Top 10 Best Practices (0) | 2011.01.16 |
| RML ReadTrace 분석에 필요한 이벤트 (0) | 2010.08.24 |
'Peformance Tuning' 카테고리의 다른 글
| Tuning::Top 10 SQL Server performance Tuning (0) | 2011.01.16 |
|---|---|
| SQL Server Best Practices Article (0) | 2011.01.16 |
| RML ReadTrace 분석에 필요한 이벤트 (0) | 2010.08.24 |
| dm_os_performance_counters , Server/Process Information (0) | 2010.06.07 |
ReadTrace 분석에 필요한 이벤트는 SQL2000 과 SQL2005가 다릅니다.
SQL 2000에서는 Binary (RPC:*) 컬럼이 없어도 분석에 문제가 없었는데 SQL 2005 이상에서는 이 컬럼이 꼭 있어야 분석 레포트가 가능합니다.
- SQL 2005 & 2008


- SQL 2000용
SQL:BatchStarting and RPC:Starting
Required: StartTime, TextData
Recommended: DBID
SQL:BatchCompleted and RPC:Completed
Required: StartTime, EndTime, TextData
Recommended: Reads, Writes, CPU, Duration, DBID
Audit:Logout
Required: StartTime, EndTime
Recommended: TextData, Reads, Writes, CPU, Duration
Audit:Login and ExistingConnection
Required: StartTime, EndTime
Recommended: TextData
SP:StmtStarting
Required: StartTime, TextData, ObjectID, NestLevel
Recommended: DBID
SP:StmtCompleted
Required: StartTime, EndTime, TextData, ObjectID, NestLevel
Recommended: DBID, Reads, Writes, CPU, Duration, IntegerData
'Peformance Tuning' 카테고리의 다른 글
| SQL Server Best Practices Article (0) | 2011.01.16 |
|---|---|
| Storage Top 10 Best Practices (0) | 2011.01.16 |
| dm_os_performance_counters , Server/Process Information (0) | 2010.06.07 |
| 저장 프로시저 및 함수의 마법 깨트리기 #1 (0) | 2010.06.04 |
dm_os_performance_counters , Server/Process Information
출처: http://www.sqlservercentral.com/scripts/Monitoring/68069/
This script displays data from the dynamic management view called: sys.dm_os_performance and presents it in a report. I recommend that you look closer to this view for all your statistical needs.
If you find other information that you want to include, just modify this script to reflect the additional information.
Hope you find this script useful.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 | -- SQL Doctor -- -- Welcome to the World of Databases---- By Rudy Panigas ---- Code Name: usp_dba_SQL_Server_Stats -- Date of Creation: Aug 27, 2009 - version 1.0-- Updated: Sept 3, 2009 - version 2.1 -- Comments: Code will produce a report with important information about your SQL server (2005/2008) and its processes--USE [master] -- Doesn't have to be in master database. GOIF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[usp_dba_SQL_Server_Stats]') AND type in (N'P', N'PC'))DROP PROCEDURE [dbo].[usp_dba_SQL_Server_Stats]GOSET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONGOCREATE PROC [dbo].[usp_dba_SQL_Server_Stats]ASPRINT ' SQL 2005/2008 Server Statistics'PRINT ' -------------------------------'PRINT ''PRINT ' Displaying statistics of SQL server 'PRINT ' 'PRINT '...Buffer Statistics'PRINT ' 'SELECT [counter_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%Buffer Manager%'and [counter_name] = 'Buffer cache hit ratio')OR ([object_name] LIKE '%Buffer Manager%'and [counter_name] = 'Buffer cache hit ratio base')OR ([object_name] LIKE '%Buffer Manager%'and [counter_name] = 'Page lookups/sec')OR ([object_name] LIKE '%Buffer Manager%'and [counter_name] = 'Free pages')OR ([object_name] LIKE '%Buffer Manager%'and [counter_name] = 'Total pages')OR ([object_name] LIKE '%Buffer Manager%'and [counter_name] = 'Readahead pages/sec') OR ([object_name] LIKE '%Buffer Manager%'and [counter_name] = 'Page reads/sec') OR ([object_name] LIKE '%Buffer Manager%'and [counter_name] = 'Page writes/sec') OR ([object_name] LIKE '%Buffer Manager%'and [counter_name] = 'Page life expectancy')PRINT '...Memory Statistics'PRINT ' 'SELECT [counter_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%memory manager%'and [counter_name] = 'Connection Memory (KB)') OR ([object_name] LIKE '%memory manager%'and [counter_name] = 'Granted Workspace Memory (KB)')OR ([object_name] LIKE '%memory manager%'and [counter_name] = 'Lock Memory (KB)') OR ([object_name] LIKE '%memory manager%'and [counter_name] = 'Lock Blocks Allocated') OR ([object_name] LIKE '%memory manager%'and [counter_name] = 'Lock Owner Blocks Allocated') OR ([object_name] LIKE '%memory manager%'and [counter_name] = 'Lock Blocks') OR ([object_name] LIKE '%memory manager%'and [counter_name] = 'Lock Owner Blocks') OR ([object_name] LIKE '%memory manager%'and [counter_name] = 'Maximum Workspace Memory (KB)')OR ([object_name] LIKE '%memory manager%'and [counter_name] = 'Memory Grants Outstanding') OR ([object_name] LIKE '%memory manager%'and [counter_name] = 'Memory Grants Pending') OR ([object_name] LIKE '%memory manager%'and [counter_name] = 'Optimizer Memory (KB)') OR ([object_name] LIKE '%memory manager%'and [counter_name] = 'SQL Cache Memory (KB)') OR ([object_name] LIKE '%memory manager%'and [counter_name] = 'Target Server Memory (KB)') OR ([object_name] LIKE '%memory manager%'and [counter_name] = 'Total Server Memory (KB)') PRINT '...General Statistics'PRINT ' 'SELECT [counter_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%General Statistics%'and [counter_name] = 'Active Temp Tables') OR ([object_name] LIKE '%General Statistics%'and [counter_name] = 'Temp Tables Creation Rate')OR ([object_name] LIKE '%General Statistics%'and [counter_name] = 'Logins/sec') OR ([object_name] LIKE '%General Statistics%'and [counter_name] = 'Logouts/sec') OR ([object_name] LIKE '%General Statistics%'and [counter_name] = 'User Connections') OR ([object_name] LIKE '%General Statistics%'and [counter_name] = 'Logical Connections') OR ([object_name] LIKE '%General Statistics%'and [counter_name] = 'Transactions') OR ([object_name] LIKE '%General Statistics%'and [counter_name] = 'Mars Deadlocks') OR ([object_name] LIKE '%General Statistics%'and [counter_name] = 'HTTP Authenticated Requests')OR ([object_name] LIKE '%General Statistics%'and [counter_name] = 'Processes blocked') OR ([object_name] LIKE '%General Statistics%'and [counter_name] = 'Temp Tables For Destruction') OR ([object_name] LIKE '%General Statistics%'and [counter_name] = 'Event Notifications Delayed Drop') OR ([object_name] LIKE '%General Statistics%'and [counter_name] = 'Trace Event Notification Queue') OR ([object_name] LIKE '%General Statistics%'and [counter_name] = 'SQL Trace IO Provider Lock Waits') PRINT '...Locks Statistics'PRINT ' 'SELECT [counter_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%Locks%'and [counter_name] = 'Lock Timeouts/sec')OR ([object_name] LIKE '%Locks%'and [counter_name] = 'Number of Deadlocks/sec')OR ([object_name] LIKE '%Locks%'and [counter_name] = 'Lock Waits/sec')OR ([object_name] LIKE '%Locks%'and [counter_name] = 'Lock Wait Time (ms)')OR ([object_name] LIKE '%Locks%'and [counter_name] = 'Average Wait Time (ms)')OR ([object_name] LIKE '%Locks%'and [counter_name] = 'Average Wait Time Base')OR ([object_name] LIKE '%Locks%'and [counter_name] = 'Lock Timeouts (timeout > 0)/sec')PRINT '...Total for Locks Statistics'PRINT ' 'SELECT [counter_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%Locks%'and [counter_name] = 'Lock Requests/sec' and [instance_name] ='_Total')OR ([object_name] LIKE '%Locks%'and [counter_name] = 'Lock Timeouts/sec' and [instance_name] ='_Total')OR ([object_name] LIKE '%Locks%'and [counter_name] = 'Number of Deadlocks/sec' and [instance_name] ='_Total')OR ([object_name] LIKE '%Locks%'and [counter_name] = 'Lock Waits/sec' and [instance_name] ='_Total')OR ([object_name] LIKE '%Locks%'and [counter_name] = 'Lock Wait Time (ms)' and [instance_name] ='_Total')OR ([object_name] LIKE '%Locks%'and [counter_name] = 'Average Wait Time (ms)' and [instance_name] ='_Total')OR ([object_name] LIKE '%Locks%'and [counter_name] = 'Average Wait Time Base' and [instance_name] ='_Total')OR ([object_name] LIKE '%Locks%'and [counter_name] = 'Lock Timeouts (timeout > 0)/sec' and [instance_name] ='_Total') PRINT '...Temp DB Statistics'PRINT ' 'SELECT [counter_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%Databases%'and [counter_name] = 'Data File(s) Size (KB)' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log File(s) Size (KB)' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log File(s) Used Size (KB)' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Percent Log Used' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Active Transactions' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Transactions/sec' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Repl. Pending Xacts' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Repl. Trans. Rate' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Cache