'Replication'에 해당되는 글 13건
- 2014.08.19 SQL Server Replication Error - The specified LSN for repldone log scan occurs before the current start of replication in the log
- 2012.01.30 복제::스키마 옵션
- 2011.01.16 복제::숨겨진 저장프로시저 확인
- 2010.06.04 복제::LOB DataType 제한
- 2010.06.04 복제::#5 구현&삭제 스크립트
- 2010.06.04 복제::머지복제에러
- 2010.06.04 복제::스냅숏 DB를 사용한 게시 초기화
- 2010.04.13 복제::지연된 명령어 확인
- 2010.03.15 복제::잘못 삭제 했을 경우
- 2009.12.28 복제::트랜잭션 복제 배포agent 실행중 상태 모니터링
- 2009.11.23 Error::복제 에러로그 1
- 2009.07.17 복제::Snaphort DB 이용한 데이터 초기화.
- 2009.07.10 복제::article 상세 속성 정보
SQL Server Replication Error - The specified LSN for repldone log scan occurs before the current start of replication in the log
원본 :
http://www.mssqltips.com/sqlservertip/3288/sql-server-replication-error--the-specified-lsn-for-repldone-log-scan-occurs-before-the-current-start-of-replication-in-the-log/?utm_source=dailynewsletter&utm_medium=email&utm_content=headline&utm_campaign=20140815
Problem
When working with SQL Server Replication there are times when you may get critical errors related to the Log Reader Agent. One of these errors is "The specified LSN [xxx] for repldone log scan occurs before the current start of replication in the log [xxx]". In this tip I will show how to deal with this type of error.
Solution
I'll give recommendations on how to fix the replication error and here is an actual error message as an example to help us analyze the issue:
The specified LSN {00000023:000000f8:0003} for repldone log scan occurs before the current
start of replication in the log {00000023:000000f9:0005}.
Below we can see what this error looks like using the Replication Monitor within SQL Server Management Studio.
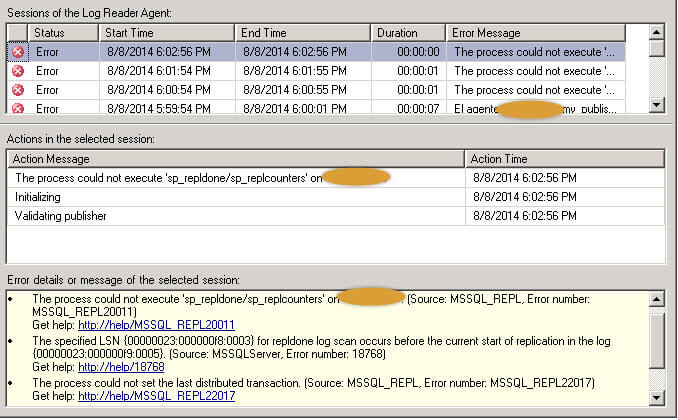
Note: these errors can be found in the Log Reader Agent history and also using SQL Server's Replication Monitor.
The Log Reader Agent is an executable that continuously reads the Transaction Log of the database configured for transactional replication and copies the transactions marked for replication from the Transaction Log into the msrepl_transactions table in the Distribution database. It is important to know that when the Log Reader Agent starts it first verifies that the last transaction in the msrepl_transactions table in the Distribution database matches the Last Replicated Transaction in the Transaction Log for the published database (that is, the current start of replication). When this does not occur, an error will appear like shown above. Note that the msrepl_transactions table is a critical table and it must not be modified manually, because the Log Reader agent works based on the data in this table. If some entries are deleted or modified incorrectly then we will get many replication errors and one of them is what we are talking about in this tip.
Analyzing the SQL Server Replication Issue
As per our error message for this example, we can execute DBCC OPENTRAN on the published database to find more details about the opened and active replication transaction:
Replicated Transaction Information:
Oldest distributed LSN : (35:249:5)
Oldest non-distributed LSN : (35:251:1)
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
Note that DBCC OPENTRAN gives us the LSN value in Decimal format and we need to convert the LSN from Decimal to Hexadecimal for further analysis. Below I have converted the values from decimal to hexadecimal.
Oldest distributed LSN : (35:249:5) --> 00000023:000000f9:0005 (must match last row in msrepl_transactions table)
Oldest non-distributed LSN : (35:251:1) --> 00000023:000000fb:0001 (oldest LSN in the transaction log)
If we analyze the output again,
The specified LSN {00000023:000000f8:0003} for repldone log scan occurs before the current
start of replication in the log {00000023:000000f9:0005}.
we can confirm that the LogReader agent is expecting to find LSN 000000f8 of VLF 00000023 which is currently the last entry in the msrepl_transactions table, but this is not the correct Last Replicated Transaction LSN. For SQL Server the correct Last Replicated Transaction LSN is 000000f9.
Note also that the oldest LSN in the Transaction Log is 000000fb of the same VLF 00000023. This means that the Log Reader is trying to start reading on LSN 000000f8 which is before the current start of replication in the log with LSN 000000f9.
You might be thinking about just moving the Log Reader to start at 000000f9 to fix this error? The problem is that we do not know exactly how many transactions there are from 000000f8 to 000000f9, so if we move the Log Reader Agent pointer forward then we could miss some transactions and create data inconsistency issues.
