'분류 전체보기'에 해당되는 글 192건
- 2010.06.04 SQL Server의 Procedure Cache 사이즈
- 2010.06.04 Admin::Recovery Model
- 2010.06.04 Admin::master db rebuild 방법
- 2010.06.04 AGent::구성, 보안,Proxy
- 2010.06.04 Profiler
- 2010.06.04 문서화되지 않은 프로시저
- 2010.06.04 데이터베이스 사이즈
- 2010.06.04 Trace Flag
- 2010.06.04 Raid구성성능
- 2010.06.04 DB파일사이즈 1
- 2010.06.04 DBCC 명령어
- 2010.06.04 WMI Providers_2
- 2010.06.04 WMI Providers 1
- 2010.06.04 SID및ID
- 2010.06.04 Sesrvice Broker::보안
Procedure Cache
SQL 서버는 두가지 타입의 cache에 메모리를 할당한다.
1. procedure cache
2. buffer cache
procedure cache는 실행한 stored procedure의 쿼리 실행 계획이 저장되는 공간이고,
buffer cache는 디스크로부터 읽어 들인 데이터를 저장하는 공간이다.
그런데 SQL Server를 세팅하고 관리할 때 SQL Server 인스턴스에 할당할 전체 메모리의 크기는 설정할 수 있지만, 위 두가지 메모리 영역 별로 메모리를 할당 하는 방법 및 수단은 존재하지 않는다.
(심지어 두 영역에 어떤 비율이나 공식이나 방법으로 메모리가 할당되는지에 대한 문서조차 없다.)
각설하고...
SQL Server가 메모리를 할당하는 방식은... procedure cache에 할당할 메모리 크기를 서버환경으로부터 일정 공식을 사용하여 계산하여 할당하고, 나머지 공간을 buffer cache에 할당하는 방식이다.
procedure cache 크기를 계산 방법은 아래와 같다.
- 32bit 플랫폼
procedure cache는 AWE (Address Windowing Extension)영역에 존재할 수 없다.
따라서 SQL인스턴스에 할당된 메모리의 첫 2GB까지의 영역만을 사용할 수 있는데, 이 영역의 50%와 1GB 중 작은 양이 procedure cache로 할당된다.
- 64bit 플랫폼
SQL Server 2005 SP1 또는 그 이전인 경우, "SQL 인스턴스에 할당된 첫 8GB까지의 75% + 이후 56GB까지의 50% + 나머지 메모리의 25%"를 procedure cache에 할당한다.
예를 들어 시스템 메모리가 16GB이고 SQL 인스턴스에 할당된 메모리 15GB인 경우, procedure cache의 크기는 9.5GB (8GB * 0.75 + 7GB * 0.5)가 된다.
단, SQL Server 2005 SP2에서 이 계산 방식이 "SQL 인스턴스에 할당된 첫 4GB까지의 75% + 나머지 메모리의 10%"로 바뀌어, 위의 예와 같은 상황에서 procedure cache의 크기는 4.1GB (4GB * 0.75 + 11GB * 0.1)가 된다.
(출처 : http://searchsqlserver.techtarget.com/tip/0,289483,sid87_gci1316780,00.html
http://purumae.tistory.com/26)
이 글은 스프링노트에서 작성되었습니다.
'Common Admin' 카테고리의 다른 글
| SQL 2008 -New DataType-Date (0) | 2010.06.04 |
|---|---|
| SQLDMO (0) | 2010.06.04 |
| Admin::master db rebuild 방법 (0) | 2010.06.04 |
| Profiler (0) | 2010.06.04 |
-
Different Types of SQL Server Database Recovery Models
- http://www.sql-server-performance.com/articles/dba/Database_Recovery_Models_in_SQL_Server_p1.aspx
-
simple mode
- In Simple Recovery Model SQL Server logs minimal amount of information in the transaction log. SQL Server basically truncates the transaction log whenever the transaction log becomes 70 percent full or the active portion of the transaction log exceeds the size that SQL Server could recover in the amount of time which is specified in the Recovery Interval server level configuration
-
Switching Database Recovery Models
-
How to Switch Database Recovery Model
이 글은 스프링노트에서 작성되었습니다.
'Backup/Restory' 카테고리의 다른 글
| detach 한 DB를 다른 서버에서 attach 하면 log 백업 바로 가능 한가? (0) | 2013.03.13 |
|---|---|
| BACKUP compression (0) | 2010.06.04 |
| 백업성공보고 (0) | 2010.06.03 |
| All DB 백업 (0) | 2010.06.03 |
DB를 설치하고 나서 collation 을 잘 못 생성하면, 골치가 아프게 됩니다. 이미 서비스이전이면 다시 설치하면 되겠지만
그렇지 못한 사정일 때 master을 rebuild 하게 되면 model이랑 tempdb의 collation도 바뀌게 됩니다.
예전에 시도해봤었는데 그대는 이번 처럼 체계적인 설명이 없었습니다. 단일모드로 접속해서 master db를 리빌드 하는 명령을 해봤지만 에러가 발생하고 적용이 되지 않더군요.
왠지 이번건 체계적인 것 같네요. 그때는 msdn의 support 였는데.
Part1 : http://www.mssqltips.com/tip.asp?tip=1531 : 하기 전 사전 작업입니다.
- 각 DB의 Attach, Detach 스크립트를 쉽게 만들 수 있고
- 사용자의 로그인 정보를 한번에 만들어 주네요. – 장비 이전 시 사용하면 좋을 것 같습니다.
n http://support.microsoft.com/kb/918992 : 여기서 필요한 프로시저를 master에 생성하고 exec dbo.sp_help_revlogin 이용
part 2: http://www.mssqltips.com/tip.asp?tip=1528 : master를 리빌드 하는 명령어와 방법, 리빌드 후 백업 해야 하는 점
part 3: http://www.mssqltips.com/tip.asp?tip=1533 : 하고 나서 part1에서 생성된 자료를 실행합니다.
이 글은 스프링노트에서 작성되었습니다.
'Common Admin' 카테고리의 다른 글
| SQLDMO (0) | 2010.06.04 |
|---|---|
| SQL Server의 Procedure Cache 사이즈 (0) | 2010.06.04 |
| Profiler (0) | 2010.06.04 |
| 문서화되지 않은 프로시저 (0) | 2010.06.04 |
SQL Server 에이전트 구성
SQL Server 에이전트는 msdb 데이터베이스에 있는 테이블에 대부분의 구성 정보를 저장합니다. SQL Server 에이전트는 SQL Server 자격 증명 개체를 사용하여 프록시의 인증 정보를 저장합니다.
이 기능을 수행하려면 SQL Server에서 sysadmin 고정 서버 역할 멤버인 계정의 자격 증명을 사용하도록 SQL Server 에이전트를 구성해야 합니다.
작업
작업은 SQL Server 에이전트에서 수행하도록 지정된 일련의 동작입니다.
작업을 사용하면 한 번 이상 실행되고 성공과 실패에 대해 모니터링될 수 있는 관리 작업을 정의할 수 있습니다. 작업은 한 대의 로컬 서버나 다중 원격 서버에서 실행될 수 있습니다.
각 작업 단계는 특정 보안 컨텍스트에서 실행됩니다. Transact-SQL 을 사용하는 작업 단계의 경우 EXECUTE AS 문을 사용하여 해당 작업 단계에 대한 보안 컨텍스트를 설정합니다. 다른 작업 단계 유형의 경우에는 프록시 계정을 사용하여 해당 작업 단계에 대한 보안 컨텍스트를 설정합니다.
SQL Server 에이전트 관리 보안
SQL Server 에이전트는 msdb 데이터베이스에서 sysadmin 고정 서버 역할의 멤버가 아닌 사용자의 SQL Server 에이전트에 대한 액세스를 제어하는 SQLAgentUserRole, SQLAgentReaderRole 및 SQLAgentOperatorRole 고정 데이터베이스 역할을 제공합니다. 이러한 고정 데이터베이스 역할 외에도 데이터베이스 관리자는 하위 시스템과 프록시를 사용하여 각 작업 단계가 작업 수행에 필요한 최소 권한으로 실행되도록 합니다.
-
역활
- msdb의 SQLAgentUserRole, SQLAgentReaderRole 및 SQLAgentOperatorRole 고정 데이터베이스 역할 멤버와 sysadmin 고정 서버 역할 멤버는 SQL Server 에이전트에 액세스할 수 있습니다.
-
하위 시스템 = SQL Agent Subsystems
- 하위 시스템은 작업 단계에서 사용할 수 있는 기능을 나타내는 미리 정의된 개체입니다.
- 전체 작업이 실행할 수 있는 권한이 있다고 해도 하위 시스템의 설정된 프록시로 실행할 수 없으면 실행 불가능하다.
-
Proxy
- SQL Server 에이전트는 프록시를 사용하여 보안 컨텍스트를 관리할 수 있습니다. 프록시는 둘 이상의 작업 단계에서 사용할 수 있습니다. sysadmin 고정 서버 역할의 멤버는 프록시를 만들 수 있습니다.
- 각 프록시는 보안 자격 증명에 해당됩니다.
- 각 프록시는 하위 시스템 집합 및 로그인 집합과 연결할 수 있으며 프록시는 해당 프록시와 연결된 하위 시스템을 사용하는 작업 단계에서만 사용할 수 있습니다.