Reads/sec' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Cache Hit Ratio' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Cache Hit Ratio Base' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Bulk Copy Rows/sec' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Bulk Copy Throughput/sec' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Backup/Restore Throughput/sec' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'DBCC Logical Scan Bytes/sec' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Shrink Data Movement Bytes/sec' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Flushes/sec' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Bytes Flushed/sec' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Flush Waits/sec' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Flush Wait Time' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Truncations' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Growths' and [instance_name] ='tempdb')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Shrinks' and [instance_name] ='tempdb') PRINT '...Totals of Database Statistics'PRINT ' 'SELECT [counter_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%Databases%'and [counter_name] = 'Data File(s) Size (KB)' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log File(s) Size (KB)' and [instance_name] ='_Total') OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log File(s) Used Size (KB)' and [instance_name] ='_Total') OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Percent Log Used' and [instance_name] ='_Total') OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Active Transactions' and [instance_name] ='_Total') OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Transactions/sec' and [instance_name] ='_Total') OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Repl. Pending Xacts' and [instance_name] ='_Total') OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Repl. Trans. Rate' and [instance_name] ='_Total') OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Cache Reads/sec' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Cache Hit Ratio' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Cache Hit Ratio Base' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Bulk Copy Rows/sec' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Bulk Copy Throughput/sec' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Backup/Restore Throughput/sec' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'DBCC Logical Scan Bytes/sec' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Shrink Data Movement Bytes/sec' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Flushes/sec' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Bytes Flushed/sec' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Flush Waits/sec' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Flush Wait Time' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Truncations' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Growths' and [instance_name] ='_Total')OR ([object_name] LIKE '%Databases%'and [counter_name] = 'Log Shrinks' and [instance_name] ='_Total')PRINT '...SQL Error Statistics'PRINT ' 'SELECT [instance_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%SQL Errors%'and [counter_name] = 'Errors/sec')OR ([object_name] LIKE '%SQL Errors%'and [counter_name] = 'Errors/sec')OR ([object_name] LIKE '%SQL Errors%'and [counter_name] = 'Errors/sec')OR ([object_name] LIKE '%SQL Errors%'and [counter_name] = 'Errors/sec')OR ([object_name] LIKE '%SQL Errors%'and [counter_name] = 'Errors/sec')PRINT '...SQL Statistics'PRINT ' 'SELECT [counter_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%SQL Statistics%'and [counter_name] = 'SQL Compilations/sec')OR ([object_name] LIKE '%SQL Statistics%'and [counter_name] = 'SQL Re-Compilations/sec')PRINT '...Plan Cache Statistics'PRINT ' 'SELECT [counter_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%Plan Cache%'and [counter_name] = 'Cache Hit Ratio' and [instance_name] ='_Total')OR ([object_name] LIKE '%Plan Cache%'and [counter_name] = 'Cache Hit Ratio Base' and [instance_name] ='_Total')OR ([object_name] LIKE '%Plan Cache%'and [counter_name] = 'Cache Pages' and [instance_name] ='_Total')OR ([object_name] LIKE '%Plan Cache%'and [counter_name] = 'Cache Object Counts' and [instance_name] ='_Total')OR ([object_name] LIKE '%Plan Cache%'and [counter_name] = 'Cache Objects in use' and [instance_name] ='_Total')PRINT '...Transactions Statistics'PRINT ' 'SELECT [counter_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%Transactions%')PRINT '...Wait Statistics. Average execution time (ms)'PRINT ' 'SELECT [counter_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%Wait Statistics%'and [instance_name] = 'Average execution time (ms)') --PRINT '...Wait Statistics. Waits in progress'PRINT ' 'SELECT [counter_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%Wait Statistics%'and [instance_name] = 'Waits in progress') --PRINT '...SQL Execution Statistics. Average execution time (ms)'PRINT ' 'SELECT [counter_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%Exec Statistics%'and [counter_name] = 'Extended Procedures') OR ([object_name] LIKE '%Exec Statistics%'and [counter_name] = 'DTC calls') OR ([object_name] LIKE '%Exec Statistics%'and [counter_name] = 'OLEDB calls') OR ([object_name] LIKE '%Exec Statistics%'and [counter_name] = 'Distributed Query') --PRINT '...SQL Execution Statistics. Execution in progress'PRINT ' 'SELECT [counter_name] AS 'Description', [cntr_value] AS 'Current Value' from sys.dm_os_performance_counters WHERE ([object_name] LIKE '%Exec Statistics' and [instance_name] ='Execs in progress')GO |
'Peformance Tuning' 카테고리의 다른 글
| Storage Top 10 Best Practices (0) | 2011.01.16 |
|---|---|
| RML ReadTrace 분석에 필요한 이벤트 (0) | 2010.08.24 |
| 저장 프로시저 및 함수의 마법 깨트리기 #1 (0) | 2010.06.04 |
| 성능::ReadTrace 사용법 (0) | 2010.06.03 |
저장 프로시저 및 함수의 마법 깨트리기
Herts Chen
본 자료는 OPENQUERY를 사용하여 UDF 및 SQL 문에서 저장 프로시저를 호출할 수 없는 문제를 극복하는 방법을 다룬 Herts Chen의 세 개의 시리즈 기사 중 첫 번째입니다. 이 자료에서는 OPENQUERY의 한계 중 하나에 대해 다루며 OPENQUERY가 그러한 한계를 극복하도록 하는 방법을 제시합니다.
RDBMS의 장점 중 하나는 기본이 되는 집합 기반 쿼리 언어가 SQL이라는 것입니다. 쿼리는 항상 연속되는 다량의 T-SQL 스크립트에서 실행해야 하는 경우보다는 단일 SQL 문으로 표시할 수 있을 경우 더 간결하고 더 잘 최적화됩니다. 예를 들면 레코드가 50만개인 200MB 테이블이 있다고 가정해 봅시다. 단 한 줄의 UPDATE 문으로 이 테이블 전체에서 인덱스되지 않은 열을 업데이트하려면 약 2분정도 걸릴 것입니다. 하지만 WHILE 루프에서 50만 개의 UPDATE 문을 배포하여 동일한 변경을 실행하면 거의 세 시간이 걸릴 것입니다. 하지만 단일한 SQL 문에서 이 결과를 유도해 내기가 불가능한 상황이나 “사용 사례”가 있습니다. 그러한 경우에 대한 한 가지 대안이 이러한 사용 사례의 순서 설명을 저장 프로시저 또는 사용자 정의 함수(UDF)로 캡슐화하는 것입니다.
물론, UDF는 SQL 문 내부에 직접 포함될 수 있습니다. 어떤 점에서는 SQL이 순서 설명을 필요한 만큼 모듈화하는데 함수가 도움이 되므로 함수가 SQL의 표현력을 높여줍니다. 하지만 저장 프로시저는 SQL 문으로는 표현될 수 없으므로 SQL 문 코딩의 관점에서 보면 함수가 좀더 유용한 도구라고 생각됩니다.
하지만 함수는 프로시저를 완벽하게 대체할 수 없습니다. 사실, SQL Server는 프로시저보다 함수에 대해 보다 엄격하게 제한을 둡니다. 예를 들면, 함수에서는 테이블을 업데이트한다든가 하는 글로벌 데이터베이스 상태 변경을 실행할 수 없습니다. 이 외에도 SQL Server는 시스템 정보를 시스템 함수(예: user_name())보다는 저장 프로시저(예: sp_who)로 더 많이 패키지화합니다. SQL 2000 마스터 데이터베이스에서 프로시저와 함수를 놓고 보면, 우리가 생각해낼 수 있는 모든 시스템 정보를 SELECT, UPDATE, INSERT 또는 DELETE하는데 도움이 되는 저장 프로시저는 973개나 되는 반면 구성, 메타데이터, 보안, 시스템 및 시스템 통계 정보를 사용자가 선택(SELECT)은 할 수 있지만 변경은 할 수 없는 함수는 101개 뿐입니다.
시스템 정보를 단일한 SELECT 문으로 캡슐화할 수 있었으면 하고 바라는 경우가 종종 있을 것입니다. 예를 들면, "SELECT spid, login, BlkBy FROM sp_who2 WHERE spid > 50"을 사용하여 사용자 프로세스의 차단 정보만을 볼 수 있다면 좋을 것입니다. 아니면, 단일한 INSERT, UPDATE 또는 DELETE 문으로 데이터베이스 상태에 복잡한 변경을 실행할 수 있었으면 하고 바랄 때도 있을 것입니다. 하지만 안타깝게도 이러한 환상은 절대 실현되지 못할 것입니다. 최소한, SQL 또는 SQL에 포함된 함수 내에서 저장 프로시저를 호출할 수 있게 되기 전까지는 말합니다. SQL Server는 현재 함수 내에서 저장 프로시저를 호출하거나 테이블을 업데이트하는 것을 금지하고 있습니다. 이 제한때문에 우리는 시스템 정보를 사용하거나 단일 SQL 문에서 복잡한 변경을 실행할 수 없습니다. 본 자료는 함수와 프로시저에 걸린 “마법”을 깨뜨려 SQL 문에서 이 둘을 최대환 활용할 수 있도록 하기 위한 의도로 만들어진 시리즈 자료 중 첫 번째입니다.
집합 기반 쿼리
결과 집합처럼 보이는 출력을 반환하는 DBCC 명령 또는 저장 프로시저(sp’s)가 많으며, 이러한 출력이 다른 결과 집합과 직접 조인이 가능하다면 좋을 것입니다. 예를 들어, 이러한 결과 집합을 프로그래밍 방식으로 액세스하여 시스템 관리 작업을 자동화하거나 한 응용 프로그램을 위해 여러 소스에서 데이터를 통합할 수 있다면 좋을 것입니다. DBCC 또는 sp의 다수의 결과 집합을 하나의 SQL 문으로 조인할 수 없고 DBCC 또는 sp에 대해 커서를 선언할 수 없다면 유일한 옵션은 다수의 임시 테이블을 사용하는 것 뿐입니다. 게다가, 이 마지막 방법 역시 DBCC 또는 sp 결과 집합의 모든 열의 데이터 유형을 알고 있어서 임시 테이블을 만들어 DBCC 또는 sp 결과 집합을 그 임시 테이블에 넣을 수 있어야만 가능한 방법입니다. (SELECT INTO를 사용하여 DBCC 또는 sp 결과 집합에서 임시 테이블을 “몰래” 만들수는 없기 때문입니다.) DBCC 또는 sp의 결과 집합이 문서화(예: sp_who2)되지 않았으며 그 스냅샷 중 하나만을 기초로 임시 테이블을 만들면 이후 스냅샷이 더 긴 문자열이나 다른 데이터 형식을 반환할 경우 이 임시 테이블은 손상됩니다. 목록 1에는 먼저 그 필요성은 절실함에도 불구하고 지원은 되지 않는, 두 sp의 결과 집합을 조인하는 집합 기반 SQL 문을 제시하였습니다. 하지만 “최후의 수단”인, 임시 테이블에 의존하는 방법으로 눈길을 돌리지 않을 수 없었습니다.