Fixing the SQL Server Replication Issue
If you decide to move the Log Reader you can do it by using sp_repldone to mark 00000023:000000f9:0005 as the last replicated transaction, so you can skip and move forward. This can be done as shown below. Here we are using the values from the error message: {00000023:000000f9:0005} or 00000023000000f90005. We then flush and restart.
exec sp_repldone @xactid = x00000023000000f90005 , @xact_segno = x00000023000000f90005 GO -- releasing article cache... exec sp_replflush GO --Resetting LogReader to retrieve next transaction... --LogReader Agent will start up and begin replicating transactions.... exec sp_replrestart
With the above code, the error will disappear and the LogReader agent should continue running without error. If you want to know more about the LogReader Agent, you can review the links at the end of this tip.
Note: You should use sp_repldone only to troubleshoot specific internal replication errors and not use this as a regular way to fix issues. In the case where you have more continuous errors like above it is better to recreate the replication publication again by dropping and then recreating.
Use sp_repldone with extreme caution because if you use the incorrect LSN you may skip valid transactions from the replication queue and you can create data inconsistency issues at the subscribers.
Fixing Error After a SQL Server Database Restore
Sometimes this type of error can appear after you restore a database that has publications. In this case an error similar to this will appear:
The specified LSN {00000000:00000000:0000} for repldone log scan occurs before the current
start of replication in the log {00000023:000000f9:0005}.
You can see that Log Reader wants to start reading at LSN {00000000:00000000:0000} and it is because the msrepl_transactions table is empty. In this specific case you also can run sp_repldone to skip all false pending transactions in the msrepl_transactions table and move forward, so the LogReader ignores the incorrect starting point and can continue working.
exec sp_repldone @xactid=NULL, @xact_segno=NULL, @numtrans=0, @time=0, @reset=1
Note that we use @reset=1 to mark all replicated transactions in the Transaction Log as distributed.
'Replication' 카테고리의 다른 글
| 복제::스키마 옵션 (0) | 2012.01.30 |
|---|---|
| 복제::숨겨진 저장프로시저 확인 (0) | 2011.01.16 |
| 복제::LOB DataType 제한 (0) | 2010.06.04 |
| 복제::#5 구현&삭제 스크립트 (0) | 2010.06.04 |
Problem
My company uses replication quite extensively across SQL 2000, SQL 2005 and SQL 2008 servers. The problem with using different versions of SQL Server is that the replication options do not always behave the same way. Because of these differences we have stopped using SQL Server Management Studio and Enterprise Manager to setup replication. Also we have taken the time to look at the schema options for replication to make sure the end result is the same for all versions of SQL Server.
Solution
We basically have two requirements for replication which are outlined below. I have listed the different schema options that the GUI generates to show how things work differently in different versions of SQL Server as well as the options we selected for our environment.
Background Information
Here are two articles related to this tip that you should understand.
- Books Online: sp_addarticle (Transact-SQL)
- How to: Specify Schema Options (Replication Transact-SQL Programming)
If you look at the schema option on sp_addarticle (Transact-SQL), you will see there are over 40 combinations of schema options and it can be hard to know which one to choose. The article, How to: Specify Schema Options (Replication Transact-SQL Programming) shows how to figure out and specify schema options.
Replication Requirements
My company has two different requirements for replication as outlined below. When using the GUI with different versions of SQL Server several different schema options are generated, but they do not always work the same across all versions of SQL Server.
Requirement 1
- Replicate the Primary Key with index that is related to the primary key constraint
- Convert User Defined Types (UDTs) to base data types at the Subscriber
- Use SQL Stored Procedures to replicate (auto generate store procedures on subscribers for Insert, Update and Delete)
Based on the above, I have tested the below combinations and as you can see different version have different results for the 0xB3 option.
Schema Option |
Publisher Version |
Distributor Version |
Subscriber Version |
Description |
| 0x00000000000000A3 | SQL2K | SQL2K5 | SQL2K | No PK with same index type as PK |
| SQL2K | SQL2K5 | SQL2K8 | No PK with same index type as PK | |
| SQL2K8 | SQL2K8 | SQL2K8 | No PK with same index type as PK | |
| 0x00000000000080A3 | SQL2K | SQL2K5 | SQL2K | PK with no other index |
| SQL2K | SQL2K5 | SQL2K8 | PK with no other index | |
| SQL2K8 | SQL2K8 | SQL2K8 | PK with no other index | |
| 0x00000000000000B3 | SQL2K | SQL2K5 | SQL2K | The same index as PK on publisher, but NO PK constraints |
| SQL2K | SQL2K5 | SQL2K8 | The same index as PK on publisher, but NO PK constraints |
|
| SQL2K | SQL2K8 | SQL2K8 | The same index as PK on publisher, but NO PK constraints |
|
| SQL2K5 | SQL2K8 | SQL2K8 | PK with no other index with clustered index | |
| SQL2K8 | SQL2K8 | SQL2K8 | PK with no other index with clustered index | |
| 0x00000000000080B3 | SQL2K | SQL2K5 | SQL2K | PK with clustered index even if the index is not part of PK |
| SQL2K | SQL2K5 | SQL2K8 | PK with clustered index even if the index is not part of PK |
|
| SQL2K8 | SQL2K8 | SQL2K8 | PK with clustered index even if the index is not part of PK |
|
| 0x00000000000082A3 | SQL2K | SQL2K5 | SQL2K | PK + FK with clustered index even if the index is not part of PK |
| SQL2K | SQL2K5 | SQL2k8 | PK + FK with clustered index even if the index is not part of PK |
|
| SQL2K8 | SQL2K8 | SQL2K8 | PK + FK with clustered index even if the index is not part of PK |
* PK - Primary Key
* FK - Foreign Key
So, based on the above, I have concluded that our company, "0x00000000000080A3" fits our needs.