-
SQL Server 에이전트 구현에 대한 보안을 향상시키려면 다음 지침을 따르십시오.
- 프록시에 대한 전용 사용자 계정을 만들고 이러한 프록시 사용자 계정만 사용하여 작업 단계를 실행합니다.
- 프록시 사용자 계정에 필요한 사용 권한만 부여합니다. 특정 프록시 계정에 할당된 작업 단계를 실행하는 데 실제로 필요한 사용 권한만 부여합니다.
- Windows Administrators 그룹의 멤버인 Microsoft Windows 계정을 사용하여 SQL Server 에이전트 서비스를 실행하지 않습니다.
Proxy 만들기
Microsoft Windows 사용자의 보안 자격 증명에 대한 액세스 권한을 SQL Server 에이전트에 제공합니다. 각 프록시는 하나 이상의 하위 시스템과 연결될 수 있습니다. 프록시를 사용하는 작업 단계에서는 Windows 사용자의 보안 컨텍스트를 사용하여 지정된 하위 시스템에 액세스할 수 있습니다.
SQL Server 에이전트가 프록시를 사용하는 작업 단계를 실행하기 전에 SQL Server 에이전트는 프록시에 정의되어 있는 자격 증명을 가장한 다음 해당 보안 컨텍스트를 사용하여 작업 단계를 실행합니다.
QL Server 에이전트 프록시는 자격 증명을 사용하여 Windows 사용자 계정에 대한 정보를 저장합니다. 자격 증명에 지정된 사용자에게 SQL Server가 실행 중인 컴퓨터에 대한 "일괄 작업으로 로그온" 권한이 있어야 합니다.
작업 단계에서 프록시를 사용하려면 사용자에게 프록시에 액세스할 수 있는 권한이 있어야 합니다. 다음과 같은 3가지 유형의 보안 주체에 액세스 권한을 부여할 수 있습니다.
- SQL Server 로그인
- 서버 역할
- msdb 데이터베이스 내의 역할
-
USE MASTER
go
-
-- 생성하기 window 유저를 생성해야한다.
CREATE CREDENTIAL sqlagent WITH IDENTITY = '장비명\sqlagent', SECRET = '암호';
SELECT * FROM SYS.CREDENTIALS;
USE [msdb]
GO
EXEC msdb.dbo.sp_add_proxy @proxy_name=N'SQL_Agent_Proxy',@credential_name=N'sqlagent',
@enabled=1,
@description=N'SQL Agent 를위한Proxy 설정TEST'
GO
EXEC msdb.dbo.sp_grant_proxy_to_subsystem @proxy_name=N'SQL_Agent_Proxy', @subsystem_id=2
GO
EXEC msdb.dbo.sp_grant_proxy_to_subsystem @proxy_name=N'SQL_Agent_Proxy', @subsystem_id=3
GO
-- 보안주체를설정해준다. 읽기밖에되지않은일반로그인계정
EXEC msdb.dbo.sp_grant_login_to_proxy @proxy_name=N'SQL_Agent_Proxy', @login_name=N'dev'
GO
-
[작업을 생성 해본다.]
-
-
해당 내역을 실행할 수 없는 dev 계정으로 JOB을 실행해 보았을 경우 실패한다. 윈도우 계정의 권한이 없으며, 최고 권한이 sysadmin도 아니기 때문이다. Proxy 를 기본으로 사용하고 있기에 실행할 수 없다.
Non-SysAdmins have been denied permission to run CmdExec job steps without a proxy account. The step failed.
-
작업 명령은 del c:\test_proxy.txt 로 해야 한다. 운영체제 명령인데 잘 못 적었음. ^________^
-
윈도우 자격증명을 매핑한 Proxy로 실행하게 변경 한다.
-
결과)
Unable to start execution of step 1 (reason: Error authenticating proxy 도메인\계정, system error: The referenced account is currently locked out and may not be logged on to.). The step failed.
-
발생한다. 이유인즉, job의 dev 소유자는 작업을 실행할 수 있는 권한이 없다. 즉, SQL 로그인 계정이 msdb에 접근해서 job을 실행할 수 있는 권한이 소유해야 하며, 이 소유자가 운영체제의 로그인 계정이 아니고 SQL 계정임에도 불구하고 윈도우 계정을 Proxy를 만들어서 자격증명을 만들었기 때문에 파일 삭제는 이루어 진다. SQL 계정을 윈도우 계정으로 연결해준 격이 된다.
이 글은 스프링노트에서 작성되었습니다.
'SQL Agent' 카테고리의 다른 글
| syspolicy_purge_history JOB 실패 (0) | 2011.01.11 |
|---|
Profiler
- 서버 및 데이터베이스 동작 모니터, 교착상태수, 치명적인 오류, 저자으로시저 및 Transact-SQL 문 추적, 로그인 동작 확인
- SQL 프로필러 데이터를 SQL Server 테이블이나 파일에 캡처해서 분석가능
- 캡처한 이벤트를 단계별로 재성
- SQL 프로필러는 일괄처리나 트랜잭션 시작과 같은 엔진 프로세스 이벤트를 추적할 수 있다.
템플릿
- 나만의 템플릿을 만들어서 필요한 부분만 보자.
- 이벤트 에서는 보안 감사/세션 정보는 제외해도 무관
- 경고>> Execution Warnigs 는 성능에 나쁜 영향을 줄때 프로시저 내에서 발생하는 모든 에러를 반환한다. 한번씩 잡아 보는것도 괜찮다.
- 기본1.tdf : 기본에 충실한 추적 템플릿
이벤트 범주
- 저장프로시저 범주 : 저장프로시저 생성으로 발생하는 이벤트 컬랙션
- 이벤트 클래스와 열의 상관 관계, 해당 이벤트를 가져와야 특정 정보가 발생한다.

- TSQL: 클라이언트로부터 SQL Server 인스턴스로 전달되는 Transact-SQL 문을 실행함으로 생성되는 이벤트 클래스 컬렉션입니다.

- 참고) 둘다 Batch가 아니라 단건을 해야 NestLevel, ObejctID를 가져올 수 있다. 이게 Read80Trace에서 있어야 분석이 가능한것 같음.
- 잠금: 잠금을 얻거나 취소, 해제 시 생성되는 이벤트 클래스의 컬렉션입니다.
- 잠금은 자주 발생하기 때문에 잠금 이벤트를 캡쳐하면 추적되는 서비스에 중대한 오버해드를 발생 할 수 있다.

Profiler 바로가기 키
| Ctrl+Shift+Delete | 추적 창 지우기 |
| Ctrl+F4 | 추적 창 닫기 |
| - | 추적 그룹화 축소 |
| Ctrl+C | 복사 |
| Alt+Delete | 추적 삭제 |
| + | 추적 그룹화 확장 |
| Ctrl+F | 찾기 |
| F3 | 다음 항목 찾기 |
| Shift+F3 | 이전 항목 찾기 |
| F1 | 사용 가능한 도움말 표시 |
| Ctrl+N | 새 추적 열기 |
| Alt+F7 | 설정 재생 |
| Ctrl+F10 | 커서까지 실행 |
| F5 | 재생 시작 |
| F11 | 단계 |
| Shift+F5 | 재생 중지 |
| F9 | 중단점 설정/해제 |
파일/테이블 저장
추적파일을 테이블에 저장할 수 있다. 파일로 저장해서 쿼리로 문제가 되는 부분을 필터링해서 개체를 찾는데 도움이 된다.
select * from ::fn_trace_gettable('D:\gettable_test.trc',default)
SELECT IDENTITY(int, 1, 1) AS RowNumber, * INTO #temp_trc
FROM ::fn_trace_gettable('D:\gettable_test.trc', default)
SELECT * FROM #temp_trc
- 분석하기
ALTER TABLE #temp_trc ADD sql varchar(6000) : TextData는 text 타입이므로 정렬에 사용할 수 없으므로 변경
UPDATE #temp_trc SET sql = convert(varchar(6000), TextData)
select convert(varchar(80), sql), count(*) 횟수, avg(duration) dr, avg(cpu) c, avg(reads) r, avg(writes ) w
from #temp_trc
group by convert(varchar(80), sql)
order by count(*) desc
Profiler 스크립트로 실행하기
- 프로필러를 스크립트로 실행할 수 있다. UI로 실행하게 되면 아무래도 부하가 걸린다.
- 필요한 이벤트, 컬럼을 지정해서 가능하다. 쉽게 하기 위해서는 자주 쓰는 템플릿을 불러와서 파일>>추적스크립트를 실행해서 변환을 하면 스크립트가 생성된다.
- 추적은 다음과 같은 순서로 실행하면 된다.
- sp_trace_create: Trace를 생성한다.
- sp_trace_setevent: 해당 Trace에 이벤트와 컬럼 명을 지정한다.
- sp_trace_setfilter: 필터를 지정해서 원하는 값만 볼수 있다.
- 추적이 실행되고 나서 상태확인/중지
- fn_trace_getfilterinfo : TraceId 정보를 확인할 수 있음
- sp_trace_status @TraceId, 0 : 추적중지 -> sp_trace_status @TraceId, 2 : 추적 삭제
- 스크립트 저장프로시저로 만들기
이 글은 스프링노트에서 작성되었습니다.
