'분류 전체보기'에 해당되는 글 192건
- 2014.11.06 Windbg 명령어 & 설치
- 2014.09.02 배포 메일링 주소 변경
- 2014.08.21 SQL 2012 Intergration Service 구성 항목 설정
- 2014.08.19 SQL Server Replication Error - The specified LSN for repldone log scan occurs before the current start of replication in the log
- 2013.09.13 Tempdb 공간 사용 확인
- 2013.03.13 Database Landscape map – February 2013
- 2013.03.13 detach 한 DB를 다른 서버에서 attach 하면 log 백업 바로 가능 한가?
- 2013.03.13 월에 두번째/세번째 요일 구하기.
- 2013.01.08 SQL Server tempdb 복구
- 2012.11.19 파티션 테이블 - 문제점, 주의 사항
- 2012.11.02 T-SQL::동적 PIVOT 생성 3
- 2012.11.01 tablediff 유틸리티
- 2012.11.01 Function to return a range of dats - 날짜 범위 펑션
- 2012.10.09 시작시 늦어지는 경우 (Slow StartUP) 1
- 2012.08.23 권한 조회
Command | option | usage | Desc |
종료 | |||
q | 디버깅 종료 | ||
qd | 디버깅 종료;연결해제 | ||
디버깅 환경정보 | |||
vertarget | 타겟 컴퓨터 정보 표시 | ||
version | 디버그 환경 정보 표시 | ||
.lastevent | 마지막 디버그 이벤트 정보 표시 | ||
|| | 디버깅 세션 정보 표시 | ||
sumble & sorurce | |||
.symfix | MS 심볼경로 설정 | ||
.sympath | 심볼경로 확인/설정 | ||
.sym noisy | 심볼파일 검색 과정을 출력 | ||
.srcpath | 소스경로 설정 | ||
.srcnoisy | .srcnoisy 1 | 소스경로 검색 과정을 출력 | |
모듈 | |||
lm | l | 로드된 모듈만 표시 | |
m [pattern] | 패턴과 일치되는 모듈만 표시 | ||
v | 모듈 상세정보 표시 | ||
!lmi | !lmi ntdll.dll | 모듈 상세정보 표시 | |
.reload | /f [m_name] | 심볼을 즉시 로드 | |
x | X ntdll!* X *!*abc* | /v /t /n | 심볼 타입을 표시. 데이터 타입을 표시 이름순으로 정렬 |
ln | ln [address] | 해당 주소에 근접한 심볼의 정보 표시 | |
레지스터 | |||
r | 레지스터 정보 표시 | ||
r $proc | 현재 프로세스의 PEB주소( user-mode) 현재 프로세스의 EPROcESS주소( kernel-mode) | ||
r $thread | 현재 스레드의 TEB주소( user-mode) 현재 스레드의 ETHREAD주소( kernel-mode) | ||
r $tpid | 현재 프로세스ID(PID) | ||
r $tid | 현재 스레드ID(TID) | ||
언어셈블 | |||
u | f b | 언어셈블 언어셈블(함수전체) 언어셈블(ip이전의8개 명령어) | |
콜스택 | |||
k | [n] p b n v f | 콜스택 정보표시 함수정보 출력 인자표시 프레임번호 FPO정보 표시 스택 사용량 표시 | |
break point | |||
bp | bp 0x123456 | bp 설정 | |
bl | bp 리스트 출력 | ||
bc | bc * | [frame_no] | bp 삭제 | |
bd,be | bc * | [frame_no] | bp disable/enable | |
bm | bm notepad!*Win* | 패턴과 일치하는 모든심볼에 bp설정 | |
bu | bu aaa!bbb | 로드되지 않은 심볼에 대한 bp설정 | |
ba | 특정 주소에 access시 bp | ||
지역변수 | |||
dv | dv modulr!test* | /i /V | 심볼유형과 인자유형 표시 변수저장 위치 표시( register or address ) |
데이터유형 | |||
dt | df _EPROCESS 0xaddr | 주소를 특정 데이터 형으로 변환해서 표시 | |
du | Unicode string 표시 | ||
da | Ansi string 표시 | ||
dc | |||
db | |||
dy | |||
!address | !address !address [address] | ||
프로세스 & 스레드 정보 | |||
!peb | PEB(Process Environment Block)표시 | ||
!teb | TEB(Thread Environment Block) 표시 | ||
!gle | API의 마지막 에러코드 표시 | ||
실행 제어 | |||
t | Trace | ||
~.t | 다른 스레드를 중지시킨 상태에서 하나의statementt 실행 | ||
g | |||
p | Step Over | ||
gu | gu ~0 gu | 현재함수가 복귀할 때 까지 실행 스레드 0을 제외한 모든 스레드를freeze함 | |
wt | 내부에서 호출된 함수와 함수호출 횟수등의 정보 표시 | ||
.cxr | 컨텍스트 변경 | ||
!ready | |||
.thread | |||
!thread | |||
.trap | |||
.process | |||
!process | |||
ed | |||
eb | eb .-6 90 90 90 90 90 90 | 6byte를NOP(0x90)으로 변경 | |
!error | !error [error code] | 에러코드 정보표시 | |
'ETC' 카테고리의 다른 글
| SQL Server 2012 Certification upgrade info (0) | 2015.05.20 |
|---|---|
| 메모리 dump 분석 예 ( 정확하지 않음 ) (0) | 2014.11.06 |
| Window 서비스 등록/삭제 방법 (0) | 2011.10.20 |
| Admin::Superdome VS DL580 G7 (0) | 2011.01.10 |
메일링 주소가 변경되었을 때 테이블 내역 수정 하기
ReportServiceDB
UPDATE SUBSCRIPTIONS
SET EXTENSIONSETTINGS = REPLACE(CONVERT(NVARCHAR(MAX), EXTENSIONSETTINGS), '변경전', '변경후') Collate Latin1_General_CI_AS_KS_WS
WHERE EXTENSIONSETTINGS LIKE '%DL-SEL-DBA@EBAY.COM%'
'Reporting Service' 카테고리의 다른 글
| 시작시 늦어지는 경우 (Slow StartUP) (1) | 2012.10.09 |
|---|---|
| 공유 데이터 원본 Overwrite (0) | 2009.08.04 |
1. SQL 2012 Intergration Service 의 경우 원격 인스턴스 접근.. 명명된 인스턴스 등을 사용할 때 구성 파일을 설정해야 한다.
도움말 : http://msdn.microsoft.com/ko-kr/library/ms137789.aspx
Integration Services 서비스는 구성 파일을 사용하여 해당 설정을 구성합니다. 기본적으로 이 구성 파일의 이름은 MsDtsSrvr.ini.xml이고 저장 위치는 %ProgramFiles%\Microsoft SQL Server\110\DTS\Binn 폴더입니다.
일반적으로 이 구성 파일이나 이 구성 파일의 위치는 변경하지 않아도 되지만 패키지가 명명된 인스턴스, 데이터베이스 엔진의 원격 인스턴스 또는 여러 데이터베이스 엔진 인스턴스에 저장되는 경우에는 이 구성 파일을 수정해야 합니다. 또한 이 구성 파일을 기본 위치 이외의 다른 위치로 이동할 경우 파일 위치를 지정하는 레지스트리 키도 수정해야 합니다.
Integration Services를 설치할 때 설치 프로세스는 Integration Services 서비스에 대한 구성 파일을 만들고 설치합니다. 이 구성 파일에는 다음과 같은 설정이 들어 있습니다.
서비스가 중지되면 패키지에 중지 명령이 전송됩니다.
SQL Server Management Studio의 개체 탐색기에서 Integration Services에 대해 표시할 루트 폴더는 MSDB와 파일 시스템 폴더입니다.
Integration Services 서비스에서 관리하는 파일 시스템의 패키지는 %ProgramFiles%\Microsoft SQL Server\110\DTS\Packages에 있습니다.
이 구성 파일은 Integration Services 서비스에서 관리할 패키지가 들어 있는 msdb 데이터베이스도 지정합니다. 기본적으로 Integration Services 서비스는 Integration Services와 동시에 설치되는 데이터베이스 엔진 인스턴스의 msdb 데이터베이스에 있는 패키지를 관리하도록 구성됩니다. 데이터베이스 엔진 인스턴스가 동시에 설치되지 않는 경우 Integration Services 서비스는 데이터베이스 엔진의 로컬 기본 인스턴스에 있는 msdb 데이터베이스에 저장된 패키지를 관리하도록 구성됩니다