Requirement 2
- All of the Requirement 1 plus
- Replicate all Indexes on Publisher
| Schema Option | Publisher Version |
Distributor Version |
Subscriber Version |
Description |
| 0x0000000000001073 | SQL2K | SQL2K5 | SQL2k | No PK with all indexes (no FK) |
| SQL2K | SQL2K5 | SQL2k8 | No PK with all indexes (no FK) | |
| SQL2K8 | SQL2K8 | SQL2K8 | PK with all indexes (no FK) | |
| 0x00000000000080F3 | SQL2K | SQL2K5 | SQL2k | PK with all indexes (no FK) |
| SQL2K | SQL2K5 | SQL2k8 | PK with all indexes (no FK) | |
| SQL2K8 | SQL2K8 | SQL2K8 | PK with all indexes (no FK) | |
| 0x00000000000082F3 | SQL2K | SQL2K5 | SQL2k | PK+FK with all indexes |
| SQL2K | SQL2K5 | SQL2k8 | PK+FK with all indexes | |
| SQL2K8 | SQL2K8 | SQL2K8 | PK+FK with all indexes |
Based on the testing, we have decide to use "0x00000000000080F3".
Confirmation
Now, here is simple query that I use to confirm the options.
If you run this for 0x00000000000080A3:
declare @pubid int declare @optionid bigint declare @schema_option varbinary(2000) set @optionid = 1 set @schema_option = 0x00000000000080A3 WHILE (@optionid <= 2147483648) BEGIN if (select @schema_option & @optionid) > 0 PRINT cast(@optionid as varbinary) SET @optionid = @optionid * 2 END |
You will see this result:
0x0000000000000001 0x0000000000000002 0x0000000000000020 0x0000000000000080 0x0000000000008000 |
You can check Books Online: sp_addarticle (Transact-SQL) and you will see the below options. Note, in Books Online they shorten the notation, so 0x0000000000000001 = 0x01.
- 0x0000000000000001 - Generates the object creation script (CREATE TABLE, CREATE PROCEDURE, and so on). This value is the default for stored procedure articles.
- 0x0000000000000002 - Generates the stored procedures that propagate changes for the article, if defined.
- 0x0000000000000020 - Converts user-defined data types (UDT) to base data types at the Subscriber. This option cannot be used when there is a CHECK or DEFAULT constraint on a UDT column, if a UDT column is part of the primary key, or if a computed column references a UDT column. Not supported for Oracle Publishers.
- 0x0000000000000080 - Replicates primary key constraints. Any indexes related to the constraint are also replicated, even if options 0x10 and 0x40 are not enable
- 0x0000000000008000 - This option is not valid for SQL Server 2005 Publishers.
If we do the same for 0x00000000000080F3, we get this output:
- 0x0000000000000001 - Generates the object creation script (CREATE TABLE, CREATE PROCEDURE, and so on). This value is the default for stored procedure articles.
- 0x0000000000000002 - Generates the stored procedures that propagate changes for the article, if defined.
- 0x0000000000000010 - Generates a corresponding clustered index. Even if this option is not set, indexes related to primary keys and unique constraints are generated if they are already defined on a published table.
- 0x0000000000000020 - Converts user-defined data types (UDT) to base data types at the Subscriber. This option cannot be used when there is a CHECK or DEFAULT constraint on a UDT column, if a UDT column is part of the primary key, or if a computed column references a UDT column. Not supported for Oracle Publishers.
- 0x0000000000000040 - Generates corresponding nonclustered indexes. Even if this option is not set, indexes related to primary keys and unique constraints are generated if they are already defined on a published table.
- 0x0000000000000080 - Replicates primary key constraints. Any indexes related to the constraint are also replicated, even if options 0x10 and 0x40 are not enable
- 0x0000000000008000 - This option is not valid for SQL Server 2005 Publishers.
'Replication' 카테고리의 다른 글
| SQL Server Replication Error - The specified LSN for repldone log scan occurs before the current start of replication in the log (0) | 2014.08.19 |
|---|---|
| 복제::숨겨진 저장프로시저 확인 (0) | 2011.01.16 |
| 복제::LOB DataType 제한 (0) | 2010.06.04 |
| 복제::#5 구현&삭제 스크립트 (0) | 2010.06.04 |
- 복제 관련 시스템 저장프로시저 내용을 확인해 보고 싶을 경우가 종종 있다.
- 성능을 향상 시키고자 할 때나, 문제를 해결 하고자 할 때
- 그런데 시스템 저장 프로시저 내용을 확인하기는 쉽지 않다.
- 그런데 방법은 있다.
- DAC 기능을 활성화 한다. 혹은 sqlcmd 명영 유틸을 사용시에는 -A 옵션을 사용한다.
exec sp_configure 'remote admin connections', 1 go reconfigure go
2. 저장 프로시저 내역 확인
select object_definition (object_id('sys.sp_MSrepl_helparticlecolumns') )
3. 서비스에서 작업을 진행 했다면, DAC 연결을 반드시 종료한다.