목록 1. 집합 기반 쿼리와 프로시저 스크립트 비교
--set-based query:
--a much needed, but unsupported, SQL
select * from (Exec sp_who) w inner join
(Exec sp_lock) l on w.spid = l.spid
where w.spid > 50 and w.blk <> 0
--a batch of scripts:
--temporary tables must be created first before insert
create table #who(spid smallint,ecid smallint,status
nchar(30),loginame nchar(128),
hostname nchar(128),blk char(5), dbname nchar(128),
cmd nchar(16))
create table #lock(spid smallint,dbid smallint,
ObjId int,IndId smallint,Type nchar(4),
Resource nchar(16),Mode nvarchar(8),Status nvarchar(5))
insert #who
Exec sp_who
insert #lock
Exec sp_lock
select * from #who w inner join #lock l on w.spid = l.spid
where w.spid > 50 and w.blk <> 0
drop table #who
drop table #lock
여기서 보는 것처럼 SQL 문이 일련의 스크립트보다 훨씬 더 간단하고 효율적입니다. 하지만 시스템 상의 한계때문에 쿼리가 다른 쿼리의 중간 결과에 의지하고 순차적 단계로 나누어져야 할 수도 있습니다. 이러한 한계 중 하나가 SQL 문의 어디서도 DBCC 명령이나 저장 프로시저를 직접 호출할 수 없다는 것입니다. 다음 단락에서는 아주 일반적인 몇몇 시나리오를 살펴 보겠습니다.
사용 사례 1: 프로세스 저장 프로시저 및 DBCC 차단
이 사례는 Kalen Delaney의 저서 Inside Microsoft SQL Server 2000의 926페이지에서 발췌한 것입니다. 새 응용 프로그램이 연결되지 않거나 기존 응용 프로그램이 진행되지 않거나 또는 Enterprise Manager(EM)의 일부 또는 전체가 중단되면 시스템 비상 사태가 발생합니다. 응용 프로그램 “중단”은 대형 프로덕션 SQL Server의 경우에도 그리 드문 일이 아닙니다. 일반적으로 차단이 그 원인이므로 EM을 사용하여 차단/차단된 프로세스와 잠금/잠긴 개체를 찾을 수 있습니다. 하지만 EM이 중단되면 어떻게 해야 할까요? 아니면 차단 체인의 문제가 너무 복잡해서 비상 시 수동으로 신속하게 해결할 수 없는 경우에는 어떻게 해야 할까요? 다행스럽게도 응용 프로그램이 중단되었다고 해도 일반적으로 SQL Server 시스템이 중단된 것을 뜻하지는 않습니다. 따라서 여전히 Query Analyzer와 같은 다른 응용 프로그램에 연결할 수 있습니다. 게다가 SQL Server는 각각 sysprocesses와 syslockinfo 테이블에서 그 소스보다 훨씬 더 읽기 쉬운 형식으로 주요 프로세스와 잠금 정보를 추출하는 sp_who2와 sp_lock를 제공합니다. 심지어는 DBCC INPUTBUFFER(spid)를 사용하면 차단 프로세스가 실행한 마지막 SQL 일괄 처리도 찾아낼 수 있습니다. 여기에서 spid는 그 차단 프로세스의 ID입니다.
따라서 쿼리 분석기에서 대화형으로 SQL 문을 입력하고 차단 프로세스, 차단 응용 프로그램 호스트, 잠긴 개체, 그리고 마지막 SQL 일괄 처리의 세부 사항만 신속하게 검색할 수 있다면 그보다 더 좋은 일이 있겠습니까? 비상 시에 이 결과 집합은 어떤 프로세스에 통지를 하고 어떤 프로세스를 중단할 지에 대한 정확한 결정을 내리는데 큰 도움이 됩니다. 장기적인 관점에서 보면 이 결과 집합은 그 응용 프로그램의 잠금 동작을 새롭게 변형하는 데에도 도움이 됩니다. 다음은 그러한 이상적인 SQL 문입니다. sp_who2의 BlkBy 열에는 차단 프로세스의 spid가 기록된다는 점에 유의하십시오. 프로세스가 차단되지 않았으면 그 BlkBy 열 값은 spid 대신 " . "가 됩니다. 따라서 차단 체인의 근원은 BlkBy는 " . "이지만 spid가 최소한 하나 이상의 BlkBY에 표시되어 있는 프로세스입니다.
select blocking.*, l.*, i.*
from (exec sp_who2) blocking inner join
(Exec sp_lock) l
on l.spid = blocking.spid inner join
(DBCC INPUTBUFFER(all)) i
on l.spid = i.spid
where blocking.BlkBy like '%.%'
and blocking.spid in
(select CAST(blocked.BlkBy as int) from (exec sp_who2)
blocked where blocked.BlkBy not like '%.%')
사용 사례 2: 확장 저장 프로시저
확장 저장 프로시저(이하 xp’s)는 사용자 지정 기능에 “플러그인”하여 SQL Server를 “확장”하도록 SQL Server가 허용하는 몇몇 방법 중 하나입니다. 예를 들면, 전체적으로 또는 부분적으로 범람원에서 50피트 내에 있는 세금 구역의 결과 집합을 반환할 수 있는 xp_intersects라는 xp를 만들었습니다. 제가 xp_intersects를 보험 테이블, 허가증 테이블, 소유자 테이블 및/또는 시장 가치 테이블에 임의로 손쉽게 조인할 수 있다면 이러한 xp는 SQL Server를 위성 정보 시스템(GIS)과 같은 수직적 응용 프로그램의 영역으로 밀어넣는 좋은 예가 될 것입니다. 다음 SQL 문은 SQL Server를 확장하는 단순하면서도 우수한 방법입니다.
SELECT t.taxlot_id, i.*, v.*
From (Exec xp_intersects('polygon_100_year_flood',
'taxlots', 50)) t inner join insurance i on t.taxlot_id =
i.taxlot_id inner join market_value v on
t.taxlot_id = v.taxlot_id
사용 사례 3: XML 데이터 소스
XML은 빠르게 사실상의 데이터 교환 표준이 되었을 뿐만 아니라 직접적인 데이터 소스로도 유용합니다. 예를 들면, 공급 업체는 HTTP를 통해 XML 문자열로 구매 주문을 받을 수 있습니다. 이 XML 문자열은 제품 ID와 수량을 인코딩할 것입니다. 공급자의 응용 프로그램이 이 XML 문자열을 구입 제품이 들어 있는 테이블처럼 처리하여 그 공급자의 카탈로그 및 저장소 테이블과 조인시켜 제품 선적이 자동으로 처리되도록 하면 간편할 것입니다. SQL Server 2000의 새 행집합 공급자 OPENXML은 XML 문서를 통해 결과 집합을 반환할 수 있다는 것을 알고 있을 것입니다. 하지만 OPENXML을 사용할 경우 이 구매 주문 XML 문자열이 다른 테이블에 조인하려면 다음 세 단계를 거쳐야만 합니다.
-- parameter @XMLDoc varchar(8000) contains XML string
DECLARE @iDoc int
Exec sp_xml_preparedocument @iDoc OUTPUT, @XMLDoc
SELECT * FROM OpenXML(@iDoc, '/ROOT/Order',0) WITH
(ProductID int, Quantity int) o inner join catalog c
on o.ProductID = c.ProductID inner join warehouse w
on c.WarehouseID = w.WarehouseID
Exec sp_xml_removedocument @iDoc
sp_xml_preparedocument와 sp_xml_removedocument는 각각 메모리에서 XML 문자열의 구문을 검색하고 그 메모리를 다시 할당하는 xp's입니다.
XML 단계를 sp_OpenXML와 같은 프로시저로 그룹화하여 이러한 단계를 단일한 SQL 문으로 코드화할 수 있다면 좋지 않겠습니까?
-- parameter @XMLDoc varchar(8000)
SELECT *
FROM (Exec sp_OpenXML(@XMLDoc) o inner join catalog c
on o.ProductID = c.ProductID inner join warehouse w
on c.WarehouseID = w.WarehouseID)
집합 기반 접근법
집합 기반 프로세스의 기능을 완벽하게 활용하기 위해서는 지금까지 설명한 사용 사례에 맞는 솔루션을 만드는데 도움이 되는 방법이나 도구를 찾아야 합니다. 이 도구는 SQL 문에 사용될 수 있어야 하고 sp, xp, OPENXML 및 DBCC 명령에서 직접 결과 집합을 반환할 수 있어야 합니다. 본 자료의 나머지 부분에서는 가능성 있는 두 도구를 살펴보고 어떤 도구가 위의 두 가지 요구 사항을 모두 충족시키는지 알아 보겠습니다.
UDF는 언뜻 보면 논리적인 선택으로 여겨질 수 있습니다. 사실상 UDF는 SQL 문에 사용할 수 있는 유일한 사용자 확장입니다. 게다가 UDF는 테이블 변수나 스칼라 변수 중 하나를 반환할 수 있습니다. 예를 들어 세 번째 사용 사례를 충족시키려면 다음과 같은 실행을 하고 싶어질 것입니다.
--Function that encapsulates xp's and OPENXML
--creation of function udf_xml succeeds
Create function udf_xml(@XMLDoc varchar(8000))
Returns @t table(ProductID int, Quantity int)
as
begin
declare @iDoc int
Exec sp_xml_preparedocument @iDoc OUTPUT, @XMLDoc
INSERT @t
SELECT * FROM OPENXML(@idoc, '/ROOT/Order',0)
WITH (ProductID int, Quantity int)
Exec sp_xml_removedocument @iDoc
return
end
GO
--now join result set of udf_xml() in a SQL statement
--execution of function udf_xml fails
DECLARE @XMLDoc varchar(8000)
set @XMLDoc =
'<ROOT>
<Order ProductID="11" Quantity="12"/>
<Order ProductID="42" Quantity="10"/>
<Order ProductID="72" Quantity="3"/>
</ROOT>'
select * from udf_xml(@XMLDoc) o inner join catalog c
on o.ProductID = c.ProductID inner join warehouse w
on c.WarehouseID = w.WarehouseID
GO
-- Error message output
Server: Msg 557, Level 16, State 2,
Procedure udf_xml, Line 6
Only functions and extended stored procedures
can be executed from within a function.
udf_xml은 XML 결과 집합을 반환하는 세 단계를 성공적으로 캡슐화하지만(그리고 조인 SQL 문도 아주 간단하지만) udf_xml 실행은 실패합니다. 사실, 함수 자체만으로는 여기 제시된 어떤 사용 사례도 해결할 수 없습니다. 함수에는 다음과 같은 제약이 따르기 때문입니다.
- 함수는 저장 프로시저를 실행할 수 없습니다. 함수는 함수와 일부 xp's는 실행할 수 있지만 sp's는 실행할 수 없습니다. 이러한 한계 때문에 함수는 사용 사례 1과 3을 해결할 수 있는 후보에서 즉시 탈락됩니다.
- 함수는 임시 테이블 또는 다른 어떤 형태의 테이블도 만들 수 없습니다. xp 결과 집합을 반환하려면 함수는 그 결과 집합을 어딘가에는 저장할 수 있어야 합니다. 테이블이 가장 일반적인 선택 방법입니다. 하지만 안타깝게도 함수는 글로벌 데이터베이스 상태를 변경할 수 없습니다. 그 때문에 글로벌 데이터베이스 상태를 변경할 수 있는 임시 또는 영구 테이블을 만드는 것도 제한됩니다.