수정 파일 예
<?xml version="1.0" encoding="utf-8"?>
<DtsServiceConfiguration xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<StopExecutingPackagesOnShutdown>true</StopExecutingPackagesOnShutdown>
<TopLevelFolders>
<Folder xsi:type="SqlServerFolder">
<Name>MSDB</Name>
<ServerName>ServerName\InstanceName</ServerName>
</Folder>
<Folder xsi:type="FileSystemFolder">
<Name>File System</Name>
<StorePath>..\Packages</StorePath>
</Folder>
</TopLevelFolders>
</DtsServiceConfiguration>
2. 원격 Intergration Service 서버에 연결
SQL Server Management Studio나 다른 관리 응용 프로그램에서 원격 서버의 Integration Services 인스턴스에 연결하려면 응용 프로그램 사용자에게 서버에 대한 특정 권한 집합이 필요합니다.
원격 서비스에 접속시 엑세스가 거부되었다고 하면 권한을 부여 해야 합니다.
충분한 권한이 없는 사용자가 원격 서버의 Integration Services 인스턴스에 연결하려고 하면 "액세스가 거부되었습니다."라는 오류 메시지가 나타납니다. 사용자에게 필요한 DCOM 권한을 부여하면 이 오류 메시지를 방지할 수 있습니다.
Windows Server 2003 또는 Windows XP에서 원격 사용자의 권한을 구성하려면
사용자가 로컬 Administrators 그룹의 멤버가 아니면 분산 COM 사용자 그룹에 해당 사용자를 추가합니다. 이 작업은 관리 도구 메뉴에서 액세스할 수 있는 컴퓨터 관리 MMC 스냅인에서 수행할 수 있습니다.
제어판을 열고 관리 도구를 두 번 클릭한 다음 구성 요소 서비스를 두 번 클릭하여 구성 요소 서비스 MMC 스냅인을 시작합니다.
콘솔의 왼쪽 창에서 구성 요소 서비스 노드를 확장합니다. 컴퓨터 노드를 확장하고 내 컴퓨터를 확장한 다음 DCOM 구성 노드를 클릭합니다.
DCOM 구성 노드를 선택하고 구성할 수 있는 응용 프로그램 목록에서 SQL Server Integration Services 11.0을 선택합니다.
SQL Server Integration Services 11.0을 마우스 오른쪽 단추로 클릭하고 속성을 선택합니다.
SQL Server Integration Services 11.0 속성 대화 상자에서 보안 탭을 선택합니다.
시작 및 활성화 권한에서 사용자 지정을 선택하고 편집을 클릭하여 시작 권한 대화 상자를 엽니다.
시작 권한 대화 상자에서 사용자를 추가하거나 삭제하고 적절한 사용자 및 그룹에 적절한 권한을 할당합니다. 로컬 시작, 원격 시작, 로컬 활성화 및 원격 활성화 권한을 할당할 수 있습니다. 시작 권한은 서비스를 시작 및 중지할 수 있는 권한을 부여하거나 거부하고, 활성화 권한은 서비스에 연결할 수 있는 권한을 부여하거나 거부합니다.
확인을 클릭하여 대화 상자를 닫습니다.
액세스 권한에서 7-8단계를 반복하여 적절한 사용자 및 그룹에 적절한 권한을 할당합니다.
MMC 스냅인을 닫습니다.
Integration Services 서비스를 다시 시작합니다.
'Install /Setup' 카테고리의 다른 글
| SQL 2008:: 삭제 레지스터리 (0) | 2010.08.17 |
|---|---|
| Install Tip (0) | 2010.06.04 |
| SQL Server 수동 시작 (1) | 2010.01.22 |
SQL Server Replication Error - The specified LSN for repldone log scan occurs before the current start of replication in the log
원본 :
http://www.mssqltips.com/sqlservertip/3288/sql-server-replication-error--the-specified-lsn-for-repldone-log-scan-occurs-before-the-current-start-of-replication-in-the-log/?utm_source=dailynewsletter&utm_medium=email&utm_content=headline&utm_campaign=20140815
Problem
When working with SQL Server Replication there are times when you may get critical errors related to the Log Reader Agent. One of these errors is "The specified LSN [xxx] for repldone log scan occurs before the current start of replication in the log [xxx]". In this tip I will show how to deal with this type of error.
Solution
I'll give recommendations on how to fix the replication error and here is an actual error message as an example to help us analyze the issue:
The specified LSN {00000023:000000f8:0003} for repldone log scan occurs before the current
start of replication in the log {00000023:000000f9:0005}.
Below we can see what this error looks like using the Replication Monitor within SQL Server Management Studio.
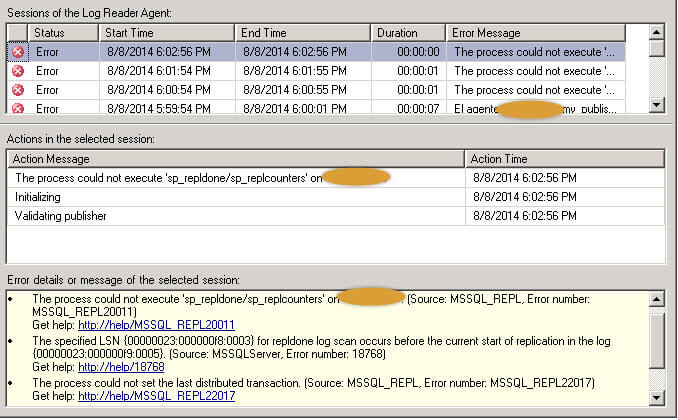
Note: these errors can be found in the Log Reader Agent history and also using SQL Server's Replication Monitor.
The Log Reader Agent is an executable that continuously reads the Transaction Log of the database configured for transactional replication and copies the transactions marked for replication from the Transaction Log into the msrepl_transactions table in the Distribution database. It is important to know that when the Log Reader Agent starts it first verifies that the last transaction in the msrepl_transactions table in the Distribution database matches the Last Replicated Transaction in the Transaction Log for the published database (that is, the current start of replication). When this does not occur, an error will appear like shown above. Note that the msrepl_transactions table is a critical table and it must not be modified manually, because the Log Reader agent works based on the data in this table. If some entries are deleted or modified incorrectly then we will get many replication errors and one of them is what we are talking about in this tip.
Analyzing the SQL Server Replication Issue
As per our error message for this example, we can execute DBCC OPENTRAN on the published database to find more details about the opened and active replication transaction:
Replicated Transaction Information:
Oldest distributed LSN : (35:249:5)
Oldest non-distributed LSN : (35:251:1)
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
Note that DBCC OPENTRAN gives us the LSN value in Decimal format and we need to convert the LSN from Decimal to Hexadecimal for further analysis. Below I have converted the values from decimal to hexadecimal.
Oldest distributed LSN : (35:249:5) --> 00000023:000000f9:0005 (must match last row in msrepl_transactions table)
Oldest non-distributed LSN : (35:251:1) --> 00000023:000000fb:0001 (oldest LSN in the transaction log)
If we analyze the output again,
The specified LSN {00000023:000000f8:0003} for repldone log scan occurs before the current
start of replication in the log {00000023:000000f9:0005}.
we can confirm that the LogReader agent is expecting to find LSN 000000f8 of VLF 00000023 which is currently the last entry in the msrepl_transactions table, but this is not the correct Last Replicated Transaction LSN. For SQL Server the correct Last Replicated Transaction LSN is 000000f9.
Note also that the oldest LSN in the Transaction Log is 000000fb of the same VLF 00000023. This means that the Log Reader is trying to start reading on LSN 000000f8 which is before the current start of replication in the log with LSN 000000f9.
You might be thinking about just moving the Log Reader to start at 000000f9 to fix this error? The problem is that we do not know exactly how many transactions there are from 000000f8 to 000000f9, so if we move the Log Reader Agent pointer forward then we could miss some transactions and create data inconsistency issues.
Fixing the SQL Server Replication Issue
If you decide to move the Log Reader you can do it by using sp_repldone to mark 00000023:000000f9:0005 as the last replicated transaction, so you can skip and move forward. This can be done as shown below. Here we are using the values from the error message: {00000023:000000f9:0005} or 00000023000000f90005. We then flush and restart.
exec sp_repldone @xactid = x00000023000000f90005 , @xact_segno = x00000023000000f90005 GO -- releasing article cache... exec sp_replflush GO --Resetting LogReader to retrieve next transaction... --LogReader Agent will start up and begin replicating transactions.... exec sp_replrestart
With the above code, the error will disappear and the LogReader agent should continue running without error. If you want to know more about the LogReader Agent, you can review the links at the end of this tip.
Note: You should use sp_repldone only to troubleshoot specific internal replication errors and not use this as a regular way to fix issues. In the case where you have more continuous errors like above it is better to recreate the replication publication again by dropping and then recreating.
Use sp_repldone with extreme caution because if you use the incorrect LSN you may skip valid transactions from the replication queue and you can create data inconsistency issues at the subscribers.
Fixing Error After a SQL Server Database Restore
Sometimes this type of error can appear after you restore a database that has publications. In this case an error similar to this will appear:
The specified LSN {00000000:00000000:0000} for repldone log scan occurs before the current
start of replication in the log {00000023:000000f9:0005}.
You can see that Log Reader wants to start reading at LSN {00000000:00000000:0000} and it is because the msrepl_transactions table is empty. In this specific case you also can run sp_repldone to skip all false pending transactions in the msrepl_transactions table and move forward, so the LogReader ignores the incorrect starting point and can continue working.
exec sp_repldone @xactid=NULL, @xact_segno=NULL, @numtrans=0, @time=0, @reset=1
Note that we use @reset=1 to mark all replicated transactions in the Transaction Log as distributed.
'Replication' 카테고리의 다른 글
| 복제::스키마 옵션 (0) | 2012.01.30 |
|---|---|
| 복제::숨겨진 저장프로시저 확인 (0) | 2011.01.16 |
| 복제::LOB DataType 제한 (0) | 2010.06.04 |
| 복제::#5 구현&삭제 스크립트 (0) | 2010.06.04 |
SQL 2005 이상
http://www.madeira.co.il/troubleshooting-tempdb-space-usage/ 발췌
Tempdb is a critical resource in SQL Server. It is used internally by the database engine for many operations, and it might consume a lot of disk space. In the past two weeks I encountered 3 different scenarios in which tempdb has grown very large, so I decided to write about troubleshooting such scenarios.
Before I describe the methods for troubleshooting tempdb space usage, let’s begin with an overview of the types of objects that consume space in tempdb. There are 3 types of objects stored in tempdb:
- User Objects
- Internal Objects
- Version Stores
A user object can be a temporary table, a table variable or a table returned by a table-valued function. It can also be a regular table created in the tempdb database. A common misconception is that table variables (@) do not consume space in tempdb, as opposed to temporary tables (#), because they are only stored in memory. This is not true. But there are two important differences between temporary tables and table variables, when it comes to space usage:
1. Indexes and statistics on temporary tables also consume space in tempdb, while indexes and statistics on table variables don’t. This is simply because you cannot create indexes or statistics on table variables.
2. The scope of a temporary table is the session in which it has been created, while the scope of a table variable is the batch in which it has been created. This means that a temporary table consumes space in tempdb as long as the session is still open (or until the table is explicitly dropped), while a table variable’s space in tempdb is deallocated as soon as the batch is ended.
Internal objects are created and managed by SQL Server internally. Their data or metadata cannot be accessed. Here are some examples of internal objects in tempdb:
- Query Intermediate Results for Hash Operations
- Sort Intermediate Results
- Contents of LOB Data Types
- Query Result of a Static Cursor
Unlike user objects, operations on internal objects in tempdb are not logged, since they do not need to be rolled back. But internal objects do consume space in tempdb. Each internal object occupies at least 9
pages (one IAM page and 8 data pages). tempdb can grow substantially due to internal objects when queries that process large amounts of data are executed on the instance, depending on the nature of the queries.
Version stores are used for storing row versions generated by transactions in any database on the instance. The row versions are required by features such as snapshot isolation, after triggers and online index build. Only when row versioning is required, the row versions will be stored in tempdb.
As long as there are row versions to be stored, a new version store is created in tempdb approximately every minute. These version stores are similar to internal objects in many ways. Their data and metadata cannot be accessed, and operations on them are not logged. The difference is, of-course, the data that is stored in them.
When a transaction that needs to store row versions begins, it stores its row versions in the current version store (the one that has been created in the last minute). This transaction will continue to store row versions in the same version store as long as it’s running, even if it will run for 10 minutes. So the size of each version store is determined by the number and duration of transactions that began in the relevant minute, and also by the amount of data modified by those transactions.
Version stores that are not needed anymore are deallocated periodically by a background process. This process deallocates complete version stores, not individual row versions. So, in some cases, it might take a while till some version store is deallocated.
There are two types of version stores. One type is used to store row versions for tables that undergo online index build operations. The second type is used for all other scenarios.
-- 실행되는 구문의 temp page allocate
select task.session_id, ses.host_name, ses.login_name,ses.login_time
,(task.internal_alloc + task.oject_alloc) -(task.internal_dealloc +task.oject_delloc) as used
,task.internal_alloc,task.internal_dealloc,task.oject_alloc,task.oject_delloc
,object_name(qt.objectid, qt.dbid) as 'spname'
,req.cpu_time,req.logical_reads,req.reads, req.writes
,substring(qt.text,req.statement_start_offset/2,
(case when req.statement_end_offset = -1
then len(convert(nvarchar(max), qt.text)) * 2
else req.statement_end_offset end - req.statement_start_offset)/2) as query
,req.statement_start_offset, req.statement_end_offset, req.plan_handle, req.sql_handle
from
(
select session_id, request_id
,sum (internal_objects_alloc_page_count) /128 as internal_alloc
,sum (internal_objects_dealloc_page_count)/128 as internal_dealloc
,sum (user_objects_alloc_page_count ) /128 as oject_alloc
,sum (user_objects_dealloc_page_count ) /128 as oject_delloc
from sys.dm_db_task_space_usage with (nolock)
group by session_id, request_id
) as task
inner join sys.dm_exec_requests as req with (nolock)
on task.session_id = req.session_id and task.request_id = req.request_id
inner join sys.dm_exec_sessions as ses with(nolock) on req.session_id = ses.session_id
cross apply sys.dm_exec_sql_text(sql_handle) as qt
order by (task.internal_alloc + task.oject_alloc) -(task.internal_dealloc +task.oject_delloc) desc, cpu_time desc
테이블 변수도 tempdb의 공간을 사용한다고 되어 있습니다. 알아 두세요
--tempdb 사용 Size
select sum( unallocated_extent_page_count
+ user_object_reserved_page_count
+ internal_object_reserved_page_count
+ mixed_extent_page_count
+ version_store_reserved_page_count ) /128 as [TotalTempDBSizeInMB]
, sum(unallocated_extent_page_count) /128 as [FreeTempDBSpaceInMB]
from sys.dm_db_file_space_usage
select
db_name(su.database_id) dbname
,mf.physical_name
,(su.unallocated_extent_page_count
+ su.user_object_reserved_page_count
+ su.internal_object_reserved_page_count
+ su.mixed_extent_page_count
+ su.version_store_reserved_page_count ) /128 as total_size_mb
,su.user_object_reserved_page_count / 128 user_object_size_mb
,su.internal_object_reserved_page_count /128 as internal_object_size_mb
,su.unallocated_extent_page_count/ 128 unallocated_extent_size_mb
from sys.dm_db_file_space_usage as su
join sys.master_files as mf on mf.database_id = su.database_id and mf.file_id = su.file_id
'Monitoring' 카테고리의 다른 글
| 실행 쿼리 memory 사용 대기 정보 (1) | 2012.08.13 |
|---|---|
| 대랑 I/O 사용 세션 쿼리 (0) | 2012.08.13 |
| TEMPDB의 페이지 사용량 측정 (0) | 2012.08.13 |
| 모니터링::Index 생성 & Rebuild 진행 상황 (0) | 2011.12.06 |
펌 : http://blogs.the451group.com/information_management/2013/02/04/updated-database-lanscape-map-february-2013/
Update 된 Database Map 입니다.