'Replication' 카테고리의 다른 글
| SQL Server Replication Error - The specified LSN for repldone log scan occurs before the current start of replication in the log (0) | 2014.08.19 |
|---|---|
| 복제::스키마 옵션 (0) | 2012.01.30 |
| 복제::LOB DataType 제한 (0) | 2010.06.04 |
| 복제::#5 구현&삭제 스크립트 (0) | 2010.06.04 |
- --CREATE TABLE [dbo].[odd_repl_data_snapshot](
-- [gd_no] [varchar](10) NOT NULL,
-- [org_data] [text] NULL,
--) --ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] - /*
update a
set a.org_data = b.org_data
from repl_source.dbo.odd_repl_data_snapshot a with(nolock)
inner join repl_source.dbo.dup_data b with(nolock) on a.gd_no = b.gd_no
*/ - declare @ptr varbinary(16)
declare @str varchar(max)
select @str = org_data
from repl_check.dbo.dup_data with(nolock) where gd_no = '117368652' - select @ptr= textptr(org_data)
from repl_check.dbo.odd_repl_data_snapshot with(nolock)
where gd_no = '117368652'
writetext repl_check.dbo.odd_repl_data_snapshot.org_data @ptr with log @str - --
--
update a
set a.org_data = b.org_data
from repl_source.dbo.test_varcharmax a with(nolock)
inner join repl_check.dbo.dup_data b with(nolock) on a.gd_no = b.gd_no
--truncate table repl_target.dbo.odd_repl_data_snapshot
--truncate table repl_target.dbo.test_varcharmax- select --a.gd_no , substring (b.org_data , b.break_idx , 20) , substring(b.org_data , b.break_idx , 20)
a.gd_no , datalength(b.org_data) , datalength(a.org_data)
from repl_target.dbo.odd_repl_data_snapshot a with(nolock)
inner join repl_source.dbo.dup_data b with(nolock) on a.gd_no = b.gd_no
where b.seqno <= 3
select --a.gd_no , substring (b.org_data , b.break_idx , 20) , substring(b.org_data , b.break_idx , 20)
a.gd_no , datalength(b.org_data) , datalength(a.org_data) , datalength(c.org_data)
from repl_target.dbo.test_varcharmax a with(nolock)
inner join repl_source.dbo.test_varcharmax c with(nolock) on a.gd_no = c.gd_no
inner join repl_source.dbo.dup_data b with(nolock) on a.gd_no = b.gd_no
where b.seqno <= 3
update repl_target.dbo.odd_repl_data_snapshot set org_data= '' where gd_no = '117368652'- --
--CREATE TABLE [dbo].[test_varcharmax](
-- [gd_no] [varchar](10) NOT NULL,
-- [org_data] [varchar](max) NULL,
--
--) - backup database repl_check to disk='e:\repl_source_full.BAK' with stats
go
backup database repl_target to disk='e:\repl_target_full.BAK' with stats
이 글은 스프링노트에서 작성되었습니다.
'Replication' 카테고리의 다른 글
| 복제::스키마 옵션 (0) | 2012.01.30 |
|---|---|
| 복제::숨겨진 저장프로시저 확인 (0) | 2011.01.16 |
| 복제::#5 구현&삭제 스크립트 (0) | 2010.06.04 |
| 복제::머지복제에러 (0) | 2010.06.04 |
복제 삭제
- 방법 1: http://msdn.microsoft.com/ko-kr/library/ms152757.aspx
- 방법 2: http://support.microsoft.com/kb/324401
-
이상하게 잘 못 삭제했을 경우
-
select replinfo,* from sysobjects where replinfo = 0 을 찾아서 입력합니다.
-
sp_removedbreplication [ [ @dbname = ] 'dbname' ] [ , [ @type = ] type ] -
-
-
- [ @dbname=] 'dbname'
-
-
- 데이터베이스의 이름입니다. dbname은 sysname이며 기본값은 NULL입니다. NULL인 경우 현재 데이터베이스를 사용합니다.
-
-
- [ @type = ] type
-
-
- 데이터베이스 개체를 제거 중인 복제의 유형입니다. type은 nvarchar(5)이며 다음 값 중 하나일 수 있습니다.
- tran
- 트랜잭션 복제 게시 개체를 제거합니다.
- merge
- 병합 복제 게시 개체를 제거합니다.
- both(기본값)
- 모든 복제 게시 개체를 제거합니다.
-
ERROR CASE
게시& 배포자가 먼저 삭제되고 구독이 남아 있을 경우
이 글은 스프링노트에서 작성되었습니다.
'Replication' 카테고리의 다른 글
| 복제::숨겨진 저장프로시저 확인 (0) | 2011.01.16 |
|---|---|
| 복제::LOB DataType 제한 (0) | 2010.06.04 |
| 복제::머지복제에러 (0) | 2010.06.04 |
| 복제::스냅숏 DB를 사용한 게시 초기화 (0) | 2010.06.04 |
FIX: Error message when you try to insert data on a subscriber of a merge replication in SQL Server 2005: "Msg 548, Level 16, State 2, Line 1. The insert failed"
On This Page
SYMPTOMS
The insert failed. It conflicted with an identity range check constraint in database 'DatabaseName', replicated table 'Schema.TableName', column 'ColumnName'. If the identity column is automatically managed by replication, update the range as follows: for the Publisher, execute sp_adjustpublisheridentityrange; for the Subscriber, run the Distribution Agent or the Merge Agent.
This problem occurs when multiple Merge Agents synchronize data at the same time for the same merge publication. This problem can be exacerbated if you have many subscribers to the merge publication.

CAUSE
RESOLUTION
WORKAROUND
sp_changemergepublication '<PublicationName>', 'max_concurrent_merge', 1
Note After you use this workaround, performance may decrease if you have many subscribers for the publication. This behavior occurs because only one subscriber can synchronize data at a time.