'Common Admin' 카테고리의 다른 글
| SQL Server의 Procedure Cache 사이즈 (0) | 2010.06.04 |
|---|---|
| Admin::master db rebuild 방법 (0) | 2010.06.04 |
| 문서화되지 않은 프로시저 (0) | 2010.06.04 |
| Raid구성성능 (0) | 2010.06.04 |
sp_MSforeachtable
Overview
Microsoft provides two undocumented Stored Procedures that allow you to process through all tables in a database, or all databases in a SQL Server instance. The first Stored Procedure (SP), "sp_MSforeachtable," allows you to easily process some code against every table in a single database. The other SP, "sp_MSforeachdb," will execute a T-SQL statement against every database associated with the current SQL Server instance. Let me go through each of these Stored Procedures in a little more detail.
sp_MSforeachtable
The "sp_MSforeachtable" SP comes with SQL Server, but it is not documented in Books Online. This SP can be found in the "master" database and is used to process a single T-SQL command or a number of different T-SQL commands against every table in a given database. To demonstrate how this SP works and how I think it is simpler to use then coding a CURSOR let me go through an example.
Say I want to build a temporary table that will contain a series of records; one for each table in the database and where each row contains the table name and the row count for the given table. To do this you would want to run a command like, "select '<mytable>', count(*) from <mytable>" where "<mytable>" was replaced with every table in your database and insert the results into my temporary table. So now, let's look at how we might do this using a CURSOR and then using the undocumented SP "sp_MSforeachtable".
Here is my code for getting the row counts for each table in a database using a CURSOR:
use pubs
go
set nocount on
declare @cnt int
declare @table varchar(128)
declare @cmd varchar(500)
create table #rowcount (tablename varchar(128), rowcnt int)
declare tables cursor for
select table_name from information_schema.tables
where table_type = 'base table'
open tables
fetch next from tables into @table
while @@fetch_status = 0
begin
set @cmd = 'select ''' + @table + ''', count(*) from ' + @table
insert into #rowcount exec (@cmd)
fetch next from tables into @table
end
CLOSE tables
DEALLOCATE tables
select top 5 * from #rowcount
order by tablename
drop table #rowcount
Here is the output of my CURSOR example when the above code in run on my machine:
tablename rowcnt ------------- ----------- authors 23 discounts 3 employee 43 jobs 8 pub_info 8
Now here is my code that produces similar results using the undocumented SP "sp_MSforeachtable":
use pubs
go
create table #rowcount (tablename varchar(128), rowcnt int)
exec sp_MSforeachtable
'insert into #rowcount select ''?'', count(*) from ?'
select top 5 * from #rowcount
order by tablename
drop table #rowcount
Here is the output from the above code when run on my machine:
tablename rowcnt ----------------- ----------- [dbo].[authors] 23 [dbo].[discounts 3 [dbo].[employee] 43 [dbo].[jobs] 14 [dbo].[pub_info] 8
As you can see both the CURSOR example and the "sp_MSforeachtable" code produce relatively the same results. Which one do you think is easier to read and code? Let's look a little closer at how to use the undocumented SP "sp_MSforeachtable".
Below is the syntax for calling the sp_MSforeachtable SP:
exec @RETURN_VALUE=sp_MSforeachtable @command1, @replacechar, @command2, @command3, @whereand, @precommand, @postcommand
Where:
- @RETURN_VALUE - is the return value which will be set by "sp_MSforeachtable"
- @command1 - is the first command to be executed by "sp_MSforeachtable" and is defined as a nvarchar(2000)
- @replacechar - is a character in the command string that will be replaced with the table name being processed (default replacechar is a "?")
- @command2 and @command3 are two additional commands that can be run for each table, where @command2 runs after @command1, and @command3 will be run after @command2
- @whereand - this parameter can be used to add additional constraints to help identify the rows in the sysobjects table that will be selected, this parameter is also a nvarchar(2000)
- @precommand - is a nvarchar(2000) parameter that specifies a command to be run prior to processing any table
- @postcommand - is also a nvarchar(2000) field used to identify a command to be run after all commands have been processed against all tables
As you can see, there are quite a few options for the "sp_MSforeachtable" SP. Let's go through a couple of different examples to explore how this SP can be used to process commands against all the tables, or only a select set of tables in a database.
First let's build on our original example above and return row counts for tables that have a name that start with a "p." To do this we are going to use the @whereand parameter. Here is the code for this example:
use pubs
go
create table #rowcount (tablename varchar(128), rowcnt int)
exec sp_MSforeachtable
@command1 = 'insert into #rowcount select ''?'',
count(*) from ?',
@whereand = 'and name like ''p%'''
select top 5 * from #rowcount
order by tablename
drop table #rowcount
On my machine, the above code produced the following output:
tablename rowcnt ------------------ ----------- [dbo].[pub_info] 8 [dbo].[publishers] 8
By reviewing the code above, you can see I am now using the @command1, and the @whereand parameter. The @whereand parameter above was used to constrain the WHERE clause and only select tables that have a table name that starts with a "p." To do this I specified "and name like ''p%''" for the @whereand parameter. If you needed to have multiple constraints like all tables that start with "p," and all the tables that start with "a," then the @whereand parameter would look like this:
and name like ''p%'' or name like ''a%''
Note, that in the @command1 string in the above example there is a "?". This "?" is the default replacement character for the table name. Now if for some reason you need to use the "?" as part of your command string then you would need to use the @replacechar parameter to specify a different replacement character. Here is another example that builds on the above example and uses the "{" as the replacement character:
create table #rowcount (tablename varchar(128), rowcnt int)
exec sp_MSforeachtable
@command1 = 'insert into #rowcount select
''Is the rowcount for table {?'',
count(*) from {',
@replacechar = '{',
@whereand = 'and name like ''p%'''
select tablename as question, rowcnt from #rowcount
order by tablename
drop table #rowcount
Here is the output from this command on my machine:
question rowcnt ------------------------------------------------ ----------- Is the rowcount for table [dbo].[pub_info]? 8 Is the rowcount for table [dbo].[publishers]? 8
There are two more parameters to discuss, @percommand, and @postcommand. Here is an example that uses both of these commands:
exec sp_MSforeachtable @command1 = 'print ''Processing table ?''', @whereand = 'and name like ''p%''', @precommand = 'Print ''precommand execution '' ', @postcommand = 'Print ''postcommand execution '' '
Here is the output from this command when run on my machine:
precommand execution Processing table [dbo].[pub_info] Processing table [dbo].[publishers] postcommand execution
As you can see, the "PRINT" T-SQL command associated with the "@precommand" parameter was only executed once, prior to processing through the tables. Whereas, the "@postcommmand" statement was executed after all the tables where processed, and was only executed once. Using the pre and post parameters would be useful if I had some processing I wanted done prior to running a command against eachnly executed once. clause and table, and/or I needed to do some logic after all tables where processed.
sp_MSforeachdb
The SP "sp_MSforeachdb" is found in the "master" database. This SP is used to execute a single T-SQL statement, like "DBCC CHECKDB" or a number of T-SQL statements against every database defined to a SQL Server instance. Here is the syntax for calling this undocumented SP:
exec @RETURN_VALUE = sp_MSforeachdb @command1, @replacechar, @command2, @command3, @precommand, @postcommand
Where:
- @RETURN_VALUE - is the return value which will be set by "sp_MSforeachdb"
- @command1 - is the first command to be executed by "sp_MSforeachdb" and is defined as nvarchar(2000)
- @replacechar - is a character in the command string that will be replaced with the table name being processed (default replacechar is a "?")
- @command2 and @command3 are two additional commands that can be run against each database
- @precommand - is a nvarchar(2000) parameter that specifies a command to be run prior to processing any database
- @postcommand - is also an nvarchar(2000) field used to identify a command to be run after all commands have been processed against all databases.
The parameters for sp_MSforeachdb are very similar to sp_MSforeachtable. Therefore, there is no need to go over some of the parameters since they provide the same functionality as I described in the sp_MSforeachtable section above.
To show you how the "sp_MSforeachdb" SP works let me go through a fairly simple example. This example will perform a database backup, then a "DBCC CHECKDB" against each database. Here is the code to perform this:
declare @cmd1 varchar(500)
declare @cmd2 varchar(500)
declare @cmd3 varchar(500)
set @cmd1 =
'if ''?'' <> ''tempdb'' print ''*** Processing DB ? ***'''
set @cmd2 = 'if ''?'' <> ''tempdb'' backup database ? to disk=''c:\temp\?.bak'''
set @cmd3 = 'if ''?'' <> ''tempdb'' dbcc checkdb(?)'
exec sp_MSforeachdb @command1=@cmd1,
@command2=@cmd2,
@command3=@cmd3
Here you can see that I am really processing three different commands. The first command is just a "PRINT" statement so you can easily review the output by database. Remember how "sp_MSforeachtable" SP had a parameter where you could constrain what tables where processed, there is no parameter that provides this type of functionality in the "sp_MSforeachdb" SP. Since SQL Server does not allow the "tempdb" database to be backed up I needed a way to skip that database. This is why I have used the "IF" statement in each of the commands I processed. The second command (@command2) processes the databases backup, and the last command (@command3) will run a "DBCC CHECKDB" command against all databases except the "tempdb" database.
Comments on Using Undocumented SQL Server Stored Procedures
Some level of testing and care should be taken when using undocumented code from Microsoft. Since these SP's are not documented, it means that Microsoft might change this code with any new release or patch without notifying customers. Because of this, you need to thoroughly test any code you write that uses these undocumented SPs against all new releases of SQL Server. This testing should verify that your code still functions as it did in old releases.