'Common Admin' 카테고리의 다른 글
| 성능 Counter - Disk Transfers/sec (Disk Reads/sec, Disk Writes/sec) (1) | 2015.12.28 |
|---|---|
| TokenAndPermUserStore (0) | 2015.05.18 |
| SQL Server tempdb 복구 (0) | 2013.01.08 |
| tablediff 유틸리티 (0) | 2012.11.01 |
detach 한 DB를 다른 서버에서 attach 하면 log 백업 바로 가능 한가?
답은 가능 하다 이다.
DB의 마지막 Last_LSN 정보를 정상적으로 알고 처리 한다.
즉, FULL 백업은 하지 않아도 된다.
backup_start_date
backup_finish_date
first_lsn
last_lsn
2013-03-13 16:29
2013-03-13 16:29
23000000005400000
23000000008200000
2013-03-13 16:29
2013-03-13 16:29
23000000005400000
23000000009000000
2013-03-13 16:32
2013-03-13 16:32
23000000009000000
23000000010700000
2013-03-13 16:33
2013-03-13 16:33
23000000010700000
23000000011200000
다른
서버로 attach
2013-03-13 16:45
2013-03-13 16:45
23000000011200000
23000000017700000
'Backup/Restory' 카테고리의 다른 글
| BACKUP compression (0) | 2010.06.04 |
|---|---|
| Admin::Recovery Model (0) | 2010.06.04 |
| 백업성공보고 (0) | 2010.06.03 |
| All DB 백업 (0) | 2010.06.03 |
업무를 하다보면 월 두번째, 세번째 특정 요일을 구해야 하는 경우가 있다.
여기서는 금요일로 하겠다.
declare @dt_getdate date
set @dt_getdate = '2013-03-13'
select @dt_getdate
select DATEADD(wk, DATEDIFF(wk,0, dateadd(dd,6-datepart(day,@dt_getdate),@dt_getdate) ), 4)
위 쿼리는 해당 월의 첫번째 금요일을 알려준다,
허나 2013년 3월의 경우 3/1일이 금요일 이긴 하지만 주로 처리 되면 2월의 마지막 주가 되서 3/1일이 아닌
3/8일이 결과가 나온다.
이럴 경우, 두번째 금요일, 세번째 금요일도 원하는 결과가 아니다.
그래서 , 구하려고 하는 달의 다음날 첫 일의 금요일을 찾아 거꾸로 찾는 방법을 택했다.
-- 다음달의 첫번째 날짜를 구하자.
declare @dt_getdate date , @dt_next_month_day date
set @dt_getdate = '2013-02-13'
--set @dt_getdate = dateadd(mm,1,@dt_getdate)
select @dt_getdate
set @dt_next_month_day = CONVERT(VARCHAR(10),DATEADD(dd,-(DAY(DATEADD(mm,1,@dt_getdate))-1),DATEADD(mm,1,@dt_getdate)),121)
select @dt_next_month_day
if Datepart(dw, @dt_next_month_day )= 6
select dateadd(dd,-21,@dt_next_month_day) as '둘째 금', dateadd(dd,-14, @dt_next_month_day) as '셋째 금'
else
select dateadd(dd,-21,dateadd(dd, 6- datepart(dw,@dt_next_month_day ), @dt_next_month_day) ) as '둘째 금',
dateadd(dd,-14,dateadd(dd, 6- datepart(dw,@dt_next_month_day ), @dt_next_month_day) ) as '셋째 금'