STATUS
MORE INFORMATION
How to determine whether you are experiencing this problem
To determine whether you are experiencing this problem, follow these steps:| 1. | Verify that the current identity value is smaller than the lower bound of the first identity range of the identity range check constraint. To obtain the current identity value, run the following statement:
To obtain the identity ranges of the identity range check constraint, run either of the following statements:
Statement 1
Statement 2
|
| 2. | Use a SQL Server Profiler trace to determine whether interleaved executions of the sp_MSsetup_publisher_idrange stored procedure are started by separate Merge Agent sessions for the same publication. However, interleaved executions of the sp_MSsetup_publisher_idrange stored procedure do not always indicate that you are experiencing this problem. This is because SQL Server Profiler was not running when the original occurance of the merge synchronization generated the first error message. However, interleaved executions of the sp_MSsetup_publisher_idrange stored procedure do increase the possibility of experiencing this problem. |
| 3. | You can find overlapping merge synchronizations that occur when you receive the "548" error message occurs. To do this, you can review the merge history in the distribution database. To do this, run the following statements:
|
How to correct existing damaged identity ranges for a problematic table
After you install the cumulative update or after you use the method that is described in the workaround section, an existing damaged identity range in a table is not corrected. You will still receive the "548" error message if you try to insert data into the table and synchronize data on a subscriber. Therefore, you must manually correct the damaged identity ranges for the table. To do this, follow these steps.Note These steps involve manually overriding the current identity seed value for the table to correctly reseed the identity value at the publisher. In the damaged state, the current identity value is smaller than the first identity range in the merge replication identity range check constraint. The steps manually raise the identity value to fall inside the identity range that is defined by the merge replication identity range check constraint. These steps assume that identities are configured in an ascending manner and that the identity increment is configured to increase by a value of 1.
| 1. | Confirm that the identity increment value is 1 and that the identity proceeds in ascending manner. You can obtain the identity increment value by running the following statement on the publisher:
|
||||
| 2. | Run the following statement on the publisher to find the current identity value on the problematic identity column:
After you receive the result, note the current identity value value for comparison in the later steps. Notice that the current column value valye may be either larger or smaller than the current identity value value.If the current column value value is larger than the current identity value value, the column value may have originated at other replications in the topology and merged successfully with the publisher replication. If the current column value value is smaller than the current identity value value, the values may have been inserted on the publisher at a earlier time by using the SET IDENTITY_INSERT ON statement before the merge replication configuration. |
||||
| 3. | Run the following statements on the publisher to determine the current identity ranges of the identity range check constraint for the problematic table:
After you receive the result, note the value of the constraint_keys column of the record where the value of the constraint_name column is "repl_identity_range_GUID". The GUID value corresponds to the value of the artid column for the article in the sysmergearticles system table. To obtain the GUID, run the following statement:
The identity range check constraint spans two separate ranges. The two sets of ranges do not have to be contiguous. For example, the value of the constraint_keys column can be as follows:
([ColumnName]>(1001) AND [ColumnName]<=(2001)
Note This article uses this example to present code in the rest of steps.OR [ColumnName] > (9001) AND [ColumnName]<=(10001)) In this example, the ranges each span 1,000 values. 1,000 is the default range size. However, you can change the identity range size by using one of the following methods:
|
||||
| 4. | If you experience the problem that is described in the "Symptoms" section, the current identity value that you noted in step 2 should be smaller than the lower bound of the first identity range of the identity range check constraint that you noted in step 3. If the current identity value in step 2 is larger than the upper bound of the second identity range of the identity range check constraint, resolve the problem by using the method that is recommended in the error message. Therefore, you should run the sp_adjustpublisheridentityrange stored procedure on the publisher. For more information about the sp_adjustpublisheridentityrange stored procedure, visit the following Microsoft Developer Network (MSDN) Web site: http://msdn.microsoft.com/en-us/library/ms181527.aspx (http://msdn.microsoft.com/en-us/library/ms181527.aspx)
|
||||
| 5. | Run the following statement to determine whether any rows are in the current identity ranges of the identity range check constraint:
Notes
|
||||
| 6. | Manually reseed the current identity for the problematic table to fall inside a valid range. Reseed the current identity to the lowest value of the current identity ranges plus 1. For example, if the lowest value of the current identity ranges is 1001, the first possible in-range value is 1002 because the low end of the range of the identity range check constraint uses the greater than sign (>). To do this, run the following statement on the publisher, and then go to step 8:
|
||||
| 7. | Manually reseed the current identity for the problematic table to fall inside a valid range. Assume that the identity increment is 1. Reseed the current identity to the value that you noted in step 5, and then add 1. For example, if the value that you noted in step 5 is 1507, reseed the current identity to 1508. To do this, run the following statement on the publisher:
|
||||
| 8. | Perform a test to determine whether new rows can be inserted into the table in the publisher database without error 548 occurring. |
REFERENCES
For more information about the list of builds that are available after SQL Server Service Pack 2, click the following article number to view the article in the Microsoft Knowledge Base:
For more information about the Incremental Servicing Model for SQL Server, click the following article number to view the article in the Microsoft Knowledge Base:
For more information about how to obtain SQL Server 2005 Service Pack 2, click the following article number to view the article in the Microsoft Knowledge Base:
For more information about the new features and the improvements in SQL Server 2005 Service Pack 2, visit the following Microsoft Web site:
For more information about the naming schema for SQL Server updates, click the following article number to view the article in the Microsoft Knowledge Base:
For more information about software update terminology, click the following article number to view the article in the Microsoft Knowledge Base:
이 글은 스프링노트에서 작성되었습니다.
'Replication' 카테고리의 다른 글
| 복제::LOB DataType 제한 (0) | 2010.06.04 |
|---|---|
| 복제::#5 구현&삭제 스크립트 (0) | 2010.06.04 |
| 복제::스냅숏 DB를 사용한 게시 초기화 (0) | 2010.06.04 |
| 복제::지연된 명령어 확인 (0) | 2010.04.13 |
스냅숏 DB를 사용한 게시 초기화 방법
트랜잭션 복제, 병합복제, 스냅숏 복제에 게시를 초기화 하는 방법 중에 스냅숏 DB를 사용한 게시 초기화 방법.