Conclusion
As you can see, these undocumented Stored Procedures are much easier to use than using a CURSOR. Next time you need to iteratively run the same code against all tables, or all databases consider using these undocumented Stored Procedures. Although, remember these Stored Procedures are undocumented and therefore Microsoft may change their functionality at anytime.
이 글은 스프링노트에서 작성되었습니다.
'Common Admin' 카테고리의 다른 글
| Admin::master db rebuild 방법 (0) | 2010.06.04 |
|---|---|
| Profiler (0) | 2010.06.04 |
| Raid구성성능 (0) | 2010.06.04 |
| DB파일사이즈 (1) | 2010.06.04 |
데이터베이스 사이즈 측정
- DB파일사이즈
- Estimating the size of Table
-
(Heap 사이즈 혹은 클러스터 인덱스 사이즈) + 넌 클러스터 인덱스 사이즈의 합
-
사이즈 계산법으로 말고 sp_spaceused 에 datasize와 인덱스 사이즈를 보고 테이블 전체 사이즈를 아는것과 다른가?
-
sp_spaceused 프로시저 확인해 보기 : 확인해 보니 복잡하지 않고 윗 부분과 동일한 것 같음
- --=====================================================
- - 테이블 사이즈
-
--======================================================
-
SELECT
-
@reservedpages = SUM (reserved_page_count),
-
@usedpages = SUM (used_page_count),
-
@pages = SUM (
-
CASE
-
WHEN (index_id < 2) THEN (in_row_data_page_count + lob_used_page_count + row_overflow_used_page_count)
-
ELSE lob_used_page_count + row_overflow_used_page_count
-
END
-
),
-
@rowCount = SUM (
-
CASE
-
WHEN (index_id < 2) THEN row_count
-
ELSE 0
-
END
-
)
-
FROM sys.dm_db_partition_stats
-
WHERE object_id = @id;
-
-
SELECT
-
name = OBJECT_NAME (@id),
-
rows = convert (char(11), @rowCount),
-
reserved = LTRIM (STR (@reservedpages * 8, 15, 0) + ' KB'),
-
data = LTRIM (STR (@pages * 8, 15, 0) + ' KB'),
-
index_size = LTRIM (STR ((CASE WHEN @usedpages > @pages THEN (@usedpages - @pages) ELSE 0 END) * 8, 15, 0) + ' KB'),
-
unused = LTRIM (STR ((CASE WHEN @reservedpages > @usedpages THEN (@reservedpages - @usedpages) ELSE 0 END) * 8, 15, 0) + ' KB')
-
-
이 글은 스프링노트에서 작성되었습니다.
'T-SQL' 카테고리의 다른 글
| Index::Defrag Script v4.0 (0) | 2010.06.15 |
|---|---|
| T_SQL::미 사용 Table (0) | 2010.06.15 |
| T-SQL::Removing Duplication Data (1) | 2010.06.03 |
| T-SQL::DB_Restore_move_to (0) | 2010.06.03 |
Trace Flag
사용법
- DBCC TRACESTATUS(-1) -- 현재 사용된 Flag
- DBCC TRACEON (번호, -1) -- 전역으로 설정
- DBCC TRACEOFF(번호, -1 ) -- flag 제거
- 시작 옵션에 -T번호를 주어도 됨
- Sqlservr.exe –c –m –T3609 –T4022
Flag 정리
| Sets trace flags for all client connections, rather than for a single client connection. Because trace flags set using the -T command-line option automatically apply to all connections, this trace flag is used only when setting trace flags using DBCC TRACEON and DBCC TRACEOFF. | |
| 106 | Disables line number information for syntax errors. |
| 107 | Interprets numbers with a decimal point as float instead of decimal. |
| 205 | Report when a statistics-dependent stored procedure is being recompiled as a result of AutoStat. |
| 206 | Provides backward compatibility for the setuser statement. |
| 208 | SET QUOTED IDENTIFIER ON. |
| 242 | Provides backward compatibility for correlated subqueries where non-ANSI-standard results are desired. |
| 243 | The behavior of SQL Server is now more consistent because nullability checks are made at run time and a nullability violation results in the command terminating and the batch or transaction process continuing. |
| 244 | Disables checking for allowed interim constraint violations. By default, SQL Server checks for and allows interim constraint violations. An interim constraint violation is caused by a change that removes the violation such that the constraint is met, all within a single statement and transaction. SQL Server checks for interim constraint violations for self-referencing DELETE statements, INSERT, and multirow UPDATE statements. This checking requires more work tables. With this trace flag you can disallow interim constraint violations, thus requiring fewer work tables. |
| 257 | Will invoke a print algorithm on the XML output before returning it to make the XML result more readable. |
| 260 | Prints the versioning information about extended stored procedure dlls. |
| 302 | Prints information about whether the statistics page is used, the actual selectivity (if available), and what SQL Server estimated the physical and logical I/O would be for the indexes. Trace flag 302 should be used with trace flag 310 to show the actual join ordering. |
| 310 | Prints information about join order. Index selection information is also available in a more readable format using SET SHOWPLAN_ALL, as described in the SET statement. |
| 325 | Prints information about the cost of using a nonclustered index or a sort to process an ORDER BY clause. |
| 326 | Prints information about the estimated and actual cost of sorts. |
| 330 | Enables full output when using the SET SHOWPLAN_ALL option, which gives detailed information about joins. |
| 506 | Enforces SQL-92 standards regarding null values for comparisons between variables and parameters. Any comparison of variables and parameters that contain a NULL always results in a NULL. |
| 652 | Disables read ahead for the server. |
| 653 | Disables read ahead for the current connection. |
| 809 | Limits the amount of Lazy Write activity in SQL Server 2000. |
| 1118 | tempdb 경합을 줄이기 위함 |
| 1180 | Forces allocation to use free pages for text or image data and maintain efficiency of storage. |
| 1200 | Prints lock information (the process ID and type of lock requested). |
| 1204 | Returns the type of lock participating in the deadlock and the current command affect by the deadlock. |
| 1205 | Returns more detailed information about the command being executed at the time of a deadlock. |
| 1206 | Used to complement flag 1204 by displaying other locks held by deadlock parties |
| 1609 | Turns on the unpacking and checking of remote procedure call (RPC) information in Open Data Services. Used only when applications depend on the old behavior. |
| 1704 | Prints information when a temporary table is created or dropped. |
| 1807 | Allows you to configure SQL Server with network-based database files. |
| 2505 | Prevents DBCC TRACEON 208, SPID 10 errors from appearing in the error log. |
| 2508 | Disables parallel non-clustered index checking for DBCC CHECKTABLE. |
| 2509 | Used with DBCC CHECKTABLE.html to see the total count of ghost records in a table |
| 2528 | Disables parallel checking of objects by DBCC commands. |
| 2701 | Sets the @@ERROR system function to 50000 for RAISERROR messages with severity levels of 10 or less. When disabled, sets the @@ERROR system function to 0 for RAISERROR messages with severity levels of 10 or less. |
| 3104 | Causes SQL Server to bypass checking for free space. |
| 3111 | Cause LogMgr::ValidateBackedupBlock to be skipped during backup and restore operations. |
| 3205 | Disables hardware compression for tape drivers. |
| 3222 | Disables the read ahead that is used by the recovery operation during roll forward operations. |
| 3502 | Prints a message to the log at the start and end of each checkpoint. |
| 3503 | Indicates whether the checkpoint at the end of automatic recovery was skipped for a database (this applies only to read-only databases). |
| 3602 | Records all error and warning messages sent to the client. |
| 3604 | Sends trace output to the client. Used only when setting trace flags with DBCC TRACEON and DBCC TRACEOFF. |
| 3605 | Sends trace output to the error log. (If you start SQL Server from the command prompt, the output also appears on the screen.) |
| 3607 | Skips automatic recovery (at startup) for all databases. |
| 3608 | Skips automatic recovery (at startup) for all databases except the master database. |
| 3609 | Skips the creation of the tempdb database at startup. Use this trace flag if the device or devices on which tempdb resides are problematic or problems exist in the model database. |
| 3626 | Turns on tracking of the CPU data for the sysprocesses table. |
| 3640 | Eliminates the sending of DONE_IN_PROC messages to the client for each statement in a stored procedure. This is similar to the session setting of SET NOCOUNT ON, but when set as a trace flag, every client session is handled this way. |
| 4022 | Bypasses automatically started procedures. |
| 4030 | Prints both a byte and ASCII representation of the receive buffer. Used when you want to see what queries a client is sending to SQL Server. You can use this trace flag if you experience a protection violation and want to determine which statement caused it. Typically, you can set this flag globally or use SQL Server Enterprise Manager. You can also use DBCC INPUTBUFFER. |
| 4031 | Prints both a byte and ASCII representation of the send buffers (what SQL Server sends back to the client). You can also use DBCC OUTPUTBUFFER. |
| 4032 | Traces the SQL commands coming in from the client. The output destination of the trace flag is controlled with the 3605/3604 trace flags. |
| 7300 | Retrieves extended information about any error you encounter when you execute a distributed query. |
| 7501 | Dynamic cursors are used by default on forward-only cursors. Dynamic cursors are faster than in earlier versions and no longer require unique indexes. This flag disables the dynamic cursor enhancements and reverts to version 6.0 behavior. |
| 7502 | Disables the caching of cursor plans for extended stored procedures. |
| 7505 | Enables version 6.x handling of return codes when calling dbcursorfetchex and the resulting cursor position follows the end of the cursor result set. |
| 7525 | Reverts to the SQL Server 7.0 behavior of closing nonstatic cursors regardless of the SET CURSOR_CLOSE_ON_COMMIT state in SQL Server 2000. |
| 8033 | Trace flag –T8033 can be used to suppress the drift warnings. |
| 8202 | Replicates all UPDATE commands as DELETE/INSERT pairs at the publisher. |
| 8206 | Supports stored procedure execution with a user specified owner name for SQL Server subscribers or without owner qualification for heterogeneous subscribers in SQL Server 2000. |
| 8207 | Enables singleton updates for Transactional Replication, released with SQL Server 2000 Service Pack 1. |
| 8599 | Allows you to use a savepoint within a distributed transaction. |
| 8679 | Prevents the SQL Server optimizer from using a Hash Match Team operator. |
| 8687 | Used to disable query parallelism. |
| 8721 | Dumps information into the error log when AutoStat has been run. |
| 8783 | Allows DELETE, INSERT, and UPDATE statements to honor the SET ROWCOUNT ON setting when enabled. |
| 8816 | Logs every two-digit year conversion to a four-digit year. |
이 글은 스프링노트에서 작성되었습니다.