'T-SQL' 카테고리의 다른 글
| master SP 생성 -> DB별 view 인식 하게 하기 (0) | 2015.04.01 |
|---|---|
| T-SQL::동적 PIVOT 생성 (3) | 2012.11.02 |
| Function to return a range of dats - 날짜 범위 펑션 (0) | 2012.11.01 |
| T-SQL:: 인덱스 압축 예상 Size (0) | 2012.07.26 |
tempdb 복구
tempdb는 SQL Server에서 정렬, GROUP BY를 사용한 집계, 커서 사용, 임시테이블 및 테
이블변수 사용, 일부 JOIN, SORT_IN_TEMPDB 옵션을 사용한 인덱스 생성, 데이터베이스
의 복구 작업 등에서 사용됩니다. 따라서, 손상 시에는 이와 같은 작업들을 진행할 수 없게
됩니다. tempdb의 손상 시 tempdb를 사용하는 작업은 다음과 같이 913 오류를 발생하며
정상적으로 실행되지 않습니다.
또한, tempdb의 size나 경로를 잘못 설정하여 SQL Server가 시작 시 정상 상태가 아닐 경우도 문제가 발생합니다.
tempdb가 주의 대상일 경우 재 시작 만으로 복구되기도 하지만 아닐 경우도 있습니다.
이럴 경우 최소 로그 이면서 tempdb를 skip 하면서 SQL 서버를 수동으로 시작 해야 합니다.
1. 명령 프론트를 실행하고 SQL Sever 실행된 경로로 이동 한다.
2. tempdb 없이 실행하는 추적플래그 –T3609, 자동으로 실행하는 저장 프로시저를 실행하지 않게 하는 플래그 –T4022로 실행합니다.
3. 경우에 따라 최소 옵션인 –f도 포함합니다. , -m : 단일 사용자 모드
실행하는 명령창은 닫지 말고 그대로 둡니다.
Sqlservr.exe –c –f –m –T3609 –T4022
net start MSSQLSERVER /f /c /m /T 3609 /T4022
4. 경로가 잘 못 되었거나, size가 잘 못 되었을 경우 정보를 Alter database 구문을 통해 수정 합니다.
5. SQL Server 2000 이하의 경우 주의 대상을 정상 상태로 변경 하기 위해서
exec sp_resetstatus ‘tempdb’
명령으로 강제로 복원 할 수도 있습니다.
6. 3번의 실행 명령창에 Ctrl + c를 입력한 다음 “Y” 키를 눌러 SQL Server를 종료후 정상적으로 서비스를 기동 합니다.
7. tempdb에 문제가 없는지 확인 합니다.
'Common Admin' 카테고리의 다른 글
| TokenAndPermUserStore (0) | 2015.05.18 |
|---|---|
| Database Landscape map – February 2013 (0) | 2013.03.13 |
| tablediff 유틸리티 (0) | 2012.11.01 |
| Admin::2000용 TEST DB 생성. (0) | 2011.10.05 |
Partitioned Tables, Indexes and Execution Plans: a Cautionary Tale23 October 2012
SQL Server 2005 에서 Partitioned Tables 기능이 나왔을때 우리는 기대를 했다.
많은 데이터를 최소한의 locking 으로 Switch 할 수 있을 것이라고, 그리고 쿼리 성능에도 좋은 영향을 미칠 것이라고..
그러나 무료 제공하는 점심 같은것은 없었다. 파티션 되면서 더 많은 저장 공간이 요구되었다.
Storage space increase
파티션을에 대한 계획을 할 때 꼭, 클러스터된 인덱스 key가 포함되어야 합니다. 불행이도 파티션되어야 하는 key가 고유한 인덱스가 아닐 수도 있습니다. 이 해결책은 클러스터된 인덱스에 포함시키는 방법입니다.
non-clustered index는 clustered index 의 key point를 가지고 있습니다. 파티션 테이블은 일반적으로 대형이며, 클러스터 된 인덱스 키에 새 열을 추가하면, non-clustered index의 모든 레코드가 증가됩니다.
예를 들어 500,000,000 테이블에 clustered index 에 8 byte 날짜 열이 추가된다고 가정해 보면
500000000 * 8/1024/1024/1024 = 3.75GB 인덱스당 저장공간이 증가됩니다.
이 수치는 스토리지 오버헤드의 저장공간은 포함되지 않습니다.
이 증가된 용량은 백업 시간, 복구 시간도 증가하게되며, 색인 유지 보수 비용도 증가합니다.
불행하게도 이 작업에 대한 해결책은 존재하지 않습니다.
데이터가 13개월을 가지고 있고 12개월 데이터를 select 를 매년 초에 해야 한다고 한다면 당연히 날짜 Data가 파티션 key에 존재해야 하며, 파티션이 슬라이등 되어야 합니다. 그러나, 오히려 작은 단위로 데이터를 삭제 하는것이 더 효율 적입니다.
기존 테이블을 파티션 하기 위해 clustered index에 열을 추가하는 것도 쉽지 않습니다.
그나마 대안으로는 indentity 컬럼이 있을 경우 해당 월이 시작되는 값을 알아내어, 그 key로 파티션 하는 것입니다.
저장 공간 뿐 아니라, 실행계획에 대해서도 살펴봐야 합니다.
Suboptimal execution plans
파티셔닝을 구현할 때, 물리적 데이터 레이아웃이 변경됨으로 퀴러의 실행 계획이 예기치 못한 결과를 나타낼 수도 있습니다.
그림 참고)
Listing 1 shows the structure of the Orders table, with clustered index.
GO
CREATE TABLE dbo.Orders
(
Id INT NOT NULL ,
OrderDate DATETIME NOT NULL ,
DateModified DATETIME NOT NULL ,
Placeholder CHAR(500)
NOT NULL
CONSTRAINT Def_Data_Placeholder DEFAULT 'Placeholder',
);
GO
CREATE UNIQUE CLUSTERED INDEX IDX_Orders_Id
ON dbo.Orders(ID);
GO
Listing 1: The Orders table structure
Listing 2 inserts 524,288 records into the Orders table and creates a non-clustered index.
WITH N1 ( C )
AS ( SELECT 0
UNION ALL
SELECT 0
)-- 2 rows
, N2 ( C )
AS ( SELECT 0
FROM N1 AS T1
CROSS JOIN N1 AS T2
)-- 4 rows
, N3 ( C )
AS ( SELECT 0
FROM N2 AS T1
CROSS JOIN N2 AS T2
)-- 16 rows
, N4 ( C )
AS ( SELECT 0
FROM N3 AS T1
CROSS JOIN N3 AS T2
)-- 256 rows
, N5 ( C )
AS ( SELECT 0
FROM N4 AS T1
CROSS JOIN N4 AS T2
)-- 65,536 rows
, N6 ( C )
AS ( SELECT 0
FROM N5 AS T1
CROSS JOIN N2 AS T2
CROSS JOIN N1 AS T3
)-- 524,288 rows
, IDs ( ID )
AS ( SELECT ROW_NUMBER() OVER ( ORDER BY ( SELECT NULL
) )
FROM N6
)
INSERT INTO dbo.Orders
( ID ,
OrderDate ,
DateModified
)
SELECT ID ,
DATEADD(second, 35 * ID, @StartDate) ,
CASE WHEN ID % 10 = 0
THEN DATEADD(second,
24 * 60 * 60 * ( ID % 31 ) + 11200 + ID
% 59 + 35 * ID, @StartDate)
ELSE DATEADD(second, 35 * ID, @StartDate)
END
FROM IDs;
GO
CREATE UNIQUE NONCLUSTERED INDEX IDX_Orders_DateModified_Id
ON dbo.Orders(DateModified, Id);
SELECT TOP 100
ID ,
OrderDate ,
DateModified ,
PlaceHolder
FROM dbo.Orders
WHERE DateModified > @LastDateModified
ORDER BY DateModified ,
Id;
Listing 3: Query that selects the batch of the records