- SQL Server 2005 Enterprise Edition 서비스 팩 2 이상 버전일 경우만 가능
현재 구독 초기화 방법중 알고 있는 방법은
- 스냅숏 복제를 이용하는 방법
- Db 백업 후 복원을 이용하는 방법
- 게시할 테이블을 BCP 나 SSIS를 통해 데이터를 이관해 둔 상태로 처리하는 방법
- 스냅숏 DB를 사용하는 방법
방법
게시의 속성 중에 sync_method 옵션중에 database snapshot 가 추가 되었음 (database snaphort character : 문자모드, 사용하지 않은 것이 좋을 것 같음)
해당 옵션은 복제 마법사를 통해서 세팅이 불가능하며, 게시를 설정한 후 아래 스크립트로 변경해야 한다.
-
-- 게시 DB에서 실행 해야 한다.
-
exec sp_helppublication; -- 조해 본다.
exec sp_changepublication
@publication = '게시 이름',
@force_invalidate_snapshot = 1,
@property = 'sync_method',
@value = 'database snapshot' -- 5번
결과
- 이 방법으로 변경해서 게시를 초기화 하게 되면 게시이름_DB 이름으로 스탭숏 DB가 생성되며, 게시가 초기화 완료되면 삭제된다. 기존에 동일한 스탭숏 DB가 있다고 해도 항상 새로 생성한다.
- 대용량 DB일 경우 스탭숏 DB를 생성할 공간만 있다면, 이 방법을 사용했을 때 스냅숏 초기화 하는 과정 동안 서비스 DB에 테이블 lock가 걸리지 않으므로 서비스에 지장이 덜 가게 된다.
- 스냅숏 복제 작동 방법 : http://msdn.microsoft.com/ko-kr/library/ms151734(SQL.90).aspx
참고
- 대용량 DB일 경우 Arrary 스토리지를 사용해서 백업/복원하는 초기화 방법을 빠르게할 수도다.: http://sqlcat.com/technicalnotes/archive/2009/05/04/initializing-a-transactional-replication-subscriber-from-an-array-based-snapshot.aspx
- sync_mode 사용 초기화 : http://blogs.msdn.com/mangeshd/archive/2008/05/30/how-to-use-database-snapshot-sync-mode-while-creating-a-new-tran-snapshot-publication-using-sp-addpublication.aspx
- http://sqlcat.com/whitepapers/archive/2008/02/11/database-snapshot-performance-considerations-under-i-o-intensive-workloads.aspx
이 글은 스프링노트에서 작성되었습니다.
'Replication' 카테고리의 다른 글
| 복제::#5 구현&삭제 스크립트 (0) | 2010.06.04 |
|---|---|
| 복제::머지복제에러 (0) | 2010.06.04 |
| 복제::지연된 명령어 확인 (0) | 2010.04.13 |
| 복제::잘못 삭제 했을 경우 (0) | 2010.03.15 |
복제에 문제가 생길 때 보실 수 있는 내역입니다. 어제 이 방법으로 확인했습니다.
평소 문제가 없을때는 MSrepl_commands 조회시 top 을 주시는 것이 좋습니다.
-- 에러가나는agent에대한마지막으로실행된명령어정보확인
select agent_id, max(xact_seqno) as 'MaxTranNo', max(time) as 'Lasted'
from Msdistribution_history with (nolock)
where xact_seqno > 0x0 and agent_id = 29
group by agent_id
order by agent_id
1. 해당 게시명은 아는데 agent를 모를 경우 쉽게 알 수 있는 법은 배포 장비의 job중에 해당 게시의 배포 agent 명을 보면 뒤에 붙어 있는 숫자가 Agent 아이디 입니다.
아니면 select id, name , publication from MSdistribution_agents 하면 게시에 대한 agent를 확인 할 수 있습니다.
-- 마지막실행된이후명령어갯수확인
select top 10 sys.fn_sqlvarbasetostr(min(xact_seqno))
from MSrepl_commands as c with (nolock)
inner join MSarticles as a with (nolock) on c.article_id =a.article_id
inner join MSpublications as p with (nolock) on a.publication_id =
p.publication_id
where c.publisher_database_id = 2
and p.publication = '게시명'
and c.xact_seqno > 0x004BDF9200501314000C
--order by c.xact_seqno
2. 1번에서 실행된 agent에서 가장 마지막으로 실행된 xact_seqno 를 아셨으면 그 번호 이상인 명령이 무엇인지 확인하는 것입니다.
이때 MSrepl_commands 테이블만으로 조해 해보면 모든 게시자 DB에 여러 개의 게시가 있을 경우 다른 게시에 대한 것도 보이니 아티클로 아셔서 보시거나 윗 처럼 조인해서 보시면 됩니다.
-- 최종으로어떤명령어인지확인
exec sp_browsereplcmds
@xact_seqno_start = '0x004BDF9200501DD30018'
,@xact_seqno_end = '0x004BDF92005085BD0014'
,@publisher_database_id = 2
-- ,@agent_id = 29
3. 최종적으로 비슷한 xact_seqno가 동일한게 여러 개 보이면 범위주어서 찾아보시면 됩니다.
인자로 @agent_id 값을 넣으면 조회가 오래 걸리니 안 넣으시게 좋을 것 같습니다.