- 함수는 임시 테이블을 액세스할 수 없습니다. 글로벌 임시 테이블이 미리 만들어져 있다 하더라도 SQL Server는 여전히 함수에서 그 테이블이나 기존의 다른 임시 테이블로의 데이터 삽입을 허용하지 않습니다.
- 함수는 기존 테이블에 삽입을 할 수 없습니다. 함수 외부에 영구 테이블을 만들면 어떨까라는 생각도 할 수 있습니다. 하지만 함수에서 기존 영구 테이블로의 삽입 역시 글로벌 데이터베이스 상태를 변경하는 것으로 간주됩니다.
- 기존 DBCC, sp 또는 xp 실행 결과 집합을 테이블 변수에 삽입할 수 없습니다. 테이블 변수를 사용하여 결과 집합을 저장하는 방법은 어떨까요? 안타깝게도 EXECUTE를 사용하여 테이블 변수에 데이터를 삽입할 수 없습니다. 하지만 EXECUTE는 함수 내에서 DBCC, sp 및 xp가 포함되는 SQL 문자열을 발행할 수 있는 유일한 방법입니다. 이 마지막 한계에 다다르자 우리는 UDF는 위 사용 사례에 대한 해답이 아니라는 결론을 내리지 않을 수 없었습니다.
마지막 방법 OPENQUERY
제 조사에 따르면 OPENQUERY가 SQL 문에서 sp, xp 및 DBCC 결과 집합을 반환하는 유일한 방법으로 여겨집니다. 하지만 OPENQUERY 역시 완벽하지는 않습니다. 예를 들면, OPENQUERY를 사용하면 다음 예에서 볼 수 있는 것처럼 sp_who 결과 집합은 손쉽게 반환할 수 있지만 sp_who2 결과 집합은 반환할 수 없습니다.
--openquery returns the result set of sp_who just fine
select * from openquery(csherts, 'Exec sp_who')
go
(14 row(s) affected)
--openquery finds no result set from sp_who2
select * from openquery(csherts, 'Exec sp_who2')
go
Server: Msg 7357, Level 16, State 2, Line 1
Could not process object 'Exec sp_who2'.
The OLE DB provider 'SQLOLEDB' indicates that
the object has no columns.
OPENQUERY는 SELECT 문의 FROM 절에 들어갈 수 있으므로 첫 번째 요구 사항은 만족시킵니다. OPENQUERY를 사용하면 UDF는 sp나 xp, OPENXML 또는 DBCC를 간접적으로 호출할 수 있습니다. FROM 절 외에도 함수는 SQL의 어디서나 사용될 수 있습니다. 두 번째 요구 사항의 경우에는, OPENQUERY는 일부 sp’s에 대해서만 실행되며 xp's나 DBCC와는 실행되지 안습니다. 사실, OPENQUERY가 입력 SQL 문자열을 기초로 한 열 이름과 출력 결과 집합 유형을 알 수 없으면 이 쿼리는 실패하며 “이 개체에는 열이 없습니다”라고 응답합니다. OPENXML의 경우 OPENQUERY는 다음 코드 블록의 예에서 볼 수 있는 것처럼 처음에는 모든 것이 잘 진행된다는 느낌을 줄 수 있습니다. 하지만 두 번째 예를 자세히 살펴 보면 OPENQUERY는 OPENXML에는 현실적이지 않다는 것을 알 수 있습니다. 이는, XML 문자열은 사실상 변수로 구성되는 경우가 많은데 OPENQUERY는 변수를 인수로 사용하지 않기 때문입니다.
그럼에도 불구하고 OPENQUERY와 UDF 조합은 위 세 사용 사례를 모두 지원할 수 있는 가능성이 있습니다. 다시 말하면 OPENQUERY만이 sp’s와 함수에 걸린 마법을 깰 수 있는 유일한 도구입니다. 본 시리즈의 다음(두 번째) 자료에서는 OPENQUERY의 동작을 자세히 설명하고 그 한계를 간단하게 요약한 다음 그러한 한계를 극복하는 방법을 제시하겠습니다. 그리고 OPENQUERY를 사용하여 본 자료에서 설명한 사용 사례를 구현해 보겠습니다.
-- Example 1 OPENQUERY works for OPENXML only if XML
-- is a constant string
-- XML specified in the constant argument to OPENQUERY
select * from openquery(csherts,
'
declare @iDoc int
Exec sp_xml_preparedocument @iDoc OUTPUT, ''<ROOT>
<Order ProductID="11" Quantity="12"/>
<Order ProductID="42" Quantity="10"/>
<Order ProductID="72" Quantity="3"/>
</ROOT>''
SELECT * FROM OPENXML(@idoc, ''/ROOT/Order'',0)
WITH (ProductID int, Quantity int)
Exec sp_xml_removedocument @iDoc
')
go
-- Output
(3 row(s) affected)
--Example 2 XML concatenates with OPENXML steps in a
--variable argument to OPENQUERY. Illustrates that
--OPENQUERY does not accept variable arguments
DECLARE @XMLDoc varchar(8000)
set @XMLDoc =
'<ROOT>
<Order ProductID="11" Quantity="12"/>
<Order ProductID="42" Quantity="10"/>
<Order ProductID="72" Quantity="3"/>
</ROOT>'
set @XMLDoc = '
declare @iDoc int
Exec sp_xml_preparedocument @iDoc OUTPUT, ''' +
@XMLDoc + '''
SELECT * FROM OPENXML(@idoc, ''/ROOT/Order'',0)
WITH (ProductID int, Quantity int)
Exec sp_xml_removedocument @iDoc
'
select * from openquery(csherts,@XMLDoc)
go
-- Output
Server: Msg 170, Level 15, State 1, Line 15
Line 15: Incorrect syntax near '@XMLDoc'.
[지난 호의 관련 자료: Andrew Zanevsky의 "Granting Users' Wishes with UDFs" (2000년 9월), "Inline Table-Valued Functions" (2000년 10월), "Multi-Statement Table-Valued Functions" (2000년 11월), "UDF Performance… or Lack of It" (Anton Jiline 공저, 2001년 10월). Tom Moreau의 "Dynamic DTS Tasks and OPENROWSET" (2001년 1월), "How Do You Feed an Array to a Stored Procedure?" (2002년 4월). Scott Whigham의 "How to Write your Own System Functions" (2001년 12월).—편집자 주.]
QUERY1.SQL (영문) 다운로드
이 글은 스프링노트에서 작성되었습니다.
'Peformance Tuning' 카테고리의 다른 글
| RML ReadTrace 분석에 필요한 이벤트 (0) | 2010.08.24 |
|---|---|
| dm_os_performance_counters , Server/Process Information (0) | 2010.06.07 |
| 성능::ReadTrace 사용법 (0) | 2010.06.03 |
| SQL서버 성능카운터 (0) | 2010.06.03 |
사용법
- --===================================
-- READ TRACE
--===================================
ReadTrace -I파일경로 -S서버명 -dDB명 -U유저 -P패스워드
D:\Program Files\Microsoft Corporation\RML\ReadTrace.exe /?- ReadTrace version 9.00.0023 (X86)
- USAGE:
- NOTE: All command line arguments are case sensitive
- -I File name of the first .TRC file to process [REQUIRED]
- -i If specified, indicates that the .TRC file(s) to process are present inside a CAB/ZIP file with this file name
- -o Full path of directory to place output files [default is current directory]
- -S Name of SQL Server 2005 server to connect to when loading performance analysis data [default is (local)]
- -d Database to use when loading performance data [default is PerfAnalysis].
- User specified below must have CREATE DATABASE permission (if DB doesn't
- exist) or be part of the db_owner role if the database already exists.
- -E Connect to SQL using Windows Authentication [default]
- -U Connect to SQL using this user name
- -P Password for the user specified in -U option
- -a Disable performance analysis
- -f Do not produce .RML output files for each SPID
- -Q Do normalization parse using quoted_identifier OFF symantics. (Default is ON)
- -r# Read at most this # of files (including the first) [default is all files
- until a break in the rollover file sequence is detected].
- -M Mirror trace files by SPID to the specified output directory (All SPIDs
- will be output even if SPID filter is specified)
- -MF Mirror trace files by SPID to the specified output directory (Only SPIDs
- matching filter parameters will be output)
- -A 'INCLUDE or EXCLUDE' events with Applicaiton Names
- -H 'INCLUDE or EXCLUDE' events with Host Names
- -s# 'INCLUDE or EXCLUDE' events from specified SPIDs
- -b Provide a designated start time in required format 2000-05-25 11:46:20:060
- -e Provide a designated stop time in required format 2000-05-25 11:46:20:060
- -D Skip date on log file output
- -? Show usage of command line parameters
- EXAMPLES:
- ReadTrace -Iserver__sp_trace.trc -ic:\temp\traces.cab -oc:\temp\output -f
- ReadTrace -I"c:\my traces\80AllEvents.trc" -o"c:\my output"
- ReadTrace -Ioutput\SQLSRV1__sp_trace_20.trc -ic:\temp\pssdiag.zip -oc:\temp\breakout -f -r2
PSSDIAG 수집 유형
- http://support.microsoft.com/kb/830232
- http://msdn.microsoft.com/en-us/library/aa175399(SQL.80).aspx
이 글은 스프링노트에서 작성되었습니다.
'Peformance Tuning' 카테고리의 다른 글
| dm_os_performance_counters , Server/Process Information (0) | 2010.06.07 |
|---|---|
| 저장 프로시저 및 함수의 마법 깨트리기 #1 (0) | 2010.06.04 |
| SQL서버 성능카운터 (0) | 2010.06.03 |
| 성능::엑셀이용분석하기 (0) | 2010.06.03 |
SQL서버 성능카운터 활용을 위한 팁
원문링크 : http://www.sql-server-performance.com/performance_monitor_counters_sql_server.asp
번역 : 김종균 (jkkim@techdata.co.kr)
SQL서버에서 과도한 I/O의 원인 중 하나는 페이지 분할 입니다. 페이지 split은 인덱스나 데이터 페이지가 꽉 찰 경우에 발생하며, 현재 페이지와 새로이 할당되는 페이지 사이에서 분할이 이루어 집니다. 가끔 발생하는 페이지 분할은 정상입니다만, 과도한 페이지 분할은 과도한 디스크 I/O를 유발하게 되며, 이는 느린 성능을 야기합니다.