DROP INDEX IDX_Orders_Id ON dbo.Orders;
GO
CREATE PARTITION FUNCTION pfOrders(DATETIME)
AS RANGE RIGHT FOR VALUES
('2012-02-01', '2012-03-01',
'2012-04-01','2012-05-01','2012-06-01',
'2012-07-01','2012-08-01');
GO
CREATE PARTITION SCHEME psOrders
AS PARTITION pfOrders
ALL TO ([primary]);
GO
CREATE UNIQUE CLUSTERED INDEX IDX_Orders_OrderDate_Id
ON dbo.Orders(OrderDate,ID)
ON psOrders(OrderDate);
GO
CREATE UNIQUE INDEX IDX_Data_DateModified_Id_OrderDate
ON dbo.Orders(DateModified, ID, OrderDate)
ON psOrders(OrderDate);
GO
Listing 4: Table partitioning code



Figure 6 shows how SQL Server actually processes the query.

파티션되지 않은 테이블은 top 100 조회하면 처음 나오는 값 기준으로 정렬없이 100개를 가져오니까 비교적 효율적.
만약 파티셔닝을 구현 한다며 key가 변경되고 정렬되어 있는 것 중에 모두 데이터를 찾아야 한다. 즉, 파티션이 8개 되었다고 한다면 100의 데이터가 있는지 보다 파티션 별로 데이터를 찾아서 정렬한다.
물론, 힌트로 고정할 수도 있지만 예상치 않은 결과 이다.
Fixing the problem
그림 참고)
SELECT TOP 100
ID ,
OrderDate ,
DateModified ,
PlaceHolder
FROM dbo.Orders
WHERE DateModified > @LastDateModified
AND $partition.pfOrders(OrderDate) = 5
ORDER BY DateModified ,
ID;

간혹 이상할 경우 많이 사용하는 방법인데 파티션 범위를 확인하고 지정 파티션을 정해 주는 것이다. (파티션 된 테이블을 조건에 해당하는 데이터를 삭제 할 경우 top 10개로.. 등. 이관시 꼭 실행계획을 확인하고 해당 파티션만 찾게 범위를 지정해 줘야 하는 것이 이 이유이다. )
그러려면 파티션의 총 수를 알아야 한다.. ( ys.partition_range_values)
@BoundaryCount INT;
SELECT @BoundaryCount = MAX(boundary_id) + 1
FROM sys.partition_functions pf
JOIN sys.partition_range_values prf
ON pf.function_id = prf.function_id
WHERE pf.name = 'pfOrders';
WITH Boundaries ( boundary_id )
AS ( SELECT 1
UNION ALL
SELECT boundary_id + 1
FROM Boundaries
WHERE boundary_id < @BoundaryCount
)
SELECT part.ID ,
part.OrderDate ,
part.DateModified ,
$partition.pfOrders(part.OrderDate) AS [Partition Number]
FROM Boundaries b
CROSS APPLY ( SELECT TOP 100
ID ,
OrderDate ,
DateModified
FROM dbo.Orders
WHERE DateModified > @LastDateModified
AND $Partition.pfOrders(OrderDate) =
b.boundary_id
ORDER BY DateModified ,
ID
) part;
Listing 8: Implementation of Step 1 of "Ideal execution plan"
Dealing with Cardinality Estimation Errors
윗 부분 처럼하면 경계값 에러가 발생할 수 있다. 개선책.
tempdb를 사용한다.
(
ID INT NOT NULL
PRIMARY KEY
);
DECLARE @LastDateModified DATETIME = '2012-06-25' ,
@BoundaryCount INT;
SELECT @BoundaryCount = MAX(boundary_id) + 1
FROM sys.partition_functions pf
JOIN sys.partition_range_values prf
ON pf.function_id = prf.function_id
WHERE pf.name = 'pfOrders';
WITH Boundaries ( boundary_id )
AS ( SELECT 1
UNION ALL
SELECT boundary_id + 1
FROM Boundaries
WHERE boundary_id < @BoundaryCount
)
INSERT INTO #T
( ID
)
SELECT boundary_id
FROM Boundaries;
WITH Top100 ( ID, OrderDate, DateModified )
AS ( SELECT TOP 100
part.ID ,
part.OrderDate ,
part.DateModified
FROM #T b
CROSS APPLY ( SELECT TOP 100
ID ,
OrderDate ,
DateModified
FROM dbo.Orders
WHERE DateModified >
@LastDateModified
AND $Partition.pfOrders(OrderDate) =
b.id
ORDER BY DateModified ,
ID
) part
ORDER BY part.DateModified ,
part.ID
)
SELECT d.Id ,
d.OrderDate ,
d.DateModified ,
d.Placeholder
FROM dbo.Orders d
JOIN Top100 t ON d.Id = t.Id
AND d.OrderDate = t.OrderDate
ORDER BY d.DateModified ,
d.ID;
DROP TABLE #T;
Listing 10: Using a temporary table in order to improve cardinality estimation