추가 ) 지연된 명령어 수 확인
exec sp_replmonitorsubscriptionpendingcmds
@publisher ='Enter publisher server name',
@publisher_db = 'Enter publisher database name',
@publication ='Enter name of publication',
@subscriber ='Enter subscriber server name',
@subscriber_db ='Enter subscriber database name',
@subscription_type ='0' --0 for push and 1 for pull
'Replication' 카테고리의 다른 글
| 복제::머지복제에러 (0) | 2010.06.04 |
|---|---|
| 복제::스냅숏 DB를 사용한 게시 초기화 (0) | 2010.06.04 |
| 복제::잘못 삭제 했을 경우 (0) | 2010.03.15 |
| 복제::트랜잭션 복제 배포agent 실행중 상태 모니터링 (0) | 2009.12.28 |
복제 삭제
- 방법 1: http://msdn.microsoft.com/ko-kr/library/ms152757.aspx
- 방법 2: http://support.microsoft.com/kb/324401
-
이상하게 잘 못 삭제했을 경우
-
select replinfo,* from sysobjects where replinfo = 0 을 찾아서 입력합니다.
sp_removedbreplication [ [ @dbname = ] 'dbname' ] [ , [ @type = ] type ]-
-
- [ @dbname=] 'dbname'
-
-
- 데이터베이스의 이름입니다. dbname은 sysname이며 기본값은 NULL입니다. NULL인 경우 현재 데이터베이스를 사용합니다.
-
-
- [ @type = ] type
-
-
- 데이터베이스 개체를 제거 중인 복제의 유형입니다. type은 nvarchar(5)이며 다음 값 중 하나일 수 있습니다.
- tran
- 트랜잭션 복제 게시 개체를 제거합니다.
- merge
- 병합 복제 게시 개체를 제거합니다.
- both(기본값)
- 모든 복제 게시 개체를 제거합니다.
-
ERROR CASE
게시& 배포자가 먼저 삭제되고 구독이 남아 있을 경우
'Replication' 카테고리의 다른 글
| 복제::스냅숏 DB를 사용한 게시 초기화 (0) | 2010.06.04 |
|---|---|
| 복제::지연된 명령어 확인 (0) | 2010.04.13 |
| 복제::트랜잭션 복제 배포agent 실행중 상태 모니터링 (0) | 2009.12.28 |
| Error::복제 에러로그 (1) | 2009.11.23 |
작업으로 인해 배포자 agent를 중지하고 작업 처리후 시작하는 것을 잊어버리는 수가 있다. 혹은 다른 문제로 인해 배포 agent가 실행되고 있지 않을때,
오래 동안 실행되지 않으면 복제가 실패되어 다시 구축해야 하는 경우가 발생한다.
아래 쿼리는 배포 agent 실행여부를 확인하여 메일이나 SMS를 받을 수 있게 처리하는 것이다.
이또는 해당 job이 실행되고 있거나 오래 실행되는것도 찾을 수 있다.
[code sql] DECLARE @is_sysadmin INT DECLARE @job_owner sysname DECLARE @job_id uniqueidentifier DECLARE @job_name sysname DECLARE @running int DECLARE @cnt int DECLARE @msg varchar(8000) DECLARE @msg_header varchar(4000) DECLARE @categoryid int SELECT @job_owner = SUSER_SNAME() ,@is_sysadmin = 1 ,@running = 0 ,@categoryid = 10 -- Distributor jobs CREATE TABLE #jobStatus (job_id UNIQUEIDENTIFIER NOT NULL, last_run_date INT , last_run_time INT , next_run_date INT , next_run_time INT , next_run_schedule_id INT , requested_to_run INT , request_source INT , request_source_id sysname COLLATE database_default NULL, running int , current_step INT , current_retry_attempt INT , job_state INT) INSERT INTO #jobStatus EXECUTE master.dbo.xp_sqlagent_enum_jobs @is_sysadmin, @job_owner--, @job_id -- select j.name, js.command, jss.running from msdb.dbo.sysjobsteps js join msdb.dbo.sysjobs j on js.job_id = j.job_id join #jobStatus jss on js.job_id = jss.job_id where step_id = 2 and subsystem = 'Distribution' and command like '%-Continuous' and jss.running <> 1 -- Not running [/code]
'Replication' 카테고리의 다른 글
| 복제::지연된 명령어 확인 (0) | 2010.04.13 |
|---|---|
| 복제::잘못 삭제 했을 경우 (0) | 2010.03.15 |
| Error::복제 에러로그 (1) | 2009.11.23 |
| 복제::Snaphort DB 이용한 데이터 초기화. (0) | 2009.07.17 |
2009-11-22 03:20:39.810 로그온 오류: 17806, 심각도: 20, 상태: 2.
2009-11-22 03:20:39.810 로그온 SSPI handshake failed with error code 0x80090311 while establishing a connection with integrated security; the connection has been closed. [클라이언트: IP]
배포자에서 위와 같은 에러
네트워크 문제로
Active Directory서버(Domain Controller라 부름)와의 통신상에 문제가 발생하였을 경우 생성됨
'Replication' 카테고리의 다른 글
| 복제::잘못 삭제 했을 경우 (0) | 2010.03.15 |
|---|---|
| 복제::트랜잭션 복제 배포agent 실행중 상태 모니터링 (0) | 2009.12.28 |
| 복제::Snaphort DB 이용한 데이터 초기화. (0) | 2009.07.17 |
| 복제::article 상세 속성 정보 (0) | 2009.07.10 |
트랜잭션 복제, 병합복제, 스냅숏 복제에 게시를 초기화 하는 방법 중에 스냅숏 DB를 사용한 게시 초기화 방법.