SQL서버가 과도한 페이지 분할을 일으키고 있는지를 찾기 원한다면 성능카운터에서 SQL Server Access Methods 개체의 Page Splits/Sec 항목을 모니터 하십시오. 만일 과도한 페이지 분할이 발생하고 있다면, 인덱스의 채우기 비율을 높게 설정하시는걸 고려하십시오. 채우기 비율을 높게 설정하시면 데이터가 가득 차거나, 페이지 분할이 발생하기 전에 데이터 페이지에 보다 더 많은 여유 공간이 있으므로, 페이지 분할을 감소시킬 수 있습니다
높은 Page Splits/sec 은 무얼 의미하는가? 이것은 운영하는 시스템의 I/O하부 시스템에 따라 다르므로 이에 대한 간단이 답을 할 수 없습니다. 그러나 만일 당신이 평상시에 디스크 I/O의 성능 문제가 발생하고, 이 카운터 값이 100을 초과한다면, 채우기 비율을 높여서 성능이 호전 되는지 그렇지 않은지 실험해 보는 것도 좋을 것 입니다.
*****
물리적인 메모리를 SQL서버 Data캐시에 얼마나 할당되었는지 알고 싶다면, SQL Server Buffer Manager Object: Cache Size (pages) 항목을 모니터링 하십시오. 이 수치는 페이지 수로 표시되므로, 이 값에 8K(8192 bytes)를 곱하면, Data캐시로 사용되고 있는 총 메모리의 사용량을 알 수 있습니다.
일반적으로, 이 수치는 서버의 총 메모리 량에 근접해야 합니다. SQL서버로 운영하는 시스템에서 OS커널이나, SQL서버 그리고 기타 유틸리티 프로그램이 사용하는 메모리 량을 최소화 하십시오.
만일 Data캐시 용도로 할당된 메모리 양이 여러분이 생각하는 것 보다 훨씬 작다면, 왜 그런지 원인을 찾으셔야 합니다. 아마도, SQL서버가 메모리를 동적으로 할당하도록 설정하지 않고, 대신에 뜻하지 않게 SQL서버가 적은 메모리를 사용하게 구성 하셨을 겁니다. SQL서버가 가용할 수 있는 Data캐시의 총량은 SQL서버 성능에 아주 큰 영향을 미치기 때문에 원인이 무엇이든 간에 여러분은 해결방안을 찾아야 합니다.
실제로는, SQL서버가 메모리가 부족한지 아닌지를 알기 위해 보다 많은 카운터들이 존재하고, 더 효율적이기 때문에 저는 이러한 카운터(SQL Server Buffer Manager Object: Cache Size (pages))를 모니터 하는데 많은 시간을 사용하지 않습니다. (그래서 어쩌라고. ㅜㅜ)
*****
SQL서버가 얼마나 바쁜지 알기 위해서, SQLServer: SQL Statistics: Batch Requests/Sec 카운터를 모니터 하십시오. 이 카운터는 초당 SQL서버가 받는 배치 요청 수를 측정하고, 일반적으로 서버의 CPU들이 얼마나 바쁜지 나타냅니다. 말하자면, 초당 1000배치가 넘어서면, SQL서버가 매우 바쁘다는 것을 나타내며, CPU병목 현상이 아직 나타나지 않고 있다면, 조만간 CPU병목 현상이 나타날 것임을 알 수 있습니다. 물론 이 수치는 상대적인 것이며, 여러분의 하드웨어가 고 사양이라면, 보다 더 많은 초당 배치요청 수를 커버할 수 있을 것입니다.
네트워크 병목의 관점에서 보자면, 100Mbps 네트워크 카드는 초당 3000 배치 요청을 처리 할 수 있습니다. 만일 네트워크 병목이 심한 서버를 운영하고 계시다면, 네트워크 카드를 2개이상 늘리거나, 1Gbps 네트워크 카드로 교체 할 필요가 있을 것입니다.
몇몇 DBA들은 전체 SQL서버활동량을 측정하기 위해서 SQLServer: Databases: Transaction/Sec: _Total 카운터를 모니터 하는데, 이는 좋은 방법이 아닙니다. Transaction/Sec 카운터는 전체 활동량이 아닌 한 트랜잭션의 내부활동을 측정하며, 왜곡된 값을 나타냅니다. 대신에, SQL서버의 전체 활동량을 측정하는 SQLServer: SQL Statistics: Batch Requests/Sec 카운터를 사용하시기 바랍니다
*****
TSQL코드의 컴파일은 SQL서버의 일반적인 동작입니다. 그러나, 이 컴파일이 CPU와 다른 리소스들을 많이 잡아 먹기 때문에, SQL서버는 가능한 많은 실행계획을 캐시에 저장해서 실행계획이 컴파일 되지 않고 재사용되도록 시도합니다(실행계획은 컴파일이 발생할 때 생성됩니다). 보다 더 많은 실행계획이 재 사용 되어지면, 서버에 대한 부담은 더 적어지게 되며, 전체적인 성능은 더욱 더 향상 됩니다.
SQL서버가 얼마나 많은 컴파일을 하고 있는지 확인 하려면, SQLServer: SQL Statistics: SQL Compilations/Sec 카운터를 모니터 하십시오. 여러분이 기대하시는 것처럼, 이 카운터는 초당 얼마나 많은 컴파일이 SQL서버에 의해서 실행되었는지를 측정합니다.
말하자면, 이 카운터의 수치가 초당 100을 넘어서면, 불필요한 컴파일 오버헤드를 경험하고 계신 것 입니다. 이러한 높은 수치는 여러분의 서버가 매우 바쁨을 나타내거나, 불필요한 컴파일들이 실행되고 있다고 볼 수 있겠습니다. 예를 들어, 오브젝트의 스키마가 변경되거나, 병렬로 실행계획이 잡혀있던 것이 직렬로 실행되어야 하거나, 통계가 다시 계산되었다거나 하는 등의 이유로 SQL서버로부터 재 컴파일 하라는 지시를 받았을 수도 있습니다. 어떤 경우에는, 불필요한 컴파일을 줄이기 위해서 여러분의 노력이 필요할 수 도 있습니다. (역주. 잘 아시듯이, adhoc 쿼리를 저장프로시져로 만들면 컴파일 이슈가 없어지죠)
만약, 여러분의 서버가 초당 100회 이상의 컴파일을 수행한다면, 이 원인이 여러분이 조절할 수 있는 것인지 아닌지 찾기 위해 애 쓰셔야 합니다. 너무 많은 컴파일은 SQL서버의 성능에 악영향을 끼칩니다.
*****
SQLServer: Databases: Log Flushes/sec 카운터는 초당 플러쉬 된 로그 수를 나타냅니다. 이 카운터는 데이터베이스 별로 측정되거나, 단일 SQL서버의 전체 데이터베이스에 대한 값으로 측정 될 수 있습니다.
로그 플러쉬란 무엇일까요? 이해를 쉽게 하기 위해서 예를 들어 설명 하는 게 좋을 것 같습니다. 10개의 INSERT명령이 있는 트랜잭션을 시작한다고 가정하겠습니다. 트랜잭션이 시작되고, 그리고, 첫 번째 INSERT가 실행되고, 새 데이터가 데이터 페이지로 삽입 되어질 때, 필수적으로 동시에 두 가지의 일이 발생합니다. 버퍼캐시의 데이터페이지는 새로이 삽입된 데이터로 변경됩니다, 그리고 이 단일 INSERT명령에 대한 적당한 로그용 데이터가 로그캐시에 쓰여집니다. 이 과정은 트랜잭션이 완료 될 때까지 계속 됩니다. 이때, 로그캐시에 기록된 트랜잭션을 위한 로그 데이터는 즉시 로그파일에 기록됩니다, 그러나 버퍼캐시에 있는 데이터는 다음 체크포인트 프로세스가 실행되기 전까지 버퍼캐시에 머무르게 됩니다. 그리고, 그때 데이터베이스는 새로이 삽입된 행으로 업데이트 됩니다.
여러분은 로그캐시에 대해서 한번도 들어보지 못했을지도 모릅니다. 이것은 SQL서버가 로그파일에 쓰여질 데이터를 기록하는 메모리의 한 영역입니다. 로그캐시의 목적은 트랜잭션이 커밋 되기 전에 특정상황이 발생하여 롤백 해야 하는 상황에서 트랜잭션을 롤백 하는 용도로 사용되기 때문에 매우 중요합니다. 그러나, 트랜잭션이 완료되면 (완료되면 절대 롤백 되지 않음), 로그 캐시는 즉시 물리적인 로그파일로 플러시 됩니다. 이것이 정상적인 절차입니다. SELECT쿼리는 데이터를 수정하지도 않고 트랜잭션을 생성하지도 않고, 로그 플러시를 발생하게 하지도 않음을 명심 하십시오.
본질적으로, 로그캐시에 있는 데이터가 물리적인 로그파일로 쓰여질 때 하나의 로그 플러시가 발생합니다. 따라서, 하나의 트랜잭션이 완료될 때마다, 로그 플러시는 발생하며, 많은 수의 로그 플러시 발생은 SQL서버로부터 수행되는 많은 수의 트랜잭션과 관련이 있습니다. 그리고, 짐작하시는 것처럼 로그 플러시(얼마나 많은 데이터가 로크 캐시로부터 디스크에 기록 되어졌는가) 의 크기는 트랜잭션에 따라 다릅니다. 이 내용이 도움이 되었나요?
우리가 디스크 I/O 병목현상을 격 고 있고, 그 원인을 확신하지 못하고 있다고 가정합시다. 디스크 I/O에 대한 병목을 해결하기 위한 하나의 방법은 Log Flushes/sec 카운터 데이터를 수집하고, 이 과정을 처리하는데 얼마나 바쁜지 보는 것입니다. 여러분의 서버에 많은 트랜잭션이 발생하고 있다며, 로그 플러시 양은 당연히 많을 것입니다, 따라서 이 카운터 항목으로 보는 값은 트랜잭션을 발생하는 활동 형 쿼리가 얼마나 바쁜가에 따라 서버마다 다양할 것입니다. 이 카운터 정보로써 여러분은 초당 발생하는 로그 플러시 수가 운영하는 서버에서 예상되는 트랜잭션의 수 보다 확연하게 높은가에 대한 상황 판단에 도움을 줄 것이다.