Figure 11: Using temporary table in order to improve cardinality estimation
Hardcoding the number of Partitions
그림 참고)
WITH Boundaries ( boundary_id )
AS ( SELECT V.v
FROM ( VALUES ( 1), ( 2), ( 3), ( 4), ( 5), ( 6), ( 7),
( 8) ) AS V ( v )
),
Top100 ( ID, OrderDate, DateModified )
AS ( SELECT TOP 100
part.ID ,
part.OrderDate ,
part.DateModified
FROM Boundaries b
CROSS APPLY ( SELECT TOP 100
ID ,
OrderDate ,
DateModified
FROM dbo.Orders
WHERE DateModified >
@LastDateModified
AND $Partition.pfOrders(OrderDate) =
b.boundary_id
ORDER BY DateModified ,
ID
) part
ORDER BY part.DateModified ,
part.ID
)
SELECT d.Id ,
d.OrderDate ,
d.DateModified ,
d.Placeholder
FROM dbo.Orders d
JOIN Top100 t ON d.Id = t.Id
AND d.OrderDate = t.OrderDate
ORDER BY d.DateModified ,
d.ID;
Listing 11: Hardcode static number of partitions in order to improve cardinality estimation

Figure 12: Hardcode static number of partitions in order to improve cardinality estimation
윗 부분 처럼 하면 사용하고자 하는 메모리보다 더 많은 메모리를 사용하게 된다. ( 일부 파티션에 데이터가 없는 경우)
파티션 수를 하드 코딩 한다. -> 파티션을 추가 되었을 경우 수정해야 한다. 이론.. ㅜㅜ;;
Summary
테이블 파티셔닝은 다양한 디자인과 성능 문제에 도움을 줄 수 있는 훌륭한 기능이지만, 또한 문제 집합을 만 들 수도 있습니다.
clustered index에 파티션 열을 추가하면 저장공간 및 인덱스 유지 보수 비용이 증가합니다.
다른 물리적 데이터 레이아웃 변경이 될 경우 실행 계획이 변화 될 수 있습니다. 이런 부작용이 있다는것을 알고 적용하기 전에 꼭 Test 해봐야 합니다.
==> 그래서 처음 설계 부터 파티션 하게 하거나, 자주 조회되지 않은 과거 테이블이나 이력 테이블을 적용하고 있고
또는 키를 변경하기 보다는 기존 key의 범위로 파티션 key를 사용하고 있다, 물론 조회되는 중요 sp들의 조건 절을 확인한다.
기존 테이블을 파티셔닝 하는것은 항상 조심해야 한다.
'Peformance Tuning' 카테고리의 다른 글
| Index IGNORE_DUP_KEY 옵션 TEST (1) | 2015.09.14 |
|---|---|
| query plan의 실행 옵션 보기 (0) | 2012.01.29 |
| Dynamic Management Views (0) | 2012.01.22 |
| Hash Join 제약. (0) | 2011.10.10 |
원문 : http://www.mssqltips.com/sqlservertip/2783/script-to-create-dynamic-pivot-queries-in-sql-server/
동적으로 PIVOT을 만들 수 있는 방법입니다.
아직도 case 문이 익숙하긴 하지만, 가끔은 오히려 더 복잡해지는 case 문 때문에 PIVOT을 사용해야 한다고 느껴질 때가 있습니다.
아직 PIVOT 익숙하지는 않은데 하다보니 컬럼 고정이 되서 불편한 점이 있는데 이 방법으로 사용하면 좋을 것 같네요.
PIVOT 은 행 형태의 반환을 열로 만들어 주는 것입니다.
아래로 테스트할 데이터를 생성 합니다.
CREATE TABLE dbo.Products
(
ProductID INT PRIMARY KEY,
Name NVARCHAR(255) NOT NULL UNIQUE
/* other columns */
);
INSERT dbo.Products VALUES
(1, N'foo'),
(2, N'bar'),
(3, N'kin');
CREATE TABLE dbo.OrderDetails
(
OrderID INT,
ProductID INT NOT NULL
FOREIGN KEY REFERENCES dbo.Products(ProductID),
Quantity INT
/* other columns */
);
INSERT dbo.OrderDetails VALUES
(1, 1, 1),
(1, 2, 2),
(2, 1, 1),
(3, 3, 1);
SELECT p.Name, Quantity = SUM(o.Quantity)
FROM dbo.Products AS p
INNER JOIN dbo.OrderDetails AS o
ON p.ProductID = o.ProductID
GROUP BY p.Name;
결과는 아래 처럼 행으로 나 옵니다. 그러나 열로 표시하고 싶어요. 하면 PIVOT 처리 합니다.

SELECT p.[foo], p.[bar], p.[kin]
FROM
(
SELECT p.Name, o.Quantity
FROM dbo.Products AS p
INNER JOIN dbo.OrderDetails AS o
ON p.ProductID = o.ProductID
) AS j
PIVOT
(
SUM(Quantity) FOR Name IN ([foo],[bar],[kin])
) AS p;
원하는 결과가 나왔습니다. ~

다른 데이터를 추가 해 보죠.
INSERT dbo.Products SELECT 4, N'blat';
INSERT dbo.OrderDetails SELECT 4,4,5;
그리고 나서 다시 윗 쿼리를 실행 해 보면 결과는 동일하게 3개의 데이터의 집계만 나타납니다.
당연한 결과 입니다. 지금 추가된 blat는 보이지 않습니다. PIVOT는 집계해서 보여줄 컬럼을 명시해야 하기 때문입니다. 쿼리를 그럼 고쳐야 하는데 좀 더 쉽게 동적으로 할 수 있게 아래는 도와 줍니다.
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX);
SET @columns = N'';
SELECT @columns += N', p.' + QUOTENAME(Name) -- += 는 컬럼을 합쳐서 한 문자로 만들어 주죠.
FROM (SELECT p.Name FROM dbo.Products AS p
INNER JOIN dbo.OrderDetails AS o
ON p.ProductID = o.ProductID
GROUP BY p.Name) AS x;
print @columns
SET @sql = N'
SELECT ' + STUFF(@columns, 1, 2, '') + '
FROM
(
SELECT p.Name, o.Quantity
FROM dbo.Products AS p
INNER JOIN dbo.OrderDetails AS o
ON p.ProductID = o.ProductID
) AS j
PIVOT
(
SUM(Quantity) FOR Name IN ('
+ STUFF(REPLACE(@columns, ', p.[', ',['), 1, 1, '')
+ ')
) AS p;';
PRINT @sql;
EXEC sp_executesql @sql;
-- @sql의 문은 컬럼을 만들어서 PIVOT 를 생성해 줍니다.
/*결과)
SELECT p.[foo], p.[bar], p.[kin], p.[blat]
FROM
(
SELECT p.Name, o.Quantity
FROM dbo.Products AS p
INNER JOIN dbo.OrderDetails AS o
ON p.ProductID = o.ProductID
) AS j
PIVOT
(
SUM(Quantity) FOR Name IN ([foo],[bar],[kin],[blat])
) AS p;
*/
원하는 결과가 도출.