'Trace Flag' 카테고리의 다른 글
| 최소로그 Flag -T610 (0) | 2011.10.13 |
|---|---|
| Admin::SQL Server Trace Flags (0) | 2010.06.07 |
| Admin::TF 1118 사용 이유 (0) | 2009.11.04 |
Riad 구성에 따른 성능 차이
CREATE TABLE TestA (a int, b int)
GO
DECLARE @time DATETIME, @i INT
SET @i = 1
SET @time = GETDATE()
WHILE 10000 >= @i
BEGIN
INSERT TestA (a, b) VALUES (@i, @i)
SET @i = @i + 1
END
SELECT DATEDIFF(ms, @time, GETDATE())
|
디스크구성<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" /?> |
Insert 건수 |
ms |
건수/초 |
비고 |
|
Raid 1 트랜젝선로그와 데이터 파일 물리적으로 함께 사용 |
10,000 |
65,610 |
153 |
현재 개발망 장비와 이와 같은 구성임 |
|
No Raid, 트랜젝선로그와 데이터 파일 물리적으로 함께 사용 |
10,000 |
2,440 |
4,098 |
개인 로컬 장비와 동일 |
|
Raid 1 + 0 트랜젝션 로그와 데이터 파일 물리적으로 분리 |
10,000 |
9,420 |
1,062 |
|
|
Raid 1 + 0 트랜젝션 로그와 데이터 파일 물리적으로 함께 사용 |
10,000 |
47,120 |
212 |
|
결과
결과를 보면, 레이드 구성은 하지 않는 것이 성능은 가장 좋습니다. 허나, 실제로는 레이드 구성을 하고 있고,
레이드 구성을 했을 경우에 적어도 트랜잭션 로그와 데이터 파일이 물리적으로 분리되어야 합니다. 부하테스트를 주고 있는 개발망 장비는 그렇지 못해서 정상적인 성능 테스트 결과를 얻을 수가 없습니다. 현재, 서비스망은 트랜잭션 로그와 데이터 파일이 분리되어 있습니다. (별차이가 없을 줄 알았는데 차이 많이 나네요.)
예를 들면) 개발망에 창고 차감의 경우 초당 50회 정도(insert/update 평균 3회) 나오는데 반해
트랜젝션 로그와 데이터 파일이 분리되어 있는 DB 장비의 경우에는 이론상으로 초당 300회가 가능한 것으로 보입니다.
이 글은 스프링노트에서 작성되었습니다.
'Common Admin' 카테고리의 다른 글
| Profiler (0) | 2010.06.04 |
|---|---|
| 문서화되지 않은 프로시저 (0) | 2010.06.04 |
| DB파일사이즈 (1) | 2010.06.04 |
| DBCC 명령어 (0) | 2010.06.04 |
Collecting database usage information for free space and trending
I find it important in my environment to monitor the following database/database file level metrics:
- Server/Instance Name
- Database Name
- Database File Names (both logical and full physical path)
- File Size (In Megabytes)
- Database Status
- Recovery Mode
- Free Space (In Megabytes and Percent)
To collect this information I need to tap into the either the master.dbo.sysfiles system table in SQL 2000 or master.sys.sysfiles compatibility view in SQL 2005. I also need to make use of a few T-SQL functions at the DBA's disposal. First, let me present the query. Afterwards I'll explain the finer points.
|
CAST(sysfiles.size/128.0 - CAST(FILEPROPERTY(sysfiles.name, ' + '''' + 'SpaceUsed' + '''' + ' ) AS int)/128.0 AS int) AS FreeSpaceMB
The FreeSpaceMB calculation is simple once you understand what I explained above for the calculations associated with FileSize. To determine free space we need to know how much of the total file space is being consumed. This information is exposed via the FILEPROPERTY() function. FILEPROPERTY() expects the following parameters: file name, and property.
Expect a future tip on the various uses for FILEPROPERTY(), but for now we focus on the SpaceUsed property. This value is also stored in 8Kb pages, so the factor of 1024/8 (or 128) remains constant. Using the same basic rules we discussed above this is what the formula would look like this: Available Space in Mb = (File Size in Mb) - (Space Used in Mb). The formula in the query casts all variables as integer data types and converts the available values from pages to Mb.
I know that one of the major foundations of database normalization is not storing calculated values in a database. However, I like to be able to trend my metadata over time and with the complexity of the formulas I prefer to do all my thinking up-front. That being said, I don't just store the size information in the table and run calculations in my queries after the fact - I do my calculations directly in the query that populates the repository.
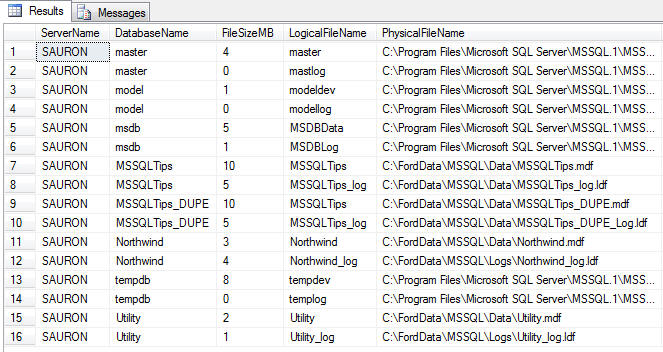
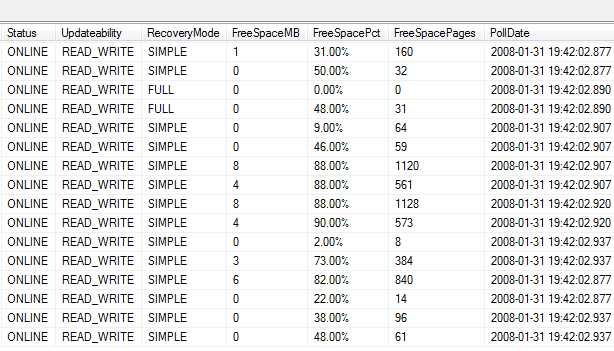
이 글은 스프링노트에서 작성되었습니다.
'Common Admin' 카테고리의 다른 글
| 문서화되지 않은 프로시저 (0) | 2010.06.04 |
|---|---|
| Raid구성성능 (0) | 2010.06.04 |
| DBCC 명령어 (0) | 2010.06.04 |
| WMI Providers_2 (0) | 2010.06.04 |
DBCC 명령어, 문서와 되어 있거나 되어있지 않은것 정리
DBCC MEMORYSTATUS
Lists a breakdown of how the SQL Server buffer cache is divided up, including buffer activity. Undocumented command, and one that may be dropped in future versions of SQL Server.
참고 자료 : http://support.microsoft.com/kb/271624
DBCC PROCCACHE
프로시저 캐시에 대한 정보를 테이블 형식으로 표시합니다.
| 열 이름 | 설명 |
|---|---|
| num proc buffs | 프로시저 캐시에 저장할 수 있는 저장 프로시저의 개수 |
| num proc buffs used | 저장 프로시저를 보관하는 캐시 슬롯의 개수 |
| num proc buffs active | 현재 실행 중인 저장 프로시저를 보관하는 캐시 슬롯의 개수 |
| proc cache size | 프로시저 캐시의 전체 크기 |
| proc cache used | 저장 프로시저를 보관하는 프로시저 캐시의 용량 |
| proc cache active | 현재 실행 중인 저장 프로시저를 보관하는 프로시저 캐시의 용량 |
DBCC CACHESTATS
개첵들의 현재 버퍼에 있는 캐쉬 정보, SQL 2000, 7.0 버전에 적용
- Object Type Hit Ratio Object Count Avg Cost Avg Pages LW Object Count LW Avg Cost LW Avg Stay (ms) LW Avg Use Count
Proc 0 0 0 0 0 0 0 0
Prepared 0 0 0 0 0 0 0 0
Adhoc 0 0 0 0 0 0 0 0
ReplProc 0 0 0 0 0 0 0 0
Trigger 0 0 0 0 0 0 0 0
Cursor 0 0 0 0 0 0 0 0
Exec Cxt 0 0 0 0 0 0 0 0
View 0 0 0 0 0 0 0 0
Default 0 0 0 0 0 0 0 0
UsrTab 0 0 0 0 0 0 0 0
SysTab 0 0 0 0 0 0 0 0
Check 0 0 0 0 0 0 0 0
Rule 0 0 0 0 0 0 0 0
Summary 0 0 0 0 0 0 0 0
- Hit Ratio: Displays the percentage of time that this particular object was found in SQL Server's cache. The bigger this number, the better.