예를 들어, 매일 1,000,000행을 한 테이블로 삽입하는 작업을 한다고 가정합시다. 이 행들이 삽입되어질 수 있는 방법은 다양합니다. 첫째, 각 행은 따로따로 삽입되어 질 수 있습니다. 각 INSERT는 단일 트랜잭션 내부에 감싸집니다. 둘째, 모든 INSERTS는 단일 트랜잭션 내에서 수행되어 질 수 있습니다. 마지막으로, INSERTs는 1과 1,000,000사이의 어딘가에 여러 개의 트랜잭션으로 나누어 질 수 있습니다. 각 형태의 처리는 다르며, SQL서버와 초당 플러시 되는 로그 수에 매우 다른 영향을 미칩니다. 더구나, 프로세스가 멀티 트랜잭션으로 처리되고 있는데, 단일 트랜잭션으로 처리되고 있다고 착각할 수 도 있다. 많은 사람들이 단일 프로세스를 단일 트랜잭션으로 생각하고 있는 경향이 있습니다.
첫째의 경우에서, 만일 1,000,000행이 1,000,000개의 트랜잭션으로 삽입되어진다면, 1,000,000번의 로그 플러시가 발생할 것입니다. 그러나, 두 번째 경우에는, 단일 트랜잭션에서 1,000,000행이 삽입되어 질 것이고, 단지 하나의 로그 플러시가 발생할 것입니다. 그리고, 세 번째 경우 에는 플러시 되는 로그의 수는 트랜잭션의 수와 같을 것입니다. 명백히, 로그 플러시의 크기는 1,000,000트랜잭션이 1트랜잭션보다 훨씬 클 것입니다, 그러나, 대개의 경우 성능의 관점에서 여기서 언급한 내용은 그다지 중요하지 않습니다.
어떤 옵션이 가장 좋은가요? 모든 경우에서, 많은 디스크 I/O를 유발할 것입니다. 1,000,000행을 핸들링 할 경우에는 I/O양을 줄일 묘안이 없습니다. 그러나, 하나 혹은 적은 수의 트랜잭션을 사용함으로써 로그 플러시 양을 많이 줄일 수 있을 것이고, 이는 디스크 I/O양을 줄이게 되어, I/O병목 감소와 성능을 높여줄 것입니다.
우리는 두 가지 포인트를 배웠습니다. 첫째는, 여러분이 플러시 되는 로그 양을 가능한 많이 줄이길 원할 것이라는 것과, 둘째, 여러분의 서버에서 발생하는 트랜잭션의 수를 줄이는 것입니다.
*****
SQL서버를 사용하는 많은 수의 사용자는 성능에 영향을 미치기 때문에, 여러분은 SQL Server General Statistics Object: User Connections 카운터에 관심을 가질것입니다. 이 카운터는 사용자 수가 아닌, SQL서버에 현재 연결된 사용자 연결 수를 나타냅니다
이 수치를 해석할 때, 하나의 단일 사용자는 여러 개의 연결들로 열릴 수 있음을 유념하십시오. 그리고 또한, 여러 명의 사람이 하나의 단일 사용자 연결을 공유할 수 도 있습니다. 이 수가 실제 사용자수를 나타낸다고 가정하지 마십시오. 대신에, 서버가 얼마나 바쁜가에 대한 상대적 척도로 사용하십시오. 여러 시간에 걸쳐서 이 수치를 모니터 해보시면, 서버가 많이 사용되고 있는지, 적게 사용되고 있는지 느낄 수 있을 것 입니다.
*****
만약 여러분들의 데이터베이스들이 데드락 문제로 괴로워하고 있다면, SQL Server Locks Object: Number of Deadlocks/sec 카운터를 통해서 추적할 수 있습니다. 그러나, 이 값이 상대적으로 높지 않다면, 이 값은 초단위로 측정되기 때문에 여러분은 더 많이 보기 원할 것입니다. 그리고, 눈에 띄게 보여지기 위해서는 다량의 데드락이 있어야 합니다. (ㅜㅜ)
그러나, 여전히 이 카운터는 여러분이 데드락 문제를 가지고 있는지 확인하기 위해서 가치있는 항목입니다. 차라리, 데드락을 추적하기 위해서 프로필러를 이용하십시오. 이는 보다 상세한 정보를 제공할 것입니다. 데드락 문제를 발견하기 위해서 Number of Deadlocks/sec 카운터를 활용하시고, 좀 더 세부적인 분석을 위해서 프로필러를 사용하십시오.
*****
만약에, 사용자들이 트랜잭션의 완료를 위한 대기시간 때문에 불만을 나타낸다면, 여러분은 개체 잠금이 이 문제가 되고 있는지 찾고 싶을 것 입니다. 문제점을 찾기 위해서, SQL Server Locks Object: Average Wait Time (ms) 카운터를 사용하십시오. 이 카운터는 database, extent, key, paLock Timeouts/secge, RID, table의 다양한 잠금에 대한 평균 대기 시간 정보를 측정합니다.
DBA로써, 여러분은 평균 대기 시간이 얼마 정도까지 허용될 수 있는지 결정해야 합니다. 한가지 방법으로써, 개별 잠금 종류에 대해서 장시간 동안 이 카운터 항목을 모니터 하시고, 각 잠금 별 평균을 파악하시는 겁니다. 그리고 그 평균값을 참고 자료로 활용 하시는 거죠. 예를 들어, RID의 평균 잠금 대기시간이 500ms 라면, 500보다 큰 대기시간을 가지는 개체들은 , 잠재적인 문제점을 가지고 있다고 판단할 수 있을 것입니다. 특히 500보다 훨씬 크거나, 장시간 동안 연장되는 개체들은 더 쉽게 판단할 수 있습니다.
여러분이 트랜잭션 지연에 의한 단일 혹은 다양한 종류의 잠금을 확인 할 수 있다면, 어떤 트랜잭션들이 잠금의 원인이 되었는지 확인할 수 있는지 알기 위해서 조사하길 원할 것 입니다.
*****
그런데 가끔 인덱스 탐색보다 테이블 스캔이 빠른 경우에, 일반적으로 적은 테이블 스캔이 보다 많은 테이블 스캔 보다 좋다. 여러분의 서버에서 얼마나 많은 테이블 스캔이 발생하는지 알아보기 위해서, SQL Server Access Methods Object: Full Scans/sec 카운터를 사용하십시오.이 카운터는 단일 데이터베이스가 아닌 전체 서버에 대한 값이라는 사실을 염두에 두셔야 합니다. 이 카운터 값으로 알게 될 사실 하나는 가끔씩 예측이 가능한 스캔 형태를 나타낸다는 것 입니다. 대부분의 경우에 이 값들은 SQL서버가 내부적으로 사용하는 것 들입니다.
여러분의 응용프로그램에서 나타나는 불규칙적인 테이블 스캔들을 파악하길 원하실 것입니다. 과도한 테이블 스캔이 발생될지를 고려하기 위해서 프로필러 데이터를 수집하고 인덱스 튜닝 마법사를 통해서, 어떤 것이 원인이 되는지 결정 할 수 있게 도움을 받을 수 있습니다. 그리고 몇몇 인덱스를 추가함으로써 테이블 스캔을 줄일 수 있을 것 입니다. 물론 SQL서버는 이 작업을 훌륭하게 수행할 것이고, 더 효율적이라면, 인덱스를 사용하는 것 대신에 테이블 스캔을 수행 할 것입니다. 그러나 내부적으로 어떤 일이 발생하는지 찾아 보지 않는 한 여러분은 알지 못 할 것입니다.
*****
만일 백업 및 복원 명령이 최적이 아닌 속도로 수행된다면, SQL Server Backup Device Object: Device Throughput Bytes/sec 카운터를 이용해서, 이 문제를 확인 할 수 있습니다. 이 카운터는 여러분의 백업이 얼마나 빨리 수행되는지 알려 줄 것입니다. 또한 문제에 대한 의구심을 해결하기 위해서 Physical Disk Object: Avg. Disk Queue Length 카운터를 같이 조사해 볼 수 도 있습니다. 대부분의 경우에 백업과 복원의 성능 문제가 있다면, I/O 병목에 의한 것들입니다.
DBA로써 경험하고 다루게 되는 I/O병목에 대한 판단의 작업 또한 수행할 것입니다. 예를 들면, 느린 백업 또는 복원의 원인이 같은 시점에 수행되는 단순한 DTS작업 때문일 수 있으며, 작업에 대한 일정의 재조정으로 문제를 해결 할 수 있습니다.
*****
여러분이 트랜잭션 복제를 사용하고 계신다면, 로그 리더가 트랜잭션들을 데이터베이스의 트랜잭션 로그로부터 배포 데이터베이스로 옮겨질 때까지의 지연시간을 모니터하길 원하실 것입니다.
또한 배포 에이젼트가 트랜잭션들을 배포데이터베이스에서 구독자 데이터베이스로 옮기는데 소요되는 시간을 모니터 하길 원할 것입니다. 이 두 지연시간의 합은 하나의 트랜잭션이 게시 데이터베이스에서 구독 데이터베이스로 전달되는 총 소요시간입니다.
이 두 카운터는 SQL Server Replication LogReader: Delivery Latency 와 SQL Server Replication Dist.: Delivery Latency 입니다.
만약, 둘 중의 하나의 과정중에 과도한 지연시간 증가를 발견한다면, 이것은 어떤 새로운 변화가 발생하여 지연 시간을 증가 시켰는지 살펴봐야 한다는 신호입니다.
*****
관찰하여야 할 주요한 카운터는 SQL Server Buffer Manager Object: Buffer Cache Hit Ratio 입니다. 이것은 SQL서버가 데이터를 액세스 하기 위해 하드디스크가 아닌 버퍼를 얼마나 자주 참조하는가를 나타냅니다. 보다 높은 이 수치는, SQL서버가 데이터를 가져오기 위해서 하드디스크에 아주 가끔 액세스한다는 것이며, 이는 SQL서버의 성능을 극대화 시킵니다.
SQL서버를 모니터하는 다른 카운터들과는 달리, 이 카운터는 SQL서버가 다시 시작한 시점 이후부터의 버퍼 캐시 히트율의 평균 값입니다. 다른 말로, 이 카운터는 현재 시점의 측정 값이 아니라 SQL서버가 시작된 이후의 모든 날들의 평균값입니다. 현재 시점의 버퍼캐시에서 어떤일이 발생하고 있는지 정확한 자료를 얻기 원한다면, 여러분은 SQL서버를 중지 했다가 다시 시작해야만 하고, 정확한 버퍼 캐시 히트율을 확인하기 위해 SQL서버를 여러 시간 동안 일반적인 활동을 하게 내버려 둬야 합니다.
만약 최근에 SQL서버를 재 시작 하지 않았다면, 여러분이 보고 있는 버퍼 캐시 히트율은 아마도 현재 발생하는 버퍼 캐시 히트율을 위해서는 정확한 정보가 아닐 것 입니다. 또한 버퍼 캐시 히트율이 좋아 보일지라도, 오랜 시간의 평균값으로 계산되었기 때문에 실제로는 좋지 않을 지도 모릅니다.