'T-SQL' 카테고리의 다른 글
| master SP 생성 -> DB별 view 인식 하게 하기 (0) | 2015.04.01 |
|---|---|
| 월에 두번째/세번째 요일 구하기. (0) | 2013.03.13 |
| Function to return a range of dats - 날짜 범위 펑션 (0) | 2012.11.01 |
| T-SQL:: 인덱스 압축 예상 Size (0) | 2012.07.26 |
SQL SERVER 2005 이상
와 어찌 하다가 이제서야 알게됨.
TABLEDIFF 유틸.. 이름에서도 알 수 있 듯이 테이블 차이점 찾기 유틸입니다.
복제되어 있는 곳에서 데이터 불일치 문제를 해결하는데 유용하며,
batch file일 이용해서 사용 할 수 있습니다.
-
복제 게시자 역할을 하는 MicrosoftSQL Server 인스턴스에 있는 원본 테이블과 복제 구독자 역할을 하는 하나 이상의 SQL Server 인스턴스에 있는 대상 테이블을 행 단위로 비교할 수 있습니다.
-
행 개수와 스키마만 비교하여 비교 작업을 빨리 수행할 수 있습니다.
-
열 수준에서 비교할 수 있습니다.
-
대상 서버의 불일치를 해결하는 Transact-SQL 스크립트를 생성하여 원본 테이블과 대상 테이블을 일치시킬 수 있습니다.
-
결과를 출력 파일이나 대상 데이터베이스의 테이블에 기록할 수 있습니다.
데이터 형식이 sql_variant 인 열은 지원하지 않는다.
도움말 :http://msdn.microsoft.com/ko-kr/library/ms162843(v=SQL.100).aspx
- 사용권한
-o 또는 -f 옵션을 사용하려면 지정된 파일 디렉터리 위치에 대한 쓰기 권한이 있어야 함.
-et 옵션을 사용하려면 db_owner 고정 데이터베이스 역할의 멤버이거나 적어도 구독 데이터베이스에 대한 CREATE TABLE 권한과 대상 서버의 대상 소유자 스키마에 대한 ALTER 권한이 있어야 함
-dt 옵션을 사용하려면 db_owner 고정 데이터베이스 역할의 멤버이거나 적어도 대상 서버의 대상 소유자 스키마에 대한 ALTER 권한이 있어야 함.
- 사용 법
"C:\Program Files\Microsoft SQL Server\90\COM\tablediff.exe" -sourceserver server1 -sourcedatabase test -sourcetable table1 -destinationserver server1 -destinationdatabase test -destinationtable table2
- 결과
Microsoft (R) SQL Server Replication Diff Tool
Copyright (C) 1988-2005 Microsoft Corporation. All rights reserved.
User-specified agent parameter values:
-sourceserver server1
-sourcedatabase test
-sourcetable table1
-destinationserver server2
-destinationdatabase test
-destinationtable table2
Table [test].[dbo].[table1] on server1 and Table [test].[dbo].[table2] on server1 have 3 differences.
Err PersonID
Mismatch 1
Dest. Only 2
Src. Only 3
The requested operation took 0.4375 seconds.
'Common Admin' 카테고리의 다른 글
| Database Landscape map – February 2013 (0) | 2013.03.13 |
|---|---|
| SQL Server tempdb 복구 (0) | 2013.01.08 |
| Admin::2000용 TEST DB 생성. (0) | 2011.10.05 |
| Admin:: SQL Server 에러로 다른 서버에서 Rebuilding 처리 (0) | 2011.08.14 |
http://www.mssqltips.com/sqlservertip/2800/sql-server-function-to-return-a-range-of-dates/By: Albert Hetzel 정리
SQL SERVER 2005 이상
일자별 sum, max 등의 집계 쿼리를 할 때 일자의 범위가 모두 포함되기어 표현되어지기를 원할 때가 있다.
그러나 실제 데이터는 일자 범위에 데이터가 없을 수도 있고 있을 수도 있다. 이럴때 어떻게 해야 할까??
물론, row_number 함수를 사용하여 corss join을 사용하면 가능하다. 그러나 이런 쿼리는 복잡하고 원하는 결과를 나타내지 않을 수도 있다.
여기서는 테이블 함수를 사용하는 방법으로 해결 합니다.
이 함수는 CTE를 사용하여 반복적으로 날짜를 반환 해 준다. (@Increment 옵션에 따라서)
DROP FUNCTION [DateRange]
GO
CREATE FUNCTION [dbo].[DateRange]
(
@Increment CHAR(1), -- 일/주/달 여부
@StartDate DATETIME, -- 시작 날짜
@EndDate DATETIME -- 종료 날짜
)
RETURNS
@SelectedRange TABLE
(IndividualDate DATETIME)
AS
BEGIN
;WITH cteRange (DateRange) AS (
SELECT @StartDate
UNION ALL
SELECT
CASE
WHEN @Increment = 'd' THEN DATEADD(dd, 1, DateRange)
WHEN @Increment = 'w' THEN DATEADD(ww, 1, DateRange)
WHEN @Increment = 'm' THEN DATEADD(mm, 1, DateRange)
END
FROM cteRange
WHERE DateRange <=
CASE
WHEN @Increment = 'd' THEN DATEADD(dd, -1, @EndDate)
WHEN @Increment = 'w' THEN DATEADD(ww, -1, @EndDate)
WHEN @Increment = 'm' THEN DATEADD(mm, -1, @EndDate)
END)
INSERT INTO @SelectedRange (IndividualDate)
SELECT DateRange
FROM cteRange
OPTION (MAXRECURSION 3660);
RETURN
END
GO
실행을 해 보면 아래와 같다.
SELECT IndividualDate FROM DateRange('d', '2012-11-01', '2012-11-10')
SELECT IndividualDate FROM DateRange('w', '2012-11-01', '2012-11-10')
SELECT IndividualDate FROM DateRange('m', '2012-11-01', '2013-01-10')

자 그럼 이제 집계하고자 하는 데이터와 조인해서 사용해 보자
임시 테이블을 사용해서 해당 날짜의 제품이 판매된 정보를 입력 하였다. 아래 데이터에서 봤을 경우 11/1 ~ 11/10 사이에
매출은 이틀만 발생 하였다.
CREATE TABLE #temp (orderDate DATETIME, orderInfo VARCHAR(50))
INSERT INTO #temp VALUES ('2012-11-01','2 copies of SQL Server 2008')
INSERT INTO #temp VALUES ('2012-11-05','6 copies of SQL Server 2008 R2')
INSERT INTO #temp VALUES ('2012-11-05','10 copies of SQL Server 2012')
SELECT a.IndividualDate , b.orderDate, b.orderInfo
FROM DateRange('d', '2012-11-01', '2012-11-10') as a
LEFT JOIN #temp as b on a.IndividualDate = b.orderDate
결과에서 알 수 있듯이, 매출이 발생하지 않은 일자도 나열 되어 표시된다. 이럴 경우 매출이 없는 일자를 찾기도 쉽다.


'T-SQL' 카테고리의 다른 글
| 월에 두번째/세번째 요일 구하기. (0) | 2013.03.13 |
|---|---|
| T-SQL::동적 PIVOT 생성 (3) | 2012.11.02 |
| T-SQL:: 인덱스 압축 예상 Size (0) | 2012.07.26 |
| TSQL::월별 누적 건수를 구하기. (0) | 2012.01.29 |
문제
SQL Server Reporting Services 2008 (SSRS 2008) 시작하고 일정 시간 지나면 점점 늦어지는 현상을 볼 수 있음.
해결책
1. SSRS Configuration 의 Recycle Time 변경
2. Memory Pressure
SSRS Configuration
- XML 구성 파일이 존재한다. Recycle Time (재활용 시간 ??) 은 마지막 으로 SSRS가 사용자가 수동으로 다시 시작 되었을 때 기준으로 분 이다.
Recycle Time이 발생하면 SSRS내의 유휴 자원이 해지 된다.
기본으로는 720분 또는 12시간으로 구성 되어 있다.
C:\Program Files\Microsoft SQL Server\MSRS10.MSSQLSERVER\Reporting Services\ReportServer
rsreportserver.config
‹Service›
…
…
‹RecycleTime›720‹/RecycleTime›
…
…
720분으로 셋팅되어 있기 때문에 초기 사용자는 느린 시작으로 연결이 되고
720분 다시 발생 할 때까지 잘 사용되다가 720분이 되면 다시 유휴 자원이 이루어지어 느린 응답이 발생한다.
재활용 시간은 마지막 날짜를 사용하는 시간 SSRS은 그 참조 점으로 다시 시작했다.
SSRS은 구성 파일에서 재활용 시간을 예약 ,현재 날짜와 시간을 그 다시 시작 시간을 사용한다.
재활용 시간이 720분로 설정되어 있으며 SSRS이 12:00에 720분 후 다음 자정 0시에서 다시 시작하는 경우
예를 들어, SSRS 자체를 재활용합니다. 이후 720분 후 자정에 0시의 SSRS 다시 재활용되며, 등등.
SSRS의 재활용은 자원을 확보하기 위해 무기한 계속됩니다.
SSRS 재활용 시간에 가장 좋은 시간은 각 회사의 사용에 따라 달라진다. 그것은 SSRS가 많이 활용되지 않는 경우 몇 가지 분석을 수행하는 것이 가장 좋을 수 있습니다.
기본적으로는 12 시간마다 재활용,하지만 요청이 처리되는가보고 있으면 더 기간 동안 SSRS를 운영 중 상태로
유지하기 더 좋을 수 있다.
여러 지사를 가지고 있는데 시간대가 틀리게 사용되어 진다면, 720분은 많이 사용하는 시간에 유휴자원이 되어 초기화 될 수 있다.
SQL Server Reporting Services Memory Pressure
조직의 크기에 따라 SSRS를 독립적으로 사용하지 않고 SQL Server나 다른 응용프로그램과 같은 컴퓨터에 공용으로 사용할 수 있다.
이때, 다른 응용 프로그램에서 메모리가 필요하면 Windows는 유휴 상태가 된 메모리를 빼앗는 작업을 하는데 그 피해자의 하나로서 SSRS를 결정한다.
이 문제의 간단한 해결책은 더 많은 RAM을 추가 하는 것이지만, 대부분 가능한 상황이 아니다.
이 방법을 해결하는 두번 째 방법은 Memory Pressure 관리할 수 있는 SSRS에 최소한 메모리를 조정하는 것이다.
혹은 예약된 보고서를 작성하는것이다.
최소한의 메모리를 조정하는 옵션은 "WorkingSetMinimu" 에 대한 SSRS 구성 파일에 추가하는 것이다.
‹Service›
…
…
‹WorkingSetMinimum›250000‹/WorkingSetMinimum›
…
…