- SQL Server 2005 Enterprise Edition 서비스 팩 2 이상 버전일 경우만 가능
현재 구독 초기화 방법중 알고 있는 방법은
- 스냅숏 복제를 이용하는 방법
- Db 백업 후 복원을 이용하는 방법
- 게시할 테이블을 BCP 나 SSIS를 통해 데이터를 이관해 둔 상태로 처리하는 방법
- 스냅숏 DB를 사용하는 방법
방법
게시의 속성 중에 sync_method 옵션중에 database snapshot 가 추가 되었음 (database snaphort character : 문자모드, 사용하지 않은 것이 좋을 것 같음)
해당 옵션은 복제 마법사를 통해서 세팅이 불가능하며, 게시를 설정한 후 아래 스크립트로 변경해야 한다.
-
-
게시 DB에서 실행
-
exec sp_helppublication;
-
exec sp_changepublication
@publication = '게시 이름',
@force_invalidate_snapshot = 1,
@property = 'sync_method',
@value = 'database snapshot' -- 5번
-
결과
- 이 방법으로 변경해서 게시를 초기화 하게 되면 게시이름_DB 이름으로 스탭숏 DB가 생성되며, 게시가 초기화 완료되면 삭제된다. 기존에 동일한 스탭숏 DB가 있다고 해도 항상 새로 생성한다.
- 대용량 DB일 경우 스탭숏 DB를 생성할 공간만 있다면, 이 방법을 사용했을 때 스냅숏 초기화 하는 과정 동안 서비스 DB에 테이블 lock가 걸리지 않으므로 서비스에 지장이 덜 가게 된다.
- 스냅숏 복제 작동 방법 : http://msdn.microsoft.com/ko-kr/library/ms151734(SQL.90).aspx
참고
- 대용량 DB일 경우 Arrary 스토리지를 사용해서 백업/복원하는 초기화 방법을 빠르게할 수도다.: http://sqlcat.com/technicalnotes/archive/2009/05/04/initializing-a-transactional-replication-subscriber-from-an-array-based-snapshot.aspx
- sync_mode 사용 초기화 : http://blogs.msdn.com/mangeshd/archive/2008/05/30/how-to-use-database-snapshot-sync-mode-while-creating-a-new-tran-snapshot-publication-using-sp-addpublication.aspx
- http://sqlcat.com/whitepapers/archive/2008/02/11/database-snapshot-performance-considerations-under-i-o-intensive-workloads.aspx
'Replication' 카테고리의 다른 글
| 복제::잘못 삭제 했을 경우 (0) | 2010.03.15 |
|---|---|
| 복제::트랜잭션 복제 배포agent 실행중 상태 모니터링 (0) | 2009.12.28 |
| Error::복제 에러로그 (1) | 2009.11.23 |
| 복제::article 상세 속성 정보 (0) | 2009.07.10 |
복제를 구성한 후 article 속성을 셋팅해서 게시 한 경우 추후 Aritical 속성을 확인할때 UI를 통한 확인도 가능하지만 부하가 있는 서버의 복제를 확인할때 UI가 응답 없음으로 될 경우가 있다.
sysarticles 테이블의 schema_option 값에 바이너리 값으로 속성값이 저장되며, 도움말 확인하여 연산해서 속성 확인 가능하다.
http://msdn.microsoft.com/ko-kr/library/ms173857.aspx
(트랜잭션 복제 기준)
,art.dest_table
,case art.pre_creation_cmd when 0 then '없음' when 1 then 'DROP' when 2 then 'DELETE' when 3 then 'TRUNCATE' end as pre_creation_cmd
,case when (art.schema_option & 4) > 0 then 'TRUE' ELSE 'FALE' end as 'identity_ID열'
,case when (art.schema_option & 16) > 0 then 'TRUE' ELSE 'FALE' end as 'clustered'
,case when (art.schema_option & 32) > 0 then 'TRUE' ELSE 'FALE' end as 'UDT'
,case when (art.schema_option & 64) > 0 then 'TRUE' ELSE 'FALE' end as 'nonclustered'
,case when (art.schema_option & 128) > 0 then 'TRUE' ELSE 'FALE' end as 'PK'
,case when (art.schema_option & 256) > 0 then 'TRUE' ELSE 'FALE' end as 'triggers'
,case when (art.schema_option & 512) > 0 then 'TRUE' ELSE 'FALE' end as 'FK'
,case when (art.schema_option & 1024) > 0 then 'TRUE' ELSE 'FALE' end as 'check'
,case when (art.schema_option & 2048) > 0 then 'TRUE' ELSE 'FALE' end as 'default'
,case when (art.schema_option & 16384) > 0 then 'TRUE' ELSE 'FALE' end as 'unique_const'
,case when (art.schema_option & 134217728) > 0 then 'TRUE' ELSE 'FALE' end as 'ddl'
,case when (art.schema_option & 262144) > 0 then 'TRUE' ELSE 'FALE' end as 'filegroup'
,case when (art.schema_option & 524288) > 0 then 'TRUE' ELSE 'FALE' end as 'partition'
,case when (art.schema_option & 1048576) > 0 then 'TRUE' ELSE 'FALE' end as 'partition_index'
,case when (art.schema_option & 1073741824) > 0 then 'TRUE' ELSE 'FALE' end as 'permissions'
from sysarticles as art
inner join syspublications as pub on art.pubid = pub.pubid
order by pub.pubid
'Replication' 카테고리의 다른 글
| 복제::잘못 삭제 했을 경우 (0) | 2010.03.15 |
|---|---|
| 복제::트랜잭션 복제 배포agent 실행중 상태 모니터링 (0) | 2009.12.28 |
| Error::복제 에러로그 (1) | 2009.11.23 |
| 복제::Snaphort DB 이용한 데이터 초기화. (0) | 2009.07.17 |
 Prev
Prev