- Object Count: Displays the total number of objects of the specified type that are cached.
- Avg. Cost: A value used by SQL Server that measures how long it takes to compile a plan, along with the amount of memory needed by the plan. This value is used by SQL Server to determine if the plan should be cached or not.
- Avg. Pages: Measures the total number of 8K pages used, on average, for cached objects.
- LW Object Count, LW Avg Cost, WL Avg Stay, LW Ave Use: All these columns indicate how many of the specified objects have been removed from the cache by the Lazy Writer. The lower the figure, the better.
DBCC DROPCLEANBUFFERS
정확한 테스트를 할때 유용하게 사용되며 캐쉬의 버퍼를 깨끗하게 지운다. 그러나 dirty page를 처리하는것은 아니다. 단지 버퍼를 지우는 것이다.
버퍼 풀에서 빈 버퍼를 모두 제거합니다.
버퍼 풀에서 빈 버퍼를 삭제하려면 먼저 CHECKPOINT를 사용해 빈 버퍼 캐시를 만드십시오. 이 과정은 현재 데이터베이스에 대한 모든 커밋되지 않은 페이지를 디스크로 기록하고 버퍼를 비웁니다. 버퍼를 비운 후에 DBCC DROPCLEANBUFFERS 명령을 실행해 버퍼 풀에서 모든 버퍼를 제거할 수 있습니다.
SQL 2000, 7.0 에서 사용
DBCC ERRORLOG
자주 sql 서버를 재 시작하지 않으면 서버 에러 로그 파일이 커지게 된다. 에러로그 파일 하나를 끝내고 다시 새로 시작하게 만듭니다. (순환시킴)
Job으로 작업을 걸어도 된다. 같은 작업을 하는 프로시저가 sp_cycle_errorlog 임
DBCC FLUSHPROCINDB
데이터베이스가 사용하는 특수한 저장 프로시저를 캐쉬에서 삭제한다. 모두 다 삭제하는것은 아니다. 데이터베이스 아이디를 입력해서 특정 데이터베이스만도 가능하다.
상세 내역은 How to Interact with SQL Server's Data and Procedure Cache 참조 하여 읽어본다.
DBCC INDEXDEFRAG
인덱스 조각 모음.
온라인에서 사용가능하기 때문에 장시간의 테이블 lock을 걸지는 않는다. 해당 작업은 병렬로 처리 가능하지 않는다. 즉 한 테이블에 인덱스를 여러개 처리하라고 명령해도 한 인덱스 작업이 끝난 후에 다른 인덱스 조각모음을 실시한다.
2005에서는 ALTER INDEX 사용은 권고한다. 해당 명령어는 더 이상 사용하지 않는다.
- DBCC INDEXDEFRAG (Database_Name, Table_Name, Index_Name)
DBCC FREEPROCCACHE
모든 프로시저를 캐쉬에서 삭제한다. 테스트 시작 전에 사용하면 유용하다.
DBCC OPENTRAN
An open transaction can leave locks open, preventing others from accessing the data they need in a database. This command is used to identify the oldest open transaction in a specific database.
- DBCC OPENTRAN('database_name')
DBCC PAGE
Use this command to look at contents of a data page stored in SQL Server.
- DBCC PAGE ({dbid|dbname}, pagenum [,print option] [,cache] [,logical])
DBCC PINTABLE & DBCC UNPINTABLE
By default, SQL Server automatically brings into its data cache the pages it needs to work with. These data pages will stay in the data cache until there is no room for them, and assuming they are not needed, these pages will be flushed out of the data cache onto disk. At some point in the future when SQL Server needs these data pages again, it will have to go to disk in order to read them again into the data cache for use. If SQL Server somehow had the ability to keep the data pages in the data cache all the time, then SQL Server's performance would be increased because I/O could be significantly reduced on the server.
The process of "pinning a table" is a way to tell SQL Server that we don't want it to flush out data pages for specific named tables once they are read in in the first place. This in effect keeps these database pages in the data cache all the time, which eliminates the process of SQL Server from having to read the data pages, flush them out, and reread them again when the time arrives. As you can imagine, this can reduce I/O for these pinned tables, boosting SQL Server's performance.
To pin a table, the command DBCC PINTABLE is used. For example, the script below can be run to pin a table in SQL Server:
- DECLARE @db_id int, @tbl_id int
USE Northwind
SET @db_id = DB_ID('Northwind')
SET @tbl_id = OBJECT_ID('Northwind..categories')
DBCC PINTABLE (@db_id, @tbl_id)
이 기능은 SQL Server 버전 6.5에서 성능 개선을 위해 도입되었으나 DBCC PINTABLE은 아주 좋지 않은 부작용을 갖고 있습니다. 그 중에는 버퍼 풀 손상 가능성도 포함됩니다. DBCC PINTABLE은 더 이상 필요하지 않으며 추가적인 문제를 예방하기 위해 제거되었습니다. 이 명령의 구문은 계속 작동하지만 서버에 영향을 주지 않습니다.
DBCC REINDEX
Periodically (weekly or monthly) perform a database reorganization on all the indexes on all the tables in your database. This will rebuild the indexes so that the data is no longer fragmented. Fragmented data can cause SQL Server to perform unnecessary data reads, slowing down SQL Server's performance.
If you do a reorganization on a table with a clustered index, any non-clustered indexes on that same table will automatically be rebuilt.
Database reorganizations can be done scheduling SQLMAINT.EXE to run using the SQL Server Agent, or if by running your own custom script via the SQL Server Agent (see below).
Unfortunately, the DBCC DBREINDEX command will not automatically rebuild all of the indexes on all the tables in a database, it can only work on one table at a time. But if you run the following script, you can index all the tables in a database with ease.
- DBCC DBREINDEX('table_name', fillfactor)
DBCC SHOWCONTIG
인덱스에 대한 페이지 분할등 정보를 보여줌
If the scan density is less than 75%, then you may want to reindex the tables in your database reindex 추천
- DBCC SHOWCONTIG (Table_id, IndexID)
DBCC SHOW_STATISTICS
Used to find out the selectivity of an index. Generally speaking, the higher the selectivity of an index, the greater the likelihood it will be used by the query optimizer. You have to specify both the table name and the index name you want to find the statistics on.
-
DBCC SHOW_STATISTICS (table_name, index_name)
DBCC SQLMGRSTATS
Used to produce three different values that can sometimes be useful when you want to find out how well caching is being performed on ad-hoc and prepared Transact-SQL statements.
- Memory Used (8k Pages): If the amount of memory pages is very large, this may be an indication that some user connection is preparing many Transact-SQL statements, but it not un-preparing them.
- Number CSql Objects: Measures the total number of cached Transact-SQL statements.
- Number False Hits: Sometimes, false hits occur when SQL Server goes to match pre-existing cached Transact-SQL statements. Ideally, this figure should be as low as possible.
DBCC SQLPERF()
This command includes both documented and undocumented options. Let's take a look at all of them and see what they do.
DBCC UPDATEUSAGE
The official use for this command is to report and correct inaccuracies in the sysindexes table, which may result in incorrect space usage reports. Apparently, it can also fix the problem of unreclaimed data pages in SQL Server. You may want to consider running this command periodically to clean up potential problems. This command can take some time to run, and you want to run it during off times because it will negatively affect SQL Server's performance when running. When you run this command, you must specify the name of the database that you want affected.
DBCC UPDATEUSAGE는 테이블 또는 인덱스의 각 파티션에 대해 행, 사용된 페이지, 예약된 페이지, 리프 페이지 및 데이터 페이지의 개수를 수정합니다. 시스템 테이블에 부정확한 데이터가 없으면 DBCC UPDATEUSAGE는 데이터를 반환하지 않습니다. 부정확한 데이터를 검색 및 수정하고 WITH NO_INFOMSGS를 사용하지 않았으면 DBCC UPDATEUSAGE는 시스템 테이블에서 업데이트 중인 행과 열을 반환합니다.
-
DBCC UPDATEUSAGE ('databasename')
DBCC TRACESTATUS
추적 플래그 상태를 표시합니다.
이 글은 스프링노트에서 작성되었습니다.
'Common Admin' 카테고리의 다른 글
| Raid구성성능 (0) | 2010.06.04 |
|---|---|
| DB파일사이즈 (1) | 2010.06.04 |
| WMI Providers_2 (0) | 2010.06.04 |
| WMI Providers (1) | 2010.06.04 |
SQL SERVER 2005 이상
Microsoft Windows PowerShell and SQL Server 2005 WMI Providers - Part 2
이 글은 스프링노트에서 작성되었습니다.
'Common Admin' 카테고리의 다른 글
| DB파일사이즈 (1) | 2010.06.04 |
|---|---|
| DBCC 명령어 (0) | 2010.06.04 |
| WMI Providers (1) | 2010.06.04 |
| SID및ID (0) | 2010.06.04 |
SQL SERVER 2005 이상
Microsoft Windows PowerShell and SQL Server 2005 WMI Providers - Part 1
이 글은 스프링노트에서 작성되었습니다.