이 작업은 다른 응용 프로그램에 영향을 미칠 수 있음을 주의해야 하며, 메모리 소비수준을 꼭 모니터링 해서 결정해야 한다.
오히려 이 수치가 높을 경우 응용프로그램 및 서버 자체가 느리거나 응답 하지 않을 수도 있다.
'Reporting Service' 카테고리의 다른 글
| 배포 메일링 주소 변경 (0) | 2014.09.02 |
|---|---|
| 공유 데이터 원본 Overwrite (0) | 2009.08.04 |
SQL Server 2005 이상
1. 서버 수준 권한
--======================
--1. 서버수준의권한
--======================
select spr.name, spr.type, spr.type_desc,
spr.default_database_name, spr.default_language_name,
spm.class_desc, spm.permission_name, spm.state_desc,
suser_name(srm.role_principal_id) as server_role_name
from sys.server_principals as spr with (nolock)
inner join sys.server_permissions as spm (nolock) on spm.grantee_principal_id = spr.principal_id
left join sys.server_role_members as srm with (nolocK) on spr.name = suser_name(srm.member_principal_id)
where spr.type in ('S','U','K', 'G') --C, R
--and spr.name = '' -- 유저로하나찾기
order by spr.type,spr.name
-- 유저하나의role member 보기
select suser_name(role_principal_id), suser_name(member_principal_id)
from sys.server_role_members where member_principal_id = suser_id('')
2. DB 수준 권한
use testdb
go
EXEC sp_dbfixedrolepermission;
GO
SELECT * FROM sys.fn_builtin_permissions(DEFAULT)
SELECT * FROM sys.fn_builtin_permissions(DEFAULT)
WHERE permission_name = 'SELECT';
-- 사용자 role 고정 role 권한 정보
SELECT DPR.NAME, IS_FIXED_ROLE
--,DPR.TYPE_DESC
--,USER_NAME(DRM.MEMBER_PRINCIPAL_ID) AS USER_NAME
,USER_NAME(DRM.ROLE_PRINCIPAL_ID) AS ROLE_NAME
FROM SYS.DATABASE_PRINCIPALS AS DPR WITH (NOLOCK)
LEFT JOIN SYS.DATABASE_ROLE_MEMBERS DRM WITH (NOLOCK) ON DPR.PRINCIPAL_ID = DRM.MEMBER_PRINCIPAL_ID
WHERE DPR.TYPE ='R'
ORDER BY DPR.NAME
-- role별 사용자 정보
SELECT USER_NAME(DRM.ROLE_PRINCIPAL_ID) AS 'ROLE_NAME'
,USER_NAME(DRM.MEMBER_PRINCIPAL_ID) AS 'LOGIN'
FROM SYS.DATABASE_ROLE_MEMBERS AS DRM WITH(NOLOCK)
JOIN SYS.DATABASE_PRINCIPALS AS DPM WITH(NOLOCK) ON DRM.ROLE_PRINCIPAL_ID = DPM.PRINCIPAL_ID
WHERE DPM.TYPE ='R'
AND DPM.IS_FIXED_ROLE = 0
ORDER BY USER_NAME(DRM.ROLE_PRINCIPAL_ID)
select dpr.name, dpr.type_desc, dpr.default_schema_name,
user_name(drm.member_principal_id) as user_name,
user_name(drm.role_principal_id) as role_name
from sys.database_principals as dpr with (nolock)
inner join sys.database_role_members drm with (nolock) on dpr.principal_id = drm.member_principal_id
--where name = '' -- role이나 유저정보
order by 1,2
-- DB별로 사용자와 ROLE이 어떤 객체의 권한을 가지고 있는지 여부
select dpr.name, dpr.type_desc, dpr.default_schema_name,
dpm.class_desc,
case when dpm.major_id = 0 then 'ALL' else obj.name end as object_name,
dpm.permission_name, dpm.state_desc
from sys.database_principals as dpr with (nolock)
left join sys.database_permissions as dpm with (nolock) on dpr.principal_id = dpm.grantee_principal_id
left outer join sys.all_objects as obj with (nolock) on dpm.major_id = obj.object_id
--where dpr.name = '' -- 하나의유저나 혹은 role 이름이나 모두 가능
order by dpr.type, dpr.name
-- 사용자 role member 상세 보기
select dpr.name, dpr.type_desc, dpr.default_schema_name,
user_name(drm.member_principal_id) as user_name,
user_name(drm.role_principal_id) as role_name,
case when dpm.major_id = 0 then 'ALL' else OBJECT_NAME(dpm.major_id) end as object_name,
dpm.permission_name, dpm.state_desc
from sys.database_principals as dpr with (nolock)
left join sys.database_permissions as dpm with (nolock) on dpr.principal_id = dpm.grantee_principal_id
inner join sys.database_role_members drm with (nolock) on dpr.principal_id = drm.member_principal_id
--left outer join sys.all_objects as obj with (nolock) on dpm.major_id = obj.object_id
-- 안해도 된다.
--where dpr.type = 'R' -- DATABASE_ROLE
--and dpr.name = ''
/* S = SQL 사용자
U = Windows 사용자
G = Windows 그룹
A = 응용 프로그램 역할
R = 데이터베이스 역할
C = 인증서로 매핑된 사용자
K = 비대칭 키로 매핑된 사용자 */
ORDER BY dpr.name, 5
3. 권한 제거 Script 생성
-- object 권한 제거
select schema_name(obj.schema_id) as schema1,
case when dpm.major_id = 0 then 'ALL' else OBJECT_NAME(dpm.major_id) end as object_name,
dpm.state_desc,
('REVOKE ' + dpm.permission_name COLLATE Korean_Wansung_CI_AS
+ ' ON OBJECT::' + schema_name(obj.schema_id)+ '.' + OBJECT_NAME(dpm.major_id) + ' FROM ' + dpr.name )
from sys.database_principals as dpr with (nolock)
inner join sys.database_permissions as dpm with (nolock) on dpr.principal_id = dpm.grantee_principal_id
inner join sys.objects as obj with (nolock) on dpm.major_id = obj.object_id
where dpr.name ='' and dpm.permission_name = 'EXECUTE'
SQL Server 2000 이상
--==========================
-- 2000용
--==========================
select name, createdate, updatedate, dbname from master..syslogins
where name != 'sa' and name not like '#%' order by name;
exec sp_helpsrvrolemember
exec sp_helprolemember
-- 객체정보
select distinct table_catalog, grantee, table_name , PRIVILEGE_TYPE
--('REVOKE ' + PRIVILEGE_TYPE + ' ON ' + table_name+ ' FROM ' + grantee )
from INFORMATION_SCHEMA.COLUMN_PRIVILEGES
select grantee, table_catalog, table_schema, table_name, privilege_type, is_grantable
from INFORMATION_SCHEMA.TABLE_PRIVILEGES
where grantee = ''
select specific_catalog, specific_name, * from INFORMATION_SCHEMA.PARAMETERS
 Prev
Prev