OLTP 응용프로그램 환경에서, 이 수치는 90~95% 이상이어야 합니다. 그렇지 않다면, 여러분은 성능 향상을 위해서 서버에 RAM을 추가할 필요가 있습니다.
OLAP 응용프로그램 환경에서는, OLAP작동하는 기본특성 때문에 이 수치는 OLTP 보다 더 작을 수 있습니다. 어떤 경우라도, 더 많은 RAM은 SQL서버의 OLAP 활동의 성능을 증가 시킬것입니다.
*****
이 두 카운터를 관측하는걸 고려하십시요. SQLServer:Memory Manager: Total Server Memory (KB) and SQLServer:Memory Manager: Target Server Memory (KB). 첫번째 카운터 SQLServer:Memory Manager: Total Server Memory (KB) 는 mssqlserver서비스가 메모리를 얼마나 사용하고 있는가를 말해줍니다. 이것은 SQL서버 Bpool영역으로 커밋된 전체 버퍼수를 포함하고, ‘OS in Use’ 로 표시되는 OS버퍼들도 포함합니다.
두번째 카운터, SQLServer:Memory Manager: Target Server Memory (KB)는 SQL서버가 얼마나 많은 메모리를 가용할 수 있는가를 나타냅니다. 이는 SQL서버가 시작시에 예약한 버퍼수에 기초합니다.
만약, Total Server Memory (KB)이 Target Server Memory (KB)보다 작다면, 이는 SQL서버가 충분한 메모리를 가졌고, 효율적으로 사용하고 있다는 것을 의미합니다. 반면에 Total Server Memory (KB)이 Target Server Memory (KB)보다 크거나 같다면, 이는 SQL서버가 메모리 압박을 받고 있고, 더 많은 물리적 메모리에 액세스 하고 있음을 나타냅니다.
*****
디스크로부터 데이터를 읽는 대신에 버퍼 캐시로부터 데이터를 가져온다면 SQL서버는 보다 적은 자원으로 보다 훨씬 더 빠르게 수행합니다. 몇몇 경우에, 메모리 집중적인 명령들로 인해 데이터 페이지들이 이상적으로 플러시 되기 전에 캐시 밖으로 밀려 나가기도 한다. 이는 버퍼 캐시가 충분히 크지 않거나 메모리 집중적인 명령의 작업을 위한 더 많은 버퍼 공간 요구에 의해 발생할 수 있습니다. 이런 경우에는 버퍼에 추가 적인 공간을 만들기 위해서 플러시 된 데이터 페이지들은 디스크로부터 읽혀지게 되며, 성능에 안 좋은 영향을 미치게 됩니다.
여러분들의 SQL서버가 이러한 문제를 가지고 있는지 확인 하기 위한 3개의 SQL 서버 카운터가 있습니다.
· SQL Server Buffer Mgr: Page Life Expectancy : 이 성능 카운터는 데이터 페이지가 얼마나 오랫동안 버퍼공간에 머무르는지를 평균적으로 나타내 줍니다. 만약 이 값이 300초 보다 작은 값을 보인다면, 여러분의 SQL서버는 성능의 극대화를 위해서 추가적인 메모리가 필요함을 잠재적으로 나타내는 것입니다.
· SQL Server Buffer Mgr: Lazy Writes/Sec : 이 카운터는 버퍼 공간을 비우기 위해서 지연기록기 프로세스가 더티 페이지들을 버퍼공간에서 디스크로 초당 얼마나 많이 옮겼는지 나타냅니다. 일반적으로 말하자면, 이 항목은 높은 값(초당 20정도)이어서는 안됩니다. 이상적으로, 0에 가까워야 합니다. 만약 이 값이 0이라면, 여러분의 SQL서버는 아주 큰 버퍼 공간을 가지고 있고, 일정한 체크 포인트가 발생하여 더티페이지가 반환되기를 기다리는 대신에, 더티페이지 반환을 하지 않아도 됨을 나타냅니다. 만약 이 값이 높다면, 보다 더 많은 메모리가 필요함을 나타냅니다.
· SQL Server Buffer Mgr: Checkpoint Pages/Sec: 체크포인트가 발생할 때, 모든 더티 페이지들은 디스크에 쓰여 집니다. 이것은 일반적인 절차이며, 체크포인트가 처리되는 동안에 이 카운터가 발생하는 근원이 됩니다. 시간에 걸쳐서 이 카운터의 높은 값을 보길 원치 않으실 것입니다. 이는 SQL서버의 귀중한 자원을 많이 사용할 수 있는 체크포인트 프로세스가 보다 더 자주 실행됨을 나타냅니다. 만약 이 값이 높은 값을 가진다면, 빈번한 체크 포인트 발생을 줄이기 위해서 더 많은 RAM을 추가할 것을 고려하시거나, SQL서버의 구성옵션 중에 ‘복구 간격(recovery interval)’ 옵션 값을 늘려주십시오.
이러한 성능 모니터 카운터들은 “메모리 부족”의 잠재적인 진단을 위해서 고려되거나, 고도화하거나, 정제하기 위해 사용되어야 합니다.
*****
래치는 본질적으로 “경량 잠금” 입니다. 기술적인 관점에서, 래치는 가볍고, 짧은 동기화 개체입니다. 래치는 마치 잠금 처럼 동작하고, 예상치 않은 변화로부터 데이터를 보호하기 위한 목적을 가지고 있습니다. 예를 들면, 하나의 행이 버퍼로부터 SQL서버의 저장소 엔진으로 이동될 때, 이 매우 짧은 시간 동안의 이동 중에 행 내부의 데이터 변형을 방지하기 위해서 SQL서버에 의해서 래치가 사용되어 집니다.
마치 잠금과 같이, 래치는 데이터베이스의 행들에 대해 접근하지 못하게 SQL서버를 방해 할 수 있고, 이는 성능에 안 좋은 영향을 줍니다. 이러한 이유 때문에 여러분은 래치 시간을 최소화하길 원하실 것입니다.
SQL서버는 래치의 활동을 측정하기 위한 3가지 다른 방법을 제공합니다.
· Average Latch Wait Time (ms): 래치 요청들을 위해 대기해야 하는 시간입니다. 이는 오직 대기해야 하는 래치 요청들에 대한 측정값입니다. 대부분의 경우에 대기가 없습니다. 따라서, 이 값은 모든 래치에 대한 것이 아니라, 대기 해야 하는 래치에 대해서만 적용된 값임을 유념하십시오.
· Latch Waits/sec: 이 값은 즉시 승인 받지 못한 래치 요청수입니다. 다시 말해서, 1초 동안에 대기 해야 했던 총 래치의 수입니다. 따라서, 이는 Average Latch Wait Time으로 부터 측정된 래치들 입니다.
· Total Latch Wait Time (ms): 이는 지난 초 동안의 총 래치 대기 시간 (ms) 입니다.
이 값을 읽을 때, 성능카운터에서 배율을 정확히 읽었는지 확인하십시오. 배율은 카운터 값마다 다르게 표시될 수 있습니다.
제 경험에 비추어 볼 때, Average Latch Wait Rime 카운터는 거의 변함이 없습니다. 반면에 다른 두 개의 카운터(Latch Waits/sec , Total Latch Wait Time (ms)) 는 SQL서버가 뭘 하느냐에 따라서 큰 변동폭을 보일 수 있습니다.
각각의 서버가 약간씩 다르기 때문에, 래치 활동도 각 서버마다 다릅니다. 전형적인 작업부하가 있을 때, 이 카운터에 대한 기준 값을 확보해 두시는 것은 아주 좋은 생각입니다. 이는 현재 어떤 일이 발생하고 있는가에 대해서 래치 활동이 평상시 보다 많은지 적은지에 대한 비교자료가 될 것입니다.
래치 활동이 기대치 보다 높다면, 이는 종종 하나 혹은 두 개의 잠재적인 문제점들을 나타냅니다. 첫째, 여러분의 SQL서버가 보다 많은 메모리를 사용할 수 있음을 의미할지도 모릅니다. 래치 활동이 높다면, 버퍼 캐시 히트 비율이 어떤지 확인하십시오. 이 값이 99% 이하라면, 보다 더 많은 양의 메모리가 서버의 성능에 도움을 줄 것입니다. 만약 99% 이상이라면, 문제를 유발하는 것은 IO시스템일수도 있습니다. 빠른 IO시스템은 서버 성능에 유리합니다.
래치에 대해서 보다 더 많이 배우고, 실험해보고 싶으시면, 여기 두 개의 명령이 있습니다.
SELECT * FROM SYSPROCESSES WHERE waittime>0 and spid>50
이 쿼리는 현재 대기상태에 있는 waittype, waittime, lastwaittype, waitresource, SPID들을 표시해 줍니다. lastwaittype은 래치 종류를, waitresource는 SPID가 어떤 개체를 위해 대기 중인지를 알려줍니다. 이 쿼리를 실행하게 되면, 실행 시점에 대기가 발생하고 있지 않다면, 아무런 결과도 얻지 못 할 지도 모릅니다. 그러나 계속해서 실행하다 보면, 결국 몇몇 결과를 얻게 될 것입니다.
DBCC SQLPerf (waitstats, clear) --대기 통계초기화
DBCC SQLPerf (waitstats) -- SQL서버 재시작(대기 통계 초기화) 이후의 대기 통계정보
이 쿼리는 대기유형, 대기시간과 함께 현재의 래치들을 나타내줍니다. 여러분은 아마도 통계정보를 초기화하길 원할 겁니다. 그런 다음에는 어떤 래치가 가장 많은 시간을 차지하는지 알기 위하여, DBCC SQLPerf(waitstats)명령을 짧은 시간에 걸쳐서 정기적으로 실행하십시오.
이 글은 스프링노트에서 작성되었습니다.
'Peformance Tuning' 카테고리의 다른 글
| 저장 프로시저 및 함수의 마법 깨트리기 #1 (0) | 2010.06.04 |
|---|---|
| 성능::ReadTrace 사용법 (0) | 2010.06.03 |
| 성능::엑셀이용분석하기 (0) | 2010.06.03 |
| read-ahead는 무었인가? (0) | 2009.12.03 |
Problem
In a previous tip, "Setting up Performance Monitor to always collect performance statistics" I wrote about how to collect performance monitor data, but once you have the data then what do you do with it. In this tip I will show you how I use Excel to analyze the data to help determine where your bottlenecks may be and also an easy way to create quick reports and charts for your SQL Servers.
Solution
Before we get started here are a couple of things you will need for this tip.