'Common Admin' 카테고리의 다른 글
| DBCC 명령어 (0) | 2010.06.04 |
|---|---|
| WMI Providers_2 (0) | 2010.06.04 |
| SID및ID (0) | 2010.06.04 |
| Admin::JOB 단계 설정시 option (0) | 2010.04.29 |
서버 수준 ID 번호
SQL Server 로그인을 만들면 ID와 SID가 할당됩니다. 두 번호는 sys.server_principals 카탈로그 뷰에 principal_id와 SID로 표시됩니다. ID(principal_id)는 로그인을 서버 내의 보안 개체로 식별하며 로그인이 생성될 때 SQL Server에서 할당합니다. 로그인을 삭제하면 해당 ID 번호가 재활용됩니다. SID는 로그인의 보안 컨텍스트를 식별하며 서버 인스턴스 내에서 고유합니다. SID의 원본은 로그인 생성 방법에 따라 달라집니다. Windows 사용자나 그룹에서 로그인을 만들면 원본 보안 주체의 Windows SID가 지정됩니다. Windows SID는 도메인 내에서 고유합니다. 인증서나 비대칭 키에서 SQL Server 로그인을 만들면 공개 키의 SHA-1 해시에서 파생된 SID가 할당됩니다. 로그인을 암호가 필요한 레거시 스타일 SQL Server 로그인으로 만들면 서버에서 SID를 생성합니다.
데이터베이스 수준 ID 번호
데이터베이스 사용자를 만들면 ID가 할당됩니다. ID를 서버 보안 주체에 매핑하면 SID(보안 ID)도 할당됩니다. 두 번호는 sys.database_principals 카탈로그 뷰에 principal_id와 SID로 표시됩니다. ID는 사용자를 데이터베이스 내의 보안 개체로 식별합니다. 데이터베이스 사용자를 삭제하면 해당 ID가 재활용됩니다. 데이터베이스 사용자에게 할당된 SID는 데이터베이스 내에서 고유합니다. SID의 원본은 데이터베이스 사용자 생성 방법에 따라 달라집니다. SQL Server 로그인에서 사용자를 만들면 해당 로그인의 SID가 지정됩니다. 인증서나 비대칭 키에서 사용자를 만들면 공개 키의 SHA-1 해시에서 SID가 파생됩니다. 로그인 없이 사용자를 만들면 해당 SID는 NULL이 됩니다.
최대 데이터베이스 사용자 수
최대 데이터베이스 사용자 수는 사용자 ID 필드의 크기에 의해 결정됩니다. 사용자 ID의 값은 0 또는 양의 정수여야 합니다. SQL Server 2000에서 사용자 ID는 16비트로 구성된 smallint로 저장되며 16비트 중 하나는 부호입니다. 이런 이유로 SQL Server 2000에서 최대 사용자 ID 수는 215 = 32,768입니다. SQL Server 2005에서는 사용자 ID가 32비트로 구성된 int로 저장되며 32비트 중 하나는 부호입니다. 이러한 추가 비트를 사용하여 231 = 2,147,483,648개의 ID 번호를 할당할 수 있습니다.
데이터베이스 사용자 ID는 다음 표에 설명된 것처럼 미리 할당된 범위로 나뉩니다.
| SQL Server 2000 ID | SQL Server 2005 ID | 할당 대상 |
|---|---|---|
|
0 |
0 |
public |
|
1 |
1 |
dbo |
|
2 |
2 |
guest |
|
3 |
3 |
INFORMATION_SCHEMA |
|
4 |
4 |
SYSTEM_FUNCTION_SCHEMA |
|
5 - 16383 |
5 - 16383 |
사용자, 별칭, 응용 프로그램 역할 |
|
16384 |
16384 |
db_owner |
|
16385 |
16385 |
db_accessadmin |
|
16386 |
16386 |
db_securityadmin |
|
16387 |
16387 |
db_ddladmin |
|
16389 |
16389 |
db_backupoperator |
|
16390 |
16390 |
db_datareader |
|
16391 |
16391 |
db_datawriter |
|
16392 |
16392 |
db_denydatareader |
|
16393 |
16393 |
db_denydatawriter |
|
16394 - 16399 |
16394 - 16399 |
예약되어 있습니다. |
|
16400 - 32767 |
역할 | |
|
16400 - 2,147,483,647 |
사용자, 역할, 응용 프로그램 역할, 별칭 |
이 글은 스프링노트에서 작성되었습니다.
'Common Admin' 카테고리의 다른 글
| WMI Providers_2 (0) | 2010.06.04 |
|---|---|
| WMI Providers (1) | 2010.06.04 |
| Admin::JOB 단계 설정시 option (0) | 2010.04.29 |
| admin::여러 TCP 포트에서 수신하도록 데이터베이스 엔진 구성 (0) | 2010.04.04 |
Serverice Borker 보안 #
- Service Broker 보안은 인증서를 이용합니다
- 일반적으로 인증서를 사용하여 원격 데이터베이스의 자격 증명을 설정한 다음 원격 데이터베이스에서 로컬 사용자에게 작업을 매핑합니다.
- 로컬 사용자에 대한 사용 권한은 원격 서비스 대신 모든 작업에 적용됩니다
- 인증서는 데이터베이스 간에 공유됩니다
- 사용자에 대한 다른 정보는 공유되지 않습니다.
대화 보안#
개별 대화 메시지를 암호화하고 대화 참가자의 ID를 확인합니다. 또한 원격 권한 부여와 메시지 무결성 검사를 제공합니다. 대화 보안은 두 서비스 간에 인증되고 암호화된 통신을 설정합니다.
기본사항#
Service Broker 대화 보안을 사용하면 응용 프로그램이 개별 대화에 대한 인증, 권한 부여 또는 암호화를 사용할 수 있습니다.
적으로 모든 대화에는 대화 보안이 사용됩니다. 대화를 시작할 때 BEGIN DIALOG CONVERSATION 문에 ENCRYPTION = OFF 절을 포함하여 대화 보안 없이도 대화가 진행될 수 있도록 명시적으로 허용할 수 있습니다. 그러나 대화의 대상이 되는 서비스에 원격 서비스 바인딩이 존재하면 ENCRYPTION = OFF인 경우에도 대화에 보안이 사용됩니다.
SQL Server는 대화 보안을 사용하는 대화에 대한 세션 키를 만듭니다.
션 키가 데이터베이스에 저장되는 동안 세션 키를 보호하기 위해 Service Broker는 데이터베이스의 마스터 키를 사용하여 세션 키를 암호화합니다
데이터베이스 마스터 키를 사용할 수 없으면 데이터베이스 마스터 키가 생성되거나 대화의 시간이 초과될 때까지 대화에 대한 메시지는 오류가 발생한 상태로 transmission_status에 남아 있습니다. 그러므로 대화에 참가하는 두 데이터베이스가 동일한 인스턴스에서 호스팅되는 경우라도 두 데이터베이스 모두에 마스터 키가 있어야 합니다.그러므로 대화에 참가하는 두 데이터베이스가 동일한 인스턴스에서 호스팅되는 경우라도 두 데이터베이스 모두에 마스터 키가 있어야 합니다.
- 시작 데이터베이스에 마스터 키가 없으면 대화가 실패합니다. 대상 데이터베이스에 마스터 키가 없으면 메시지는 시작 데이터베이스의 전송 큐에 그대로 남습니다.
-
이러한 메시지에 대한 마지막 전송 오류는 메시지를 배달하지 못한 원인을 보여 줍니다.
ENCRYPTION = OFF매개 변수를 사용하여 암호화되지 않은 대화를 만들거나 다음 명령을 사용하여 데이터베이스 마스터 키를 만드세요.- CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>'
익명보안#
- 익명 보안은 시작 서비스에서 트러스트되지 않은 데이터베이스로 메시지를 보내지 못하도록 합니다. Service Broker는 대화에서 익명 보안을 사용할 경우 네트워크에서 전송되는 메시지를 암호화합니다.
-
예를 들어 작업 주문을 전송하는 응용 프로그램은 작업 주문을 받는 사람이 원하는 대상이 확실함을 보장해야 하지만, 대상 데이터베이스는 작업 주문을 전송하는 서비스에 어떤 특별한 권한도 제공할 필요가 없습니다. 이 경우 시작 서비스가 포함된 데이터베이스에는 대상 서비스에 대한 원격 서비스 바인딩이 포함되어야 합니다.
대상 서비스는 시작 서비스의 ID를 확인할 수 없으므로 시작 서비스를 대신하여 수행되는 작업은 대상 데이터베이스에서 고정 데이터베이스 역할 public의 멤버로 실행됩니다. 대상 데이터베이스는 대화를 시작한 사용자에 대한 정보를 받지 않습니다. 대상 데이터베이스에는 대화를 시작하는 사용자에 대한 인증서가 없어도 됩니다.
익명 보안을 사용하는 대화의 경우 대화의 양측이 시작 데이터베이스가 생성한 세션 키를 사용합니다. 대상 데이터베이스는 시작 데이터베이스에 세션 키를 반환하지 않습니다.