- Microsoft Excel 2007 - you also can use Excel 2003 or earlier version but for this tip, I used the latest version.
- Perfmon trace files at least one day in "csv" format. - if you have a file in "blg" format, you can easily convert it by using the "relog" tool. When I get a chance, I will write another tip about the relog tool and other tools that work well with Perfmon. To collect data using Perfmon you can review this tip Setting up Performance Monitor to always collect performance statistics.
Step 1: Open the csv file
Once you have collected the performance data you can open the csv file using Excel and you should see data similar to the following.
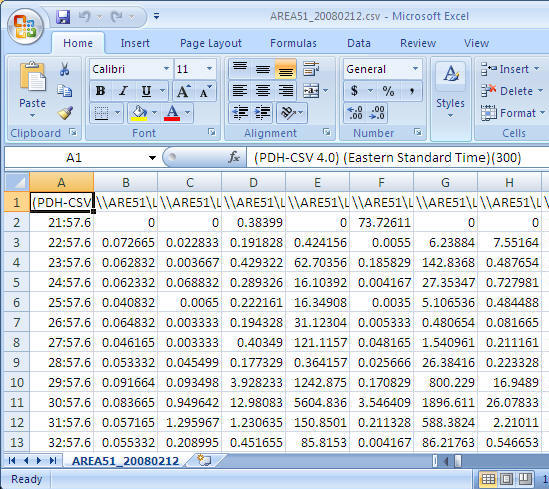
Step 2: Adjust the format
To allow easy reporting of the data there are a few things that I do to adjust the data.
- Replace server name with an empty string - it helps to make reading the counter names easier. In this case I am replacing "\\AREA51\" the name of my server to nothing. (This is optional, but recommended)
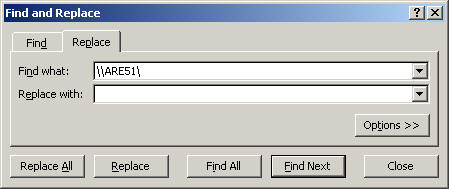
- Cell - A1: Replace "(PDH-CSV 4.0) (Eastern Standard Time)(300)" with "Time" (Optional, but recommended)
- Delete the second row - very often, the first data row has bad data
- Change COLUMN A cell format to "date time"
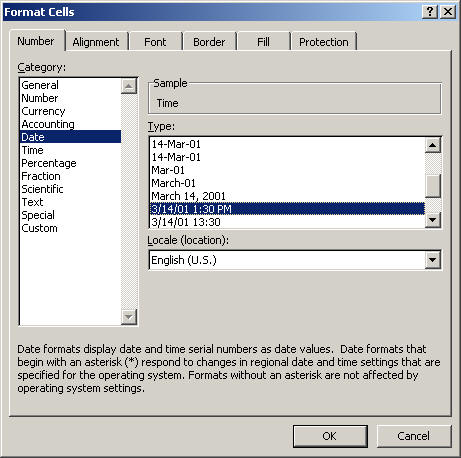
Final look before we start using it the data.
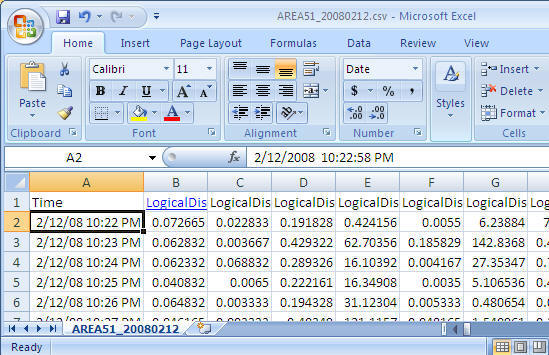
Step 3: Create PivotTable with PivotChart
- From the Insert menu select PivotTable and then select PivotChart as shown below
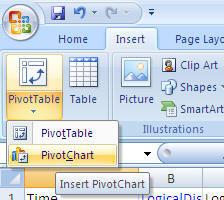
-
Take the default settings and click "OK"
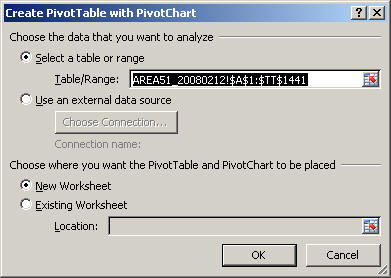
-
After you select the above you will get a screen similar to the following. (to get a bigger workspace area you can close the "PivotChart Filter Pane")
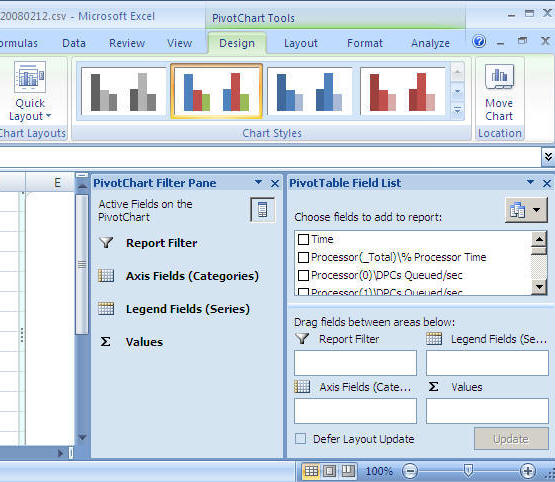
Step 4: Let's generate our first graph
For this example we will look at CPU
- From the "PivotTable Field List" select "Time" and drag it into the "Axis Fields (Categories)" area
- From the "PivotTable Field List" select "Process(_Total)\% Process Time" and drag it into the "Values" area
- At this point you will have a graph similar to the one shown below
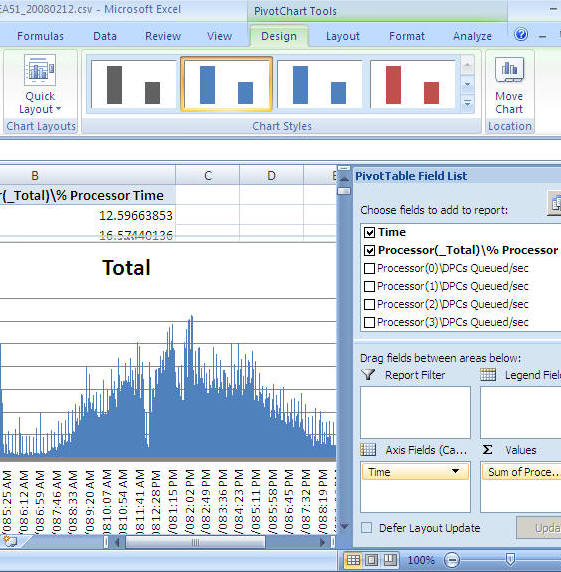
-
You can now just select the chart and copy and paste it into a report, an email, Word document etc... as shown below
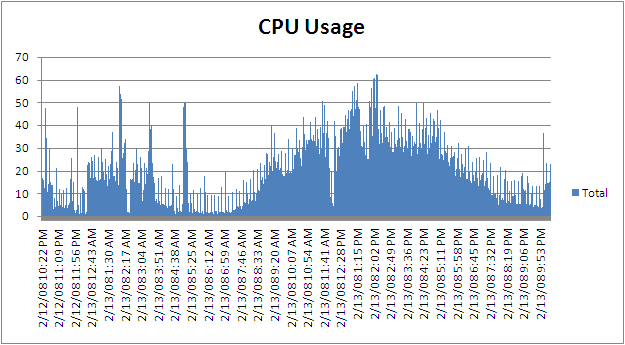
-
If you want to change it from processor time to batch requests you can remove "Process(_Total)\% Process Time" and select "SQLServer:SQL Statistics\Batch Requests/sec" and you will get a chart like below
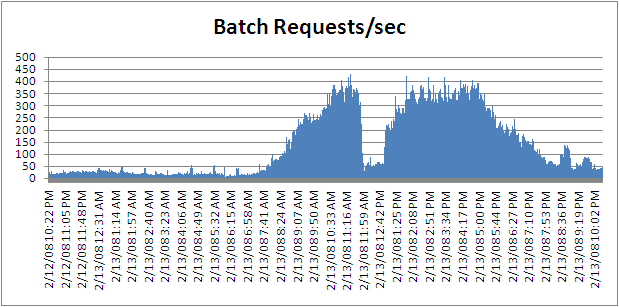
Next Steps
- There are many ways to extend this reporting to make it more useful for both short term and long term needs. In order to do that, it is easier to load the Perfmon data into SQL Server and use the power of SQL Server along with Excel to generate the reports.
- By using the "relog" tool, you can load the Perfmon data directly into SQL Server
- By using the "logman" tool, you can setup Perfmon to store the performance data directly to SQL Server
- To get you started you can download a sample CSV file here with a lot of performance counters
- Here are a few more examples of reports and charts you can create
Sample 1
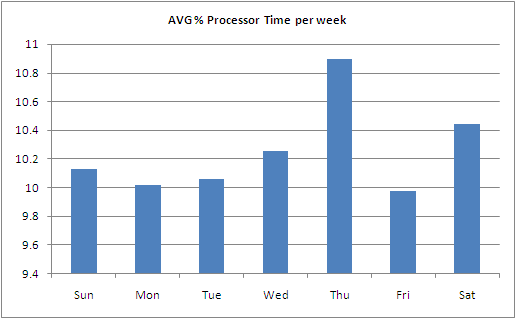
Sample 2
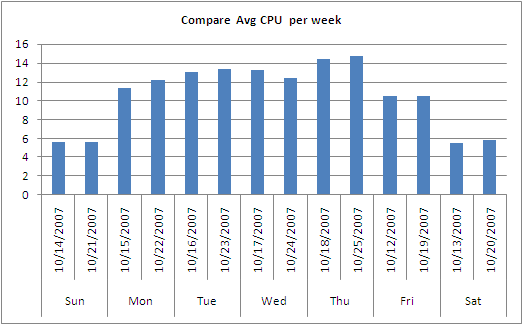
Sample 3
Related Tips
Forum Posts
- Discuss this tip: http://blogs.mssqltips.com/forums/t/640.aspx
- There are 0 comments for this tip
이 글은 스프링노트에서 작성되었습니다.
'Peformance Tuning' 카테고리의 다른 글
| 성능::ReadTrace 사용법 (0) | 2010.06.03 |
|---|---|
| SQL서버 성능카운터 (0) | 2010.06.03 |
| read-ahead는 무었인가? (0) | 2009.12.03 |
| DeadLock 예제,재 실행하기 (0) | 2009.11.24 |
 Prev
Prev