대화 보안에 대한 보안 컨텍스트#
- Service Broker는 전적으로 SQL Server 인스턴스 내에서 실행되지 않는 보안 대화에 대해 항상 원격 권한 부여를 사용합니다
보안 대화 만들기#
SQL ServerBroker 는 두 데이터베이스 사이의 대화를 설정하는 경우 시작 서비스는대상 큐에 메시지를 추가할 수 있도록 대상 데이터베이스에 사용자 컨텍스트를 설정해야 합니다.
이러한 사용자 컨텍스트는 시작 서비스에 대상에 대한 대화를 열 권한이 있는지 여부를 확인합니다.
이러한 작업을 수행하는 가장 유연한 방법은 인증서 및 원격 서비스 바인딩을 만드는 것입니다. 인증서를 만드는 방법은 CREATE CERTIFICATE(Transact-SQL)를 참조하십시오. 원격 서비스 바인딩을 만드는 방법은 CREATE REMOTE SERVICE BINDING(Transact-SQL)을 참조하십시오.
인증서 및 원격 서비스 바인딩을 만드는 다른 방법은 SQL Server 보안을 사용하여 두 데이터베이스 사이에 트러스트 관계를 설정하는 것입니다. 그러면 시작 서비스의 소유자가 대상 서비스의 사용자를 가장합니다. 이를 위해 시작 데이터베이스의 TRUSTWORTHY 데이터베이스 속성을 ON으로 설정하고 대상 데이터베이스의 사용자에게 인증 권한을 부여해야 할 수 있습니다. 자세한 내용은 EXECUTE AS를 사용하여 데이터베이스 가장 확장을 참조하십시오.
대화보안 유형 결정#
- 보안 유형은 BEGIN DIALOG CONVERSATION 문의 옵션, 서비스에 대한 원격 서비스 바인딩 설정, 시작 서비스의 소유자가 인증서를 소유하는지 여부 등에 따라 결정됩니다.
- sys.remote_service_bindings 카탈로그 뷰에서 대상 서비스 대한 원격 서비스 바인딩을 조회합니다.
- 원격 서비스 바인딩이 있으면 대화는 BEGIN DIALOG CONVERSATION 문의 설정에 관계없이 암호화를 사용합니다.
| | 원격 서비스 바인딩이 없음 | ANONYMOUS = ON으로 설정된 원격 서비스 바인딩 | ANONYMOUS = OFF로 설정된 원격 서비스 바인딩 | |
|---|---|---|---|---|
|
서비스 소유자에게 인증서가 있음 |
ENCRYPTION = ON |
대화가 실패함 |
익명 보안 |
높은 수준의 보안 |
|
서비스 소유자에게 인증서가 있음 |
ENCRYPTION = OFF |
대화 보안 없음 |
익명 보안 |
높은 수준의 보안 |
|
서비스 소유자에게 인증서가 없음 |
ENCRYPTION = ON |
대화가 실패함 |
익명 보안 |
대화가 실패함 |
|
서비스 소유자에게 인증서가 없음 |
ENCRYPTION = OFF |
대화 보안 없음 |
익명 보안 |
대화가 실패함 |
- 대화가 실패함
-
요청한 보안을 제공하는 데 필요한 정보가 SQL Server에 없습니다. Service Broker는 대화를 종료하고 시작 서비스에 대한 큐에 오류 메시지를 넣습니다.
- 대화 보안 없음
-
SQL Server가 대화에 대화 보안을 제공하지 않습니다. 시작 서비스를 대신하여 수행되는 작업은 대상 데이터베이스에서 public으로 실행됩니다. 이 대화에 대해서는 메시지가 암호화되지 않습니다. 그러나 전송 보안의 경우 네트워크의 메시지를 암호화할 수 있습니다.
- 익명 보안
-
SQL Server가 익명 보안을 사용합니다. 이 대화에 대한 인스턴스 외부의 메시지가 암호화됩니다. 대상 서비스는 시작 서비스의 ID를 확인할 수 없으므로 시작 서비스를 대신하여 수행되는 작업은 대상 데이터베이스에서 public으로 실행됩니다.
- 높은 수준의 보안
-
SQL Server는 높은 수준의 보안을 사용합니다. 이 대화에 대한 인스턴스 외부의 메시지가 암호화됩니다. 시작 서비스를 대신하여 수행되는 작업은 대상 데이터베이스에서 지정된 사용자로 실행됩니다.
전송보안#
- 권한이 없는 데이터베이스에서 Service Broker 메시지를 로컬 인스턴스의 데이터베이스로 보낼 수 없게 합니다. 전송 보안은 두 데이터베이스 간에 인증된 네트워크 연결을 설정합니다.
- 데이터베이스 관리자가 데이터베이스에 대한 네트워크 연결을 제한할 수 있으며 네트워크의 메시지를 암호화할 수 있습니다. Service Broker 끝점은 인증서 기반 인증과 Windows 인증을 모두 지원합니다.
- 전송 보안은 두 인스턴스 간의 네트워크 연결에 적용됩니다. 전송 보안은 통신할 수 있는 인스턴스를 제어하며 두 인스턴스 간에 암호화를 제공합니다.
- 전송 보안은 인스턴스 전체에 적용됩니다. 전송 보안은 개별 메시지 내용을 보호하지 않으며 인스턴스 내의 개별 서비스에 대한 액세스도 제어하지 않습니다. 메시지가 대상 인스턴스에 도달할 때까지 Service Broker 대화 보안은 메시지가 보내는 인스턴스를 떠날 때 개별 메시지를 암호화합니다.
- 인스턴스에 사용되는 인증 유형은 각 인스턴스의 Service Broker 끝점의 AUTHENTICATION 옵션에 따라 결정됩니다
- 끝점에서 둘 이상의 인증 방법을 지정하면 연결을 시작하는 인스턴스에 인증 방법이 지정된 순서에 따라 사용되는 정확한 인증 방법이 달라집니다. 협상하는 동안 각 인스턴스에서 지원되는 인증 유형과 알고리즘을 모두 보고합니다. 시작자는 수락자가 지정한 순서에 따라 양 끝점에서 지원되는 인증 방법을 시도하므로 대화가 오래 실행되는 경우 둘 이상의 연결을 통해 메시지를 교환할 수 있으며 대화를 시작하는 인스턴스에 따라 연결의 인증이 다를 수 있습니다.
- Service Broker 끝점은 두 종류의 암호화를 지원합니다. 인증과 마찬가지로 연결을 시작하는 인스턴스에 지정된 암호화 방법의 순서에 따라 연결에 사용되는 정확한 암호화 방법이 결정됩니다.
사용자 수준 권한#
- 개 이상의 인스턴스를 포함하는 대부분의 Service Broker 응용 프로그램은 해당 응용 프로그램을 위해 특별히 생성된 데이터베이스 보안 주체의 보안 컨텍스트에서 실행됩니다. 이러한 데이터베이스 보안 주체는 응용 프로그램이 수행하는 작업을 완료하는 데 필요한 최소 권한을 가져야 합니다.
- 원격 권한 부여를 위해 지정된 데이터베이스 보안 주체는 시작 서비스를 호스팅하는 데이터베이스에 CONNECT 권한 필요
- 시작 서비스에는 SEND 권한 필요
- 데이터베이스 보안추제가 대화를 시작하려면 해당 보안 주체에 시작 서비스의 큐에 대한 RECEIVE 권한 필요
- 시작 서비스를 소유하는 데이터베이스 보안주체는 대상 서비스에 대한 SEND 권한 필요
- 데이터베이스 보안주체가 서비스에 메세지를 보내려면 해당 보안주체에 서비스에 대한 SEND 권한 있어야함
- 활성화 저장 프로시저에 대한 사용자로 지정된 사용자 프로시저를 실행할 수 있는 권한
- SSPI가 사용되면 원격데이터베이스대한 서비스 게정은 master 에서 connect 권한, 로그인에도 해당되어야함, 따라서 원격 SQL Server 인스턴스가 실행되는 계정은 윈도우 인정을 사용하여 SQL Server에 로그인 할 수 있는 권한이 있어야 합니다. 로그인이 다른 권한을 갖거나 데이터베이스의 개체를 소유하기 위해 필요한 요구 사항은 없습니다.
-
인증서 보안요구사항#
- 키 모듈러스는 2048 미만이어야 합니다.
- 전체 인증서 길이는 32KB 미만이어야 합니다.
- 주체 이름을 지정해야 합니다.
- 유효 날짜를 지정해야 합니다.
키 길이는 64비트의 배수여야 합니다.
인증서를 SQL Server에 저장할 경우 인증서가 데이터베이스에 대한 마스터 키로 암호화되어야 합니다. Service Broker는 암호만 사용하여 암호화된 인증서를 사용할 수 없습니다. 또한 데이터베이스에 대한 마스터 키는 인스턴스에 대한 서비스 키로 암호화되어야 합니다. 그렇지 않으면 Service Broker가 마스터 키를 열 수 없습니다.
- SQL Server가 인증서를 사용하여 대화를 시작하려면 인증서가 ACTIVE FOR BEGIN_DIALOG로 표시되어야 합니다. 대화 시작 시에는 인증서가 기본적으로 활성으로 표시됩니다.
이 글은 스프링노트에서 작성되었습니다.
'Service Broker' 카테고리의 다른 글
| Service Broker::장점 (1) | 2010.06.04 |
|---|---|
| Service Broker::아키텍처 (0) | 2010.06.04 |
| Service Broker::소개 (0) | 2010.06.04 |
 Prev
Prev

